Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Updated on 2020-03-11 21:43:52
Paper (ICML-2015):http://proceedings.mlr.press/v37/xuc15.pdf
Theano (Offical Implementation): https://github.com/kelvinxu/arctic-captions
TensorFlow: https://github.com/DeepRNN/image_captioning
PyTorch:https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Image-Captioning
1. Background and Motivation:
为了获得更好的特征表达来做 Image Captioning 任务,作者提出利用 Attention model 来增强最终的性能。具体来说提出两种模型,即 “Hard Attention” 和 “Soft Attention”。
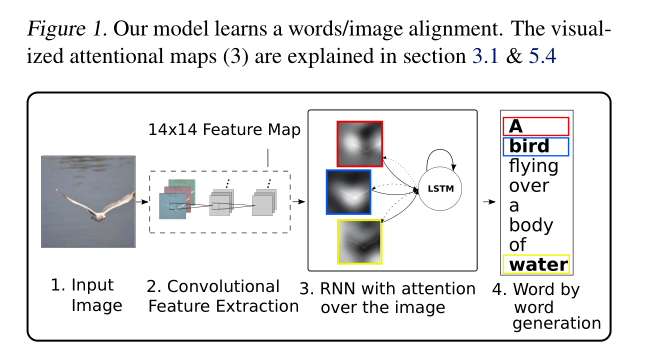

2. Image Caption Generation with Attention Mechanism
2.1. Model Details:
2.1.1. Encoder: Convolutional Features
作者这里用的是 CNN 来提取图像的特征,该特征提取器产生 L vectors,每一个是一个 D-维 的表示,对应的是图像的一个部分:
![]()
为了得到 2-D image 的部分和特征向量之间的对应,作者从底层的卷积层上提取 features,而不是 fc layer。这样就可以使得 decoder 选择性的注意到图像的特定区域。
2.1.2. Decoder: LSTM network
本文采用 LSTM 来输出句子,即每一个时刻输出一个单词。利用 $T_{s, t}$ 来表示一个简单的仿射变换:
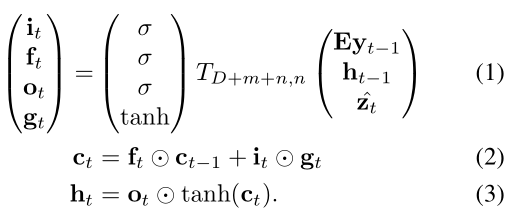
其中,等号左边的几个符号分别表示 input,forget,memory,output and hidden state。向量 z 是 context vector,捕获和特定输入位置相关的视觉信息。E 是 embedding matrix。公式 1-3 中的 context vector z 是输入图像在时刻 t 的相关 part 的动态表示。作者用一种机制从 annotation vector ai 来计算 z,对应了在不同图像位置上提取出来的特征。对于每一个位置 i,该机制都会生成一个正的权重 $alpha_i$,可以看做是下一个时刻应该关注的区域。该权重是通过注意力模型计算得到的:
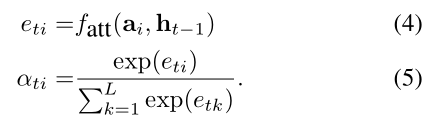
一旦得到了权重,context vector z 就可以按照如下的方式进行处理:
![]()
其中,外边的函数返回的是 single vector,具体细节会在后续小节进行介绍。
LSTM 起始的记忆状态和隐层状态可以通过如下的方式进行计算:

在这个工作中,给定 LSTM 的状态,context vector 以及 之前的单词,输出单词的概率可以通过如下的方式进行计算:
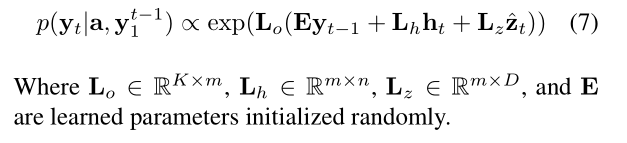
3. Learning Stochastic "Hard" vs Deterministic "Soft" Attention:
3.1. Stochastic "Hard" Attention:
作者在产生第 t 个单词的时候,模型决定聚焦注意力的位置变量记为 $s_t$。$s_{t, i}$ 是一个 one-hot variable 的指示器,如果 第 i 个位置被用于提取特征,就会被设置为 1。通过将 attention locations 看做是中间的隐层变量,作者用参数 {$alpha_i$} 来赋予一个 multinoulli distribution,将 zt 看做是一个随机变量:
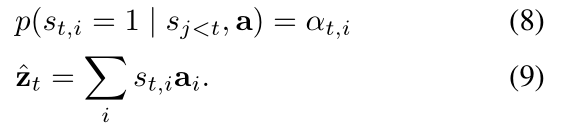
作者定义了一个新的目标函数 Ls:
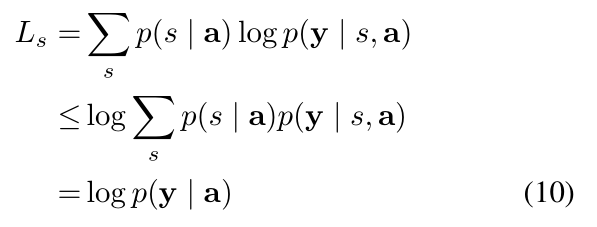
这个目标是一个下界: a variational lower bound on the marginal log-likelihood logp(y|a) of observing the sequence of words y given image features a. 对于模型参数的学习可以直接对 Ls 进行优化:
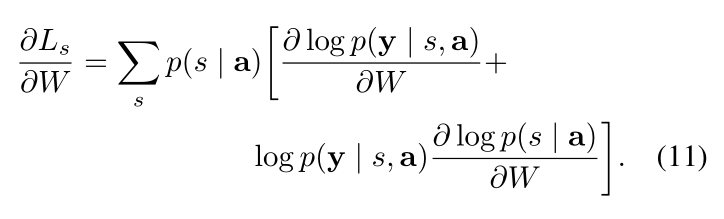
公式 11 表明:梯度的基于蒙特卡洛的采样估计 和 model parameters 是一致的。这个可以通过从 multinouilli distribution 上采样位置 st 来实现:
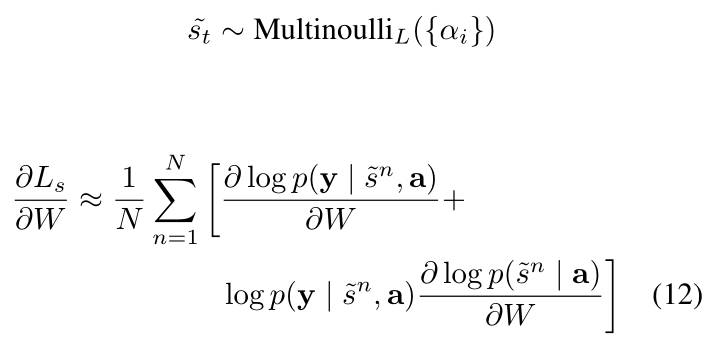
此外,还用到了常用的 trick,即:减去平均的 baseline。通过观察第 k 个 mini-batch,the moving average baseline 可以通过累计之前的 log 似然性来预测:
![]()
为了进一步降低预测的方差,作者也添加了 entropy term。模型最终的学习规则是:
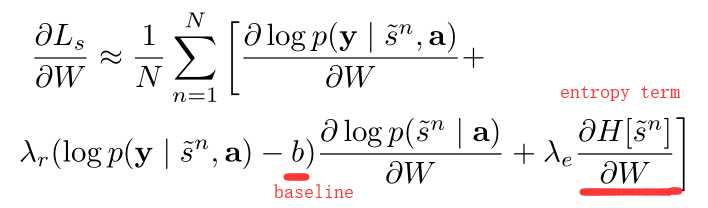
其实这种学习的方法等价于 REINFORCE Learning rule。
3.2. Deterministic "Soft" Attention:
除了上面提到的 hard attention 之外,本文也尝试直接对 context vector z 求期望:

然后构建一个 deterministic attention model,通过计算 soft attention weighted annotation vector。整个模型都是平滑的,可微分的,可以用标准的反向传播算法进行学习。
4. Experimental Results: