第一题(未通过):1128
这道题字符串的长度为1000000000,所以时间复杂度应该在log(n)级别,但我写出来了一个比O(l)还要大的复杂度,自然没通过。
但是这道题我也想不出复杂度更低的算法了。。。
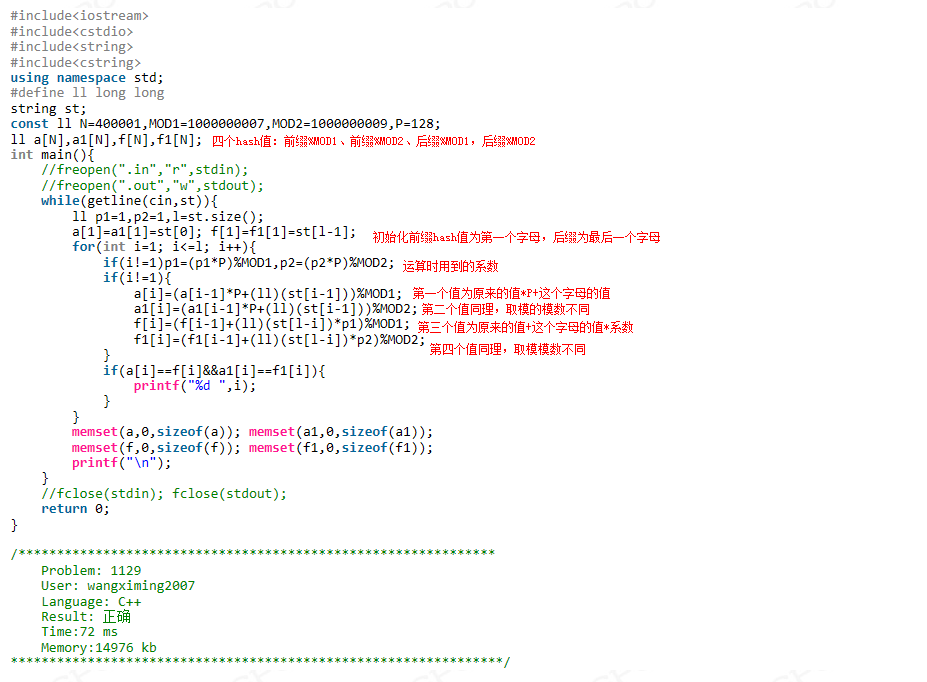
第二题:1129
这道题最朴素的算法就是每轮都计算前i位和后i位的hash值,时间复杂度为O(n2*数据数量)。针对这道题的数据,是1011以上级别的复杂度。
可以加一个优化:由于主串不变,所以每轮只需要计算第i位的hash值,时间复杂度O(n*数据数量),低于107。
另外一个问题是:如何求后缀的hash值?
先推导:设f[i]为长度为i的后缀的hash值,st为字符串,l为st的长度则
f[1]=st[l-1]
f[2]=st[l-1]+st[l-2]P
f[3]=st[l-1]+st[l-2]P+st[l-3]P2
f[4]=st[l-1]+st[l-2]P+st[l-3]P2+st[l-4]P3
……
可以看出,每个f[i]的内容都等于f[i-1]的内容加上st[l-i]Pi-1。而Pi-1则可以在第i次循环中计算(即每个循环中P的值*=进制,i=1时除外)。
思路清楚以后,这道题就很简单了。
AC代码: