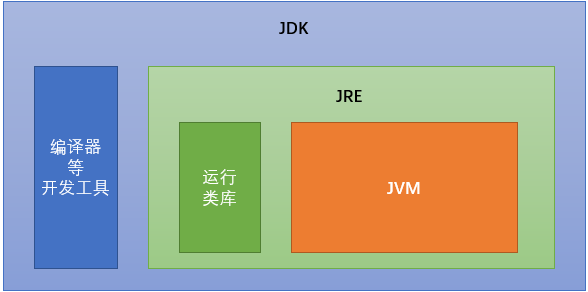
1.JDK、JRE与JVM的关系
2.字节码和机器码的区别
机器码是电脑CPU直接读取运行的机器指令,运行速度最快,但是非常晦涩难懂,也比较难编写,一般从业人员接触不到。
字节码是一种中间状态(中间码)的二进制代码(文件)。需要直译器转译后才能成为机器码。
3.OracleJDK和OpenJDK
查看JDK的版本 java -version
(1) 如果是SUN/OracleJDK, 显示信息为:
[root@localhost ~]# java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
Java HotSpot(TM) 64-Bit Server VM 表明, 此JDK的JVM是Oracle的64位HotSpot虚拟机,运行在Server模式下(虚拟机有Server和Client两种运行模式)
Java(TM) SE Runtime Environment (build 1.8.0_162-b12) 是Java运行时环境(即JRE)的版本信息.
(2) 如果OpenJDK, 显示信息为:
[root@localhost ~]# java -version
openjdk version "1.8.0_144"
OpenJDK Runtime Environment (build 1.8.0_144-b01)
OpenJDK 64-Bit Server VM (build 25.144-b01, mixed mode)
OpenJDK 的来历
Java由SUN公司(Sun Microsystems, 发起于美国斯坦福大学, SUN是Stanford University Network的缩写)发明, 2006年SUN公司将Java开源, 此时的JDK即为OpenJDK.
实际上, Oracle JDK是基于OpenJDK源代码构建的, 因此Oracle JDK和OpenJDK之间没有重大的技术差异。
JVM和Hotspot的关系
JVM是《JVM虚拟机规范》中提出来的规范
Hotspot是使用JVM规范的商用产品,除此之外还有Oracle JRockit、IBM的J9也是JVM产品。
JVM的运行模式
JVM有两种运行模式:Server模式与Client模式。
两种模式的区别在于
Client模式启动速度较快,Server模式启动较慢;
但是启动进入稳定期长期运行之后Server模式的程序运行速度比Client要快很多。
因为Server模式启动的JVM采用的是重量级的虚拟机,对程序采用了更多的优化;而Client模式启动的JVM采用的是轻量级的虚拟机。所以Server启动慢,但稳定后速度比Client远远要快。
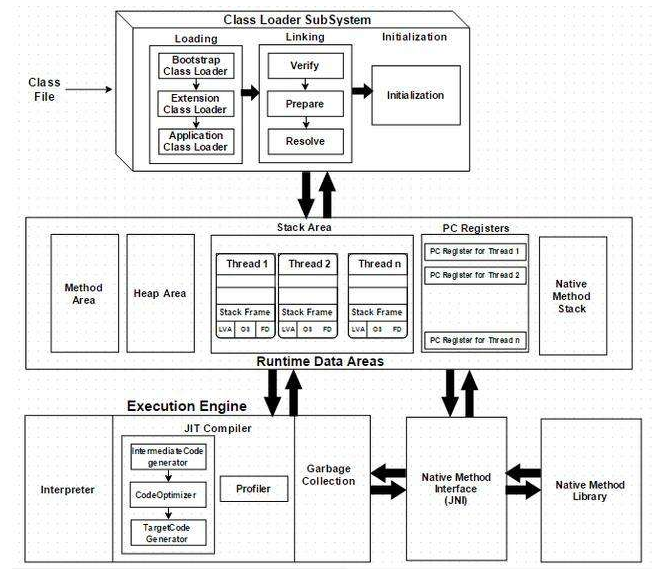
4.JVM架构理解
5.JVM程序执行流程
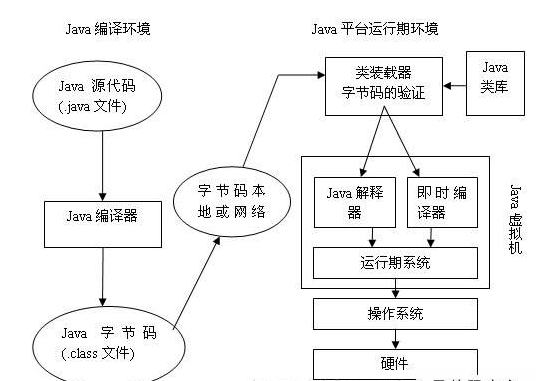
编译器和解释器的协调工作流程:
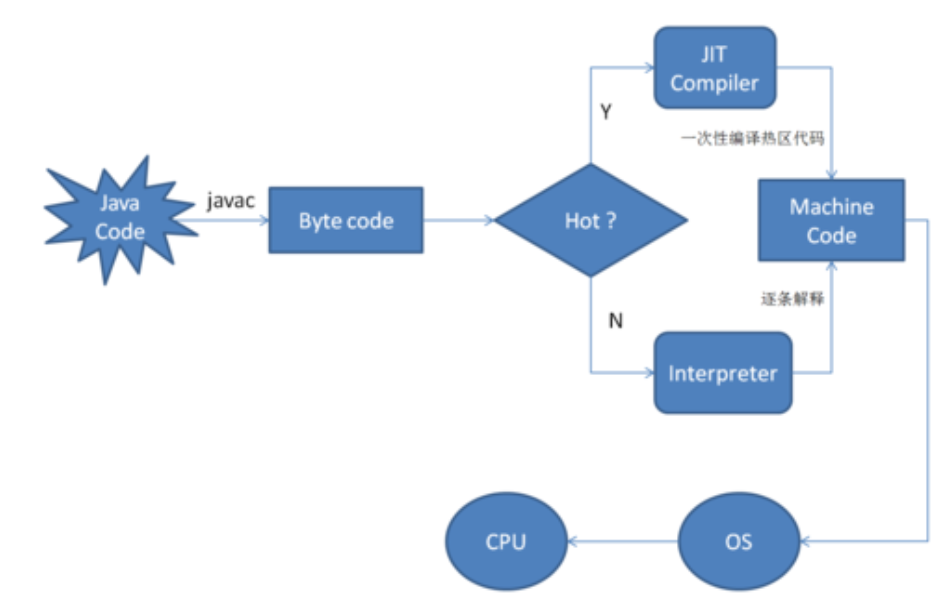
在部分商用虚拟机中(如HotSpot),Java程序最初是通过解释器(Interpreter)进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”。
为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器称为即时编译器(Just In Time Compiler,下文统称JIT编译器)。
如无特殊说明,我们提到的编译器、即时编译器都是指Hotspot虚拟机内的即时编译器,虚拟机也是特指HotSpot虚拟机。
6.哪些程序代码会被即时编译
程序中的代码只有是热点代码时,才会编译为本地代码,那么什么是热点代码呢?
运行过程中会被即时编译器编译的“热点代码”有两类:
1. 被多次调用的方法。
2. 被多次执行的循环体。
两种情况,编译器都是以整个方法作为编译对象。 这种编译方法因为编译发生在方法执行过程之中,因此形象的称之为栈上替换(On Stack Replacement,OSR),即方法栈帧还在栈上,方法就被替换了。
热点检测方式
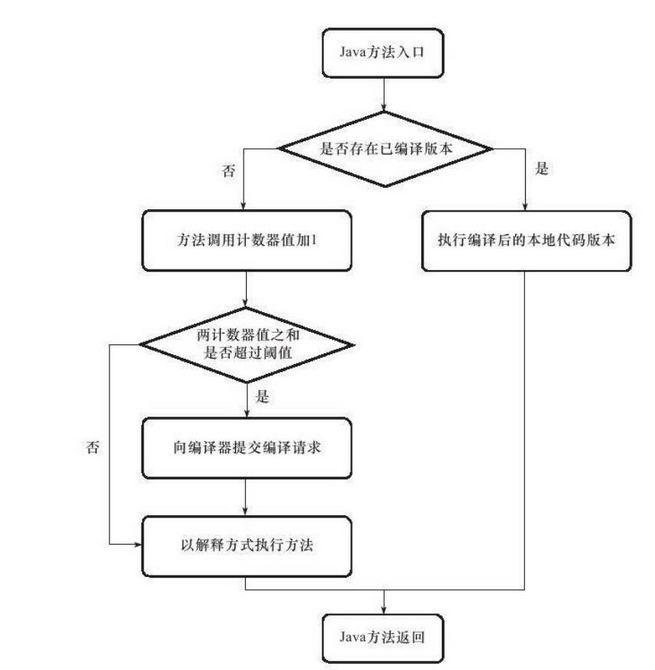
在HotSpot虚拟机中使用的是基于计数器的热点探测方法,因此它为每个方法准备了两个计数器:方法调用计数器和回边计数器。
在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的阈值,当计数器超过阈值溢出了,就会触发JIT编译。
为什么要使用解释器与编译器并存的架构
解释器与编译器特点
当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。
在程序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以获取更高的执行效率。
当程序运行环境中内存资源限制较大(如部分嵌入式系统中),可以使用解释器执行节约内存,反之可以使用编译执行来提升效率。
HotSpot虚拟机中内置了两个即时编译器:Client Complier和Server Complier,简称为C1、C2编译器,分别用在客户端和服务端。
目前主流的HotSpot虚拟机中默认是采用解释器与其中一个编译器直接配合的方式工作。
HotSpot虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式,用户也可以使用“-client”或“-server”参数去强制指定虚拟机运行在Client模式或Server模式。
用Client Complier获取更高的编译速度,用Server Complier 来获取更好的编译质量。
7.JIT优化
1.公共子表达式的消除
公共子表达式消除是一个普遍应用于各种编译器的经典优化技术,他的含义是:如果一个表达式E已经计算过了,并且从先前的计算到现在E中所有变量的值都没有发生变化,那么E的这次出现就成为了公共子表达式。
对于这种表达式,没有必要花时间再对他进行计算,只需要直接用前面计算过的表达式结果代替E就可以了。
2.方法内联
在使用JIT进行即时编译时,将方法调用直接使用方法体中的代码进行替换,这就是方法内联,减少了方法调用过程中压栈与入栈的开销。
同时为之后的一些优化手段提供条件。如果JVM监测到一些小方法被频繁的执行,它会把方法的调用替换成方法体本身。
3.逃逸分析
逃逸分析(Escape Analysis)是目前Java虚拟机中比较前沿的优化技术。
这是一种可以有效减少Java 程序中同步负载和内存堆分配压力的跨函数全局数据流分析算法。
通过逃逸分析,Java Hotspot编译器能够分析出一个新的对象的引用的使用范围从而决定是否要将这个对象分配到堆上。
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。
逃逸分析包括:
全局变量赋值逃逸
方法返回值逃逸
实例引用发生逃逸
线程逃逸:赋值给类变量或可以在其他线程中访问的实例变量.
使用方法逃逸的案例进行分析:
public static StringBuffer craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}
StringBuffffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffffer有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。
甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
使用逃逸分析,编译器可以对代码做如下优化:
一、同步省略。如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同步。
二、将堆分配转化为栈分配。如果一个对象在子程序中被分配,要使指向该对象的指针永远不会逃逸,对象可能是栈分配的候选,而不是堆分配。
三、分离对象或标量替换。
有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象的部分(或全部)可以不存储在内存,而是存储在CPU寄存器中。
在Java代码运行时,通过JVM参数可指定是否开启逃逸分析,
-XX:+DoEscapeAnalysis : 表示开启逃逸分析
-XX:-DoEscapeAnalysis : 表示关闭逃逸分析
从jdk 1.7开始已经默认开始逃逸分析,如需关闭,需要指定 -XX:-DoEscapeAnalysis
对象的栈上内存分配
我们知道,在一般情况下,对象和数组元素的内存分配是在堆内存上进行的。
但是随着JIT编译器的日渐成熟,很多优化使这种分配策略并不绝对。
JIT编译器就可以在编译期间根据逃逸分析的结果,来决定是否可以将对象的内存分配从堆转化为栈。
看下面的例子:
package com.arrays;
public class T7 {
private static void A(){
User user=new User();
}
public static void main(String[] args) throws Exception{
Long startTime=System.nanoTime();
for (int i=0;i<1000000;i++){
A();
}
Long endTime=System.nanoTime();
System.out.println((endTime-startTime)/1000000);
System.in.read();
}
static class User{}
}
使用JVM参数
-Xmx4G -Xms4G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
使用jmap 查看堆中内存分配情况
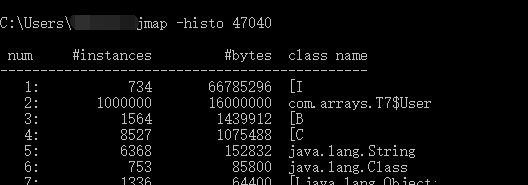
如果没有JIT编译器优化,没有逃逸分析技术,正常情况下就应该是这样的。即所有对象都分配到堆内存中。
开启逃逸分析:
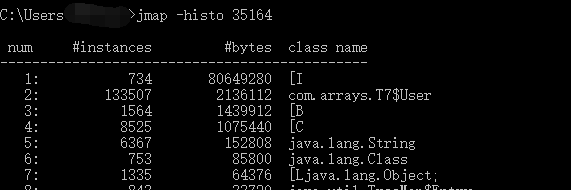
可以看出来 对象在堆中的分配明显减少了。
同步锁消除
同样基于逃逸分析,当加锁的变量不会发生逃逸,是线程私有的完全没有必要加锁。
在JIT编译时期就可以将同步锁去掉,以减少加锁与解锁造成的资源开销。