(1)总结本单元两次作业的架构设计
通过观察这两次作业的类图可以看出,关于UMLModel部分的设计是相同的,第二次相对与第一次多扩展了关于StateMachine和Collaborations部分
第一次类图

第二次类图
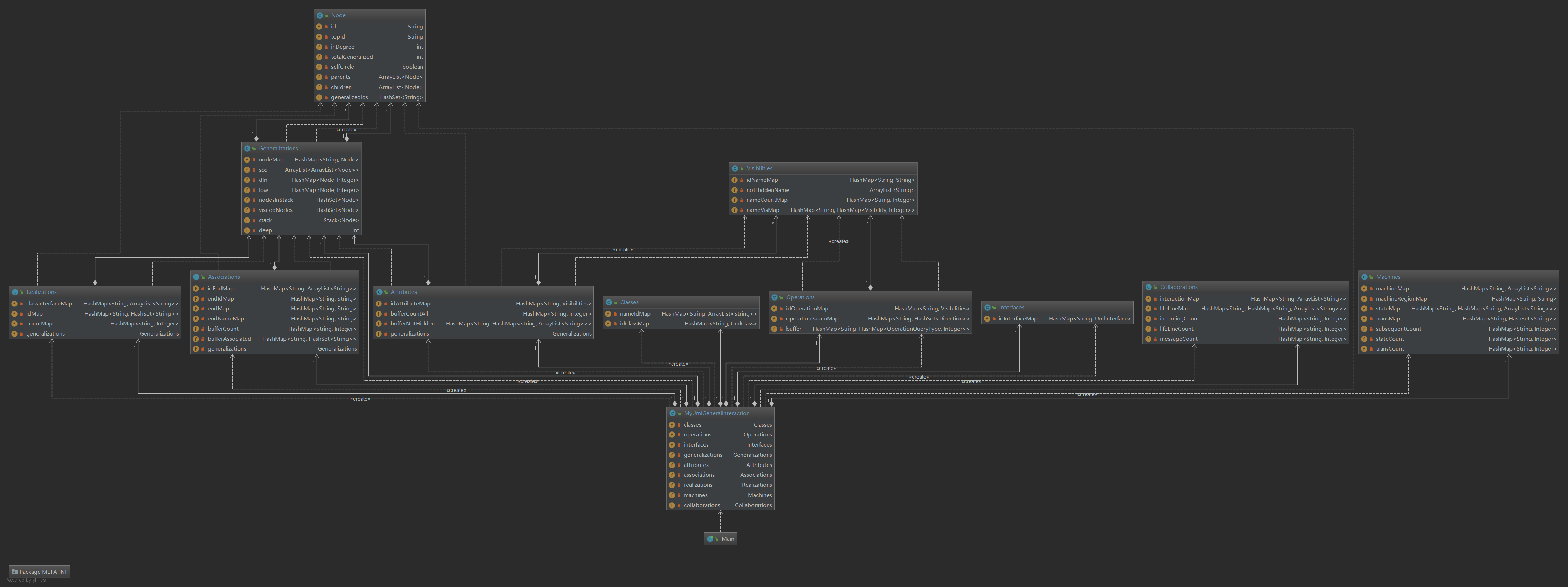
由于UMLModel部分和UMLStateMachine和UMLCollaborations三部分是独立的,所以通过分别介绍这三部分的设计来说明这两次的架构
UMLModel:
- Interfaces,Operations,Attributes,Associations,Realizations,Classes,Generalizations分别对应处理UMLModel中对应的element。
- 由于Operations和Attributes都涉及到对Visibility的查询,所以就单独用一个结构Visibilities对属性的可见性和方法的可见性进行建模。
- 对于涉及到继承关系的查询,需要得到与某个类或者某个接口相关的继承关系,所以这些涉及到继承查询的模块中都在初始化的时候共享了同一个generalizations对象,从而做到不同功能对象的分离。
- 在Generalization中维护了一个树形结构,其中Node是节点,Node中有parents和children等对象,当加入新的继承关系的时候就对应在Node中加入相应的节点,对于类的单继承情况来说,只需要不断向上找就可以得到继承链上所有的类,但是对于接口由于存在多继承,所以需要使用bfs来得到这个接口所继承的所有接口。从类图中可以看出建立了各种关系的hashmap,对于不涉及到继承的查询,直接访问hashmap即可;对于涉及到继承关系的查询,递归向上查询直到有缓存的地方然后退栈并把本层的查询信息填入缓存。另外对于模型合法性检查中的循环继承,计算Generalizations中的强连通分量,如果联通分量的节点数大于2或者存在自环,就加入Exception中的set里面。对于模型检查的重复继承,由于已经检查完循环继承,所以使用拓扑排序的方式计算每个Node继承到的Node,为之后Realization计算重复实现提供方便
UMLStateMachine:
- 类图中可以看出对于查询count,在对应的count上记录即可,对于查询后继状态,使用bfs或者dfs得到访问到的后继的数量,最后将结果进行缓存
UMLCollaboration:
- 与StateMachine类似,同样是建立相应的HashMap然后查询即可
(2)总结自己在四个单元中架构设计及OO方法理解的演进
- 通过抽象出来问题中具有不同功能或者不同属性的类得到类内的方法和属性,然后考虑类之间的协作关系来得到类间的实现和交互关系。比如第一单元的因子,项,表达式;第二单元的电梯,调度器,请求等等。第一单元我感觉还是停留在对类内的设计和完成,但是之后越来越强调类间的关系的设计,怎样设计一个实现简单,逻辑清晰的类间协作关系变成了之后的架构中非常重要的一环,比如第二单元电梯和请求如何交互,电梯和调度器如何交互;第四单元中继承关系和其他的查询关系如何设计,这些应该是比类内设计要求更高的层面。
- 演进:从无对象到有对象,从无设计模式到有设计模式,从对象交互实现困难到清楚的对象交互
(3)总结自己在四个单元中测试理解与实践的演进
- 对于测试,我认为清晰的架构和简单的逻辑是保证正确性的充分条件,大一大二的时候写完代码就开始测试,或者写完就开始debug的方式,其实不如梳理一遍逻辑,或者进行一定的静态检查之后再开始debug;有一些低级的bug,可能通过非常复杂的测试或者长时间的debug才能发现,有时还出现de完一个又出一个的情况,对于这种情况很可能是对架构没有清晰的认识就写代码的结果。由于写之前可能一些细节没有考虑,所以就需要写完对逻辑和正确性进行一定的梳理,这样可以节省一定的时间,提高效率。虽然静态检查可能比较有效,但绝对不能完全依赖静态检查。充分的测试或者JML和Junit测试的方式来检查都是对静态检查的有效补充,得以进一步提高代码的正确性。
- 演进:从不测试到静态检查,从静态检查到辅以Junit,再到之后的自动测试以及JML检查
(4)总结自己的课程收获
- 面向对象的思维
- 多线程的设计与实现
- 会应用一定的设计模式
- UML的使用
- JML的使用
- JUnit的使用
- 注意代码风格
(5)立足于自己的体会给课程提三个具体改进建议
- 我觉得关于多线程部分可以多增加几个章节,但是可以适当减低难度,然后多尝试几种设计模式,因为之后工作中接触到更多的应该是多线程的程序,或者将后几次的作业都涉及成和多线程相关的,这样不至于 后面都在写和多线程无关的,前面的多线程的设计都忘记了。
- 多增加一些可以学习的知识提高获得感,比如课上的知识可以多涉及一些实际应用的东西,或者课下讨论区设计成和 os或者计组那种模式,可以循序渐进有练习的,有章节的学习,每周一个project有时确实很难体会到学到了什么,更多就是在完成project。
- 可以对之后的内容进行预告,在完全不进行预告的情况下我自己很难做到不重构,就算实际工作中应该也会考虑到之后可能出现的情况,但是这些情况不能是自己考虑乱考虑的吧,也要询问客户可能的需求对不对,所以建议课程组对之后的内容进行预告,这样大家也可以提高设计能力,而不是每次都重写