相关的学习资料在这
https://pan.baidu.com/s/1ghgYMob
ymw5
算是学习的总结吧,写的简单点
这里使用的虚拟机做实验
首先需要四台虚拟机,一台master,三台slave
安装好后要求它们和主机两两之间都能ping通
配置名称解析还是叫什么的,就比如说ping 另一个主机名相当于ping它的ip
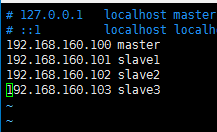
修改 /etc/hosts 文件,像下边这样
然后把上边资料里边的hadoop压缩包和jdk包都搞到四台虚拟机中,可以用xftp,简单
然后把这两个包都解压缩
tar.gz 用命令: tar -zxvf filename.tar.gz
rpm 用命令:rpm -ivh filename.rpm
-后边的字母都有特殊的含义,用--help查看吧
直接安装都在 /usr/local/目录下能找到
然后在 /usr/local/hadoop/etc/hadoop/目录下修改配置文件,hadoop主要的配置文件都在这
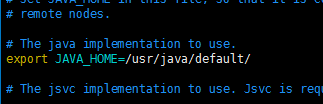
首先修改hadoop-env.sh文件中的java_home路径,如下图
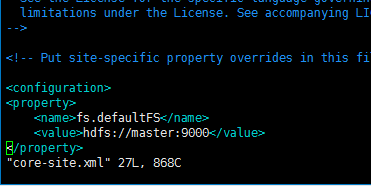
然后修改core-site.xml文件,指定master即namenode所在的机器,如下图
注意四台机器都要进行修改!!!!
向另外一台机器复制文件
scp /usr/local/test.txt root@slave1:/usr/local/test.txt
完成以上配置后,就可以单独在每台机器上启动hadoop了
启动之前,对存储文件进行格式化?
hdfs namenode -format
单独启动hadoop:
hadoop-daemon.sh start namenode 存储文件系统元数据(文件目录结构、分块情况、每块位置、权限等)存在内存中
hadoop-daemon.sh start datanode
下面讲如何配置master到slave的免密ssh登录:
使用start-dfs.sh命令可以启动所有其他机器的hadoop
修改master上的slaves文件,添加datanode信息,如下图

但是这样需要输入很多密码,还会默认启动SecondaryNameNode
进入 /root/.ssh
使用命令 ssh-keygen -t rsa
默认直接回车
会用rsa算法生成私钥id_rsa和公钥id_rsa.pub
使用命令 ssh-copy-id slave1, 会要求输入slave的密码
还要给master拷贝一份
传完后再使用start-dfs.sh,就不用密码了
就是这样