一、背景
上一篇文章(单表数据迁移)用kettle实现了一张表的数据迁移。但实际情况中,数据库会有几百,几千张表,而kettle的表输入和表输出只能选择一张表,我们不可能一个个地填写表名。这时候,我们要考虑 通过循环实现多表的数据迁移。
二、前期准备
与单表数据迁移类似
准备好Oracle和MySQL的库,Oracle到Oracle也可以,转移,只是必须提前在kettle文件夹的lib目录下放入各个数据库的依赖。
电脑可以连接Oracle和MySQL。
下载好kettle,并把Oracle和MySQL的驱动包放在kettle文件夹的lib目录下。
如果第一次使用kettle,建议先看上一篇文章 《单表数据迁移》,上一篇很详细地介绍了新建转换、新建节点、新建数据库连接等问题。
三、批量数据迁移
1.读取需要迁移的表(转换)
方法一:从数据库读取所有表
// mysql查询该数据库的所有表 select table_name from information_schema.tables where table_schema=当前数据库名 and table_type='base table';
点击文件——新建——转换,在左侧的 核心对象 标签下选择 输入 下的 表输入,双击添加到右侧的转换面板,再选择 作业 下的 复制记录到结果 ,双击添加到右侧的转换面板。
接下来配置表输入,双击 表输入 的图标,橙色区域为必填项。如果是两个库表结构一致,导入所有表,可用语句
select table_name from user_tables //
且千万不要在语句后面加分号,会报错。如果只有部分表结构一致且要导入,可用语句来过滤掉源数据库没有的表,否则就会报错。
select table_name from user_tables where table_name!='T_XZQH' and table_name !='BASE_BUSINESS_INFO'
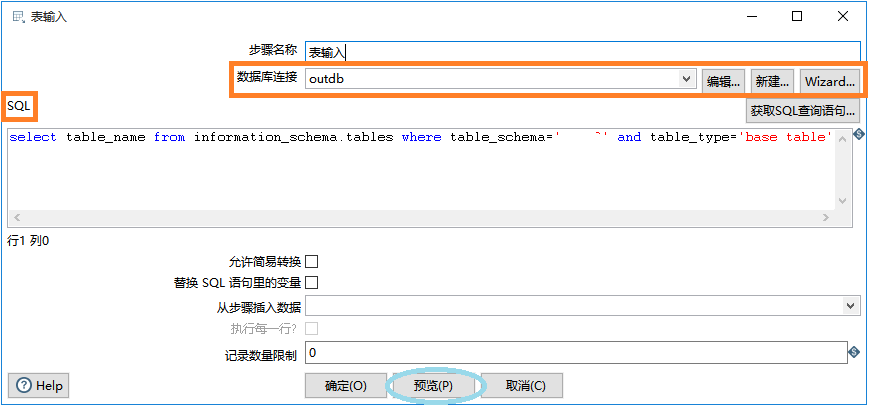
新建mysql的数据库连接,数据库连接的配置参考上一篇文章(注意是mysql的连接),新建好连接,记得测试一下是否连接成功。
SQL语句填写的就是mysql查询所有表的语句,table_schema 为你的mysql数据库名。
配置好点击下方的预览,看一下查出来的表名对不对。
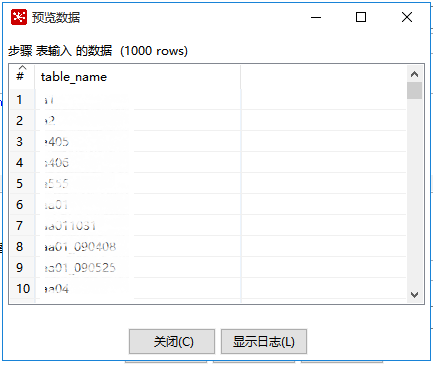
现在已经把mysql中的表名都查出来,最后会根据这些表名查询oracle的数据库。
复制记录到结果 不需要配置。
保存这个转为“tables in mysql.ktr”。
方法二:从Excel读取所需的表
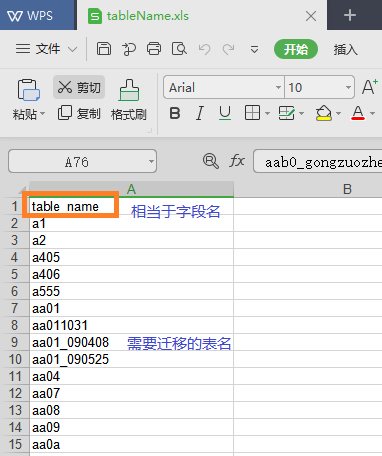
还有一种方法,是把需要迁移数据的表名写到Excel中,从Excel中读取表名。
如果mysql库和oralce库的表不一一对应,比如mysql中有的表但oracle中没有,那用第一种方法查出的表名,用于转换会报错(因为oracle找不到表)。这时候,筛选出两个库都有的表并写到Excel中,从Excel读取表更合适。
Excel写成下面的格式,读取时会把第一行的内容作为查询出来的字段名。
点击文件——新建——转换,在左侧的 核心对象 标签下选择 输入 下的 Excel输入,双击添加到右侧的转换面板,再选择 作业 下的 复制记录到结果 ,双击添加到右侧的转换面板。
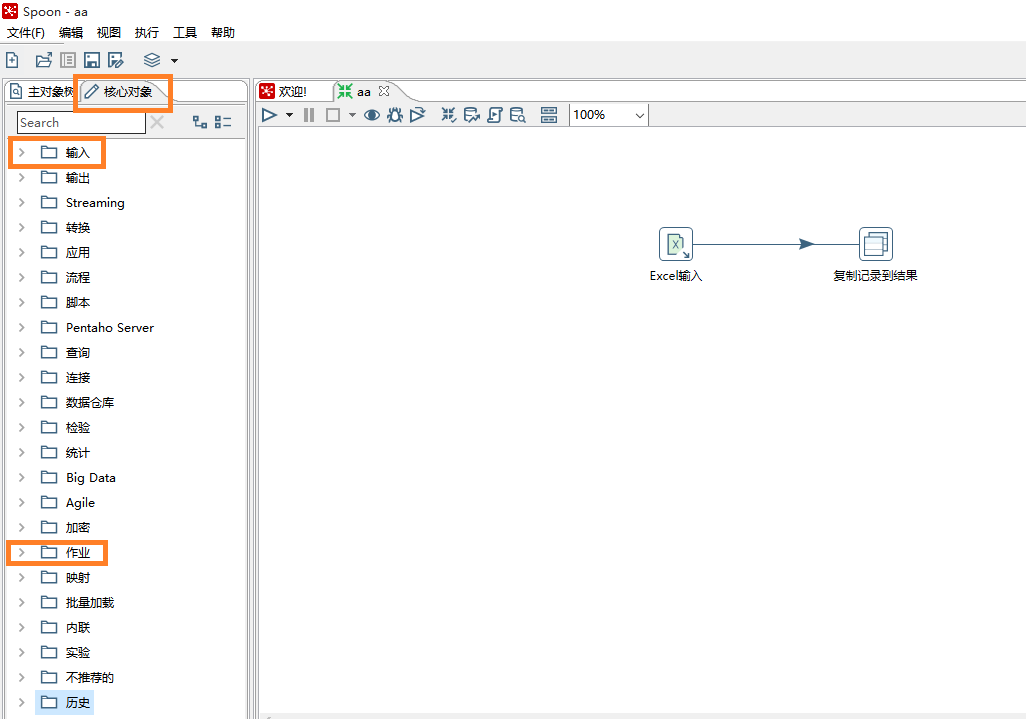
接下来配置Excel输入,双击 Excel输入 的图标,按以下步骤配置。
首先是 文件 标签。 在文件或目录 那一行点击 浏览,选择上面整理好的Excel表格。再点击 增加,选中的文件 一栏就会出现路径。

接下来是 工作表 标签。点击下方的 获取工作表名称,双击选择记录表名的sheet1,点击确定。sheet1就出现在 要读取的工作表列表 中。

最后是 字段 标签。点击下面的 获取来自头部数据的字段,开始前,允许清空列的列表。把Excel中的第一行读取为字段名。

最后点击最下方的预览记录,查看是否正确读取了表名。

把这个转换保存为“aa.ktr”。
2.把这些表名设置成变量(转换)
新建转换,在左侧的 核心对象 标签下选择 作业 下的 从结果获取记录,双击添加到右侧的转换面板,再选择 作业 下的 设置变量 ,双击添加到右侧的转换面板。
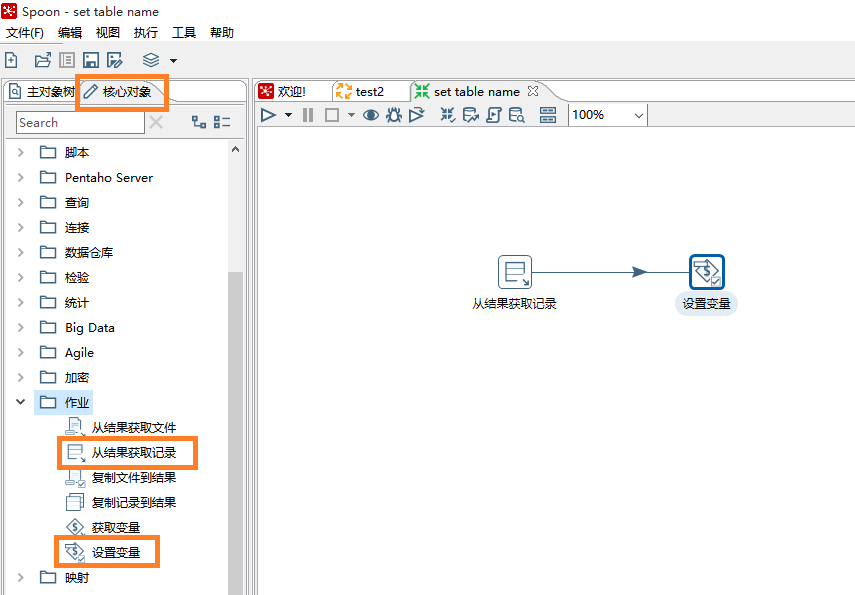
接下来配置这两个节点。
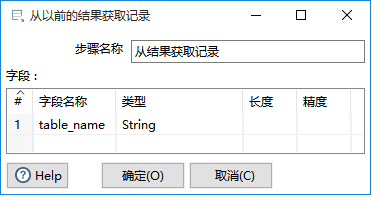
双击 从结果获取记录,填写字段名称和类型(获取表名时,两种方法的字段都写成了table_name,就是为了这里读取字段时可以统一)。
双击 设置变量,字段名称仍然是table_name,为取到的字段取一个变量名,比如“vtable”,变量活动类型如下。

把这个转换保存成set table name.ktr。
3.根据变量设置表输入和表输出(转换)
这个步骤和单表迁移的步骤相同,新建一个转换,添加表输入和表输出节点。

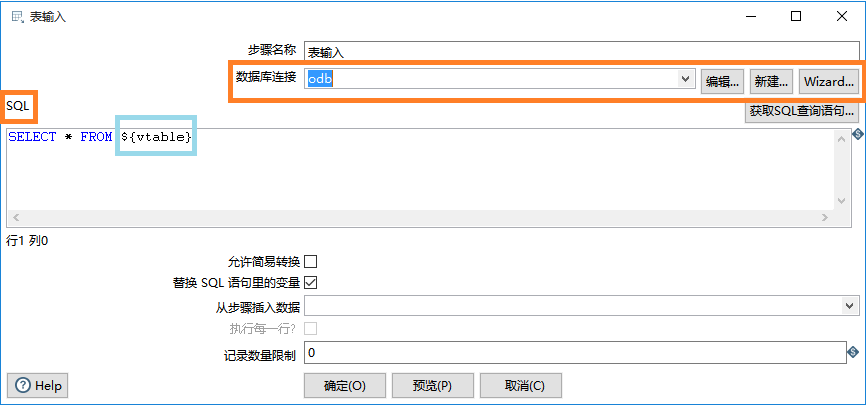
表输入 的配置仍然是新建oracle的数据库连接,填写sql查询语句。与单表迁移不同,查询语句from后不填表名,填写上一步设置的变量名 vtable,这个变量保存了所有的表名。因为还没有把这些步骤关联起来,所以现在不能预览数据。
表输出 的配置仍然是新建mysql的数据库连接,但目标表需要填写与表输入一致的变量名 vtable,提交记录数量是指每插入1000条记录commit一次。如果定时循环同步数据,可以勾选裁剪表或者忽略插入错误两种方式,第一种方式裁剪表即 truncate table ,即更新时先删除所有表中所有数据,然后再把源数据库数据重新提交,可以实现真正意义上的同步,只是最好在夜里定时更新,以免项目数据出问题。第二种,忽略插入错误,因为这整个流程是根据主键id同步的,如果有主键重复的就会报错,无法插入。所以忽略这个错误,只插入新增的数据,之前那些已有的数据,因为主键重复会报错停止,忽略插入错误后,可以继续执行。指定数据库字段这个选项需要注意,如果源数据库表与目标数据库表数据结构,字段等完全一致,可以不用勾选。如果源数据库表比目标数据库表新增了字段,那么执行会停止报错(源数据库表字段比目标数据库表字段多会报错,反过来则没事)。勾选此项后,就会忽略源数据库多余字段,只把源数据库与目标数据库相同的表字段数据更新。
。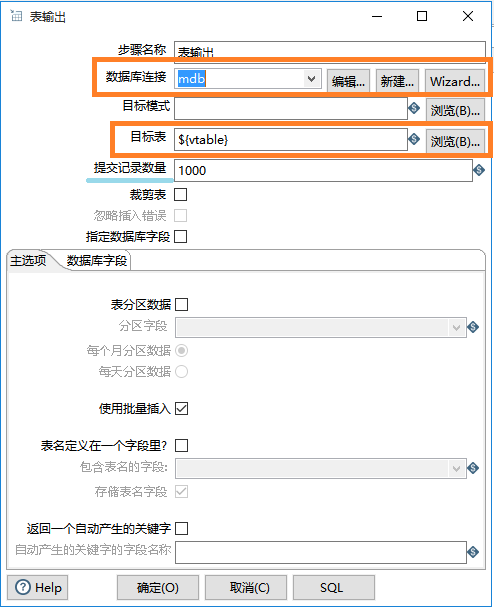
注意:kettle中变量的写法是 ${变量名}。
把这个转换保存成insert data into mysql.ktr。
4.把以上的三个转换连接(作业)
到此为止,我们新建了是三个转换,分别是:
从Excel表读取表名并复制到结果(aa.ktr)
或者直接查询表名,复制到结果
从结果获取记录并设置成变量(set table name.ktr)
根据变量进行表输入和表输出(insert data into mysql.ktr)
接下来把这些转换连接成作业(JOB)。
第一个作业
首先把第2、3个转换结合起来。点击 文件——新建——作业,在左侧的 核心对象 标签下选择 通用,双击添加一个 start ,两个 转换 和一个 成功 到右侧的作业面板,这些作业项都可以改名字。把这个作业保存为insert into mysql.kjb。

点击两个转换可以修改作业项名称,点击浏览选择对应的转换。第一个转换对应 set table name.ktr,第二个转换对应 insert data into mysql.ktr。

第二个作业
接下来把第一个转换与第一个作业结合。点击 文件——新建——作业,在左侧的 核心对象 标签下选择 通用,双击添加一个 start ,一个 转换 ,一个 作业 和一个 成功 到右侧的作业面板,这些作业项都可以改名字。

配置转换和作业,把转换对应到 tables in mysql.ktr 或者 aa.ktr。把作业对应到 insert into mysql.kjb,同时在execution那里选择 执行每一个输入行 用于循环。
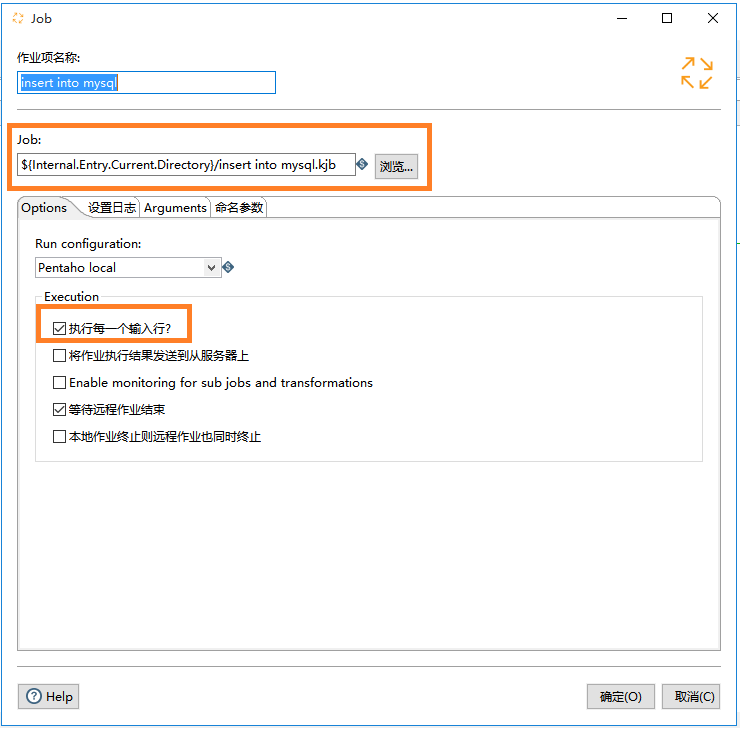
这个作业就是最终需要的作业。
5.开始导数
点击作业面板左上角的三角形,运行这个作业。
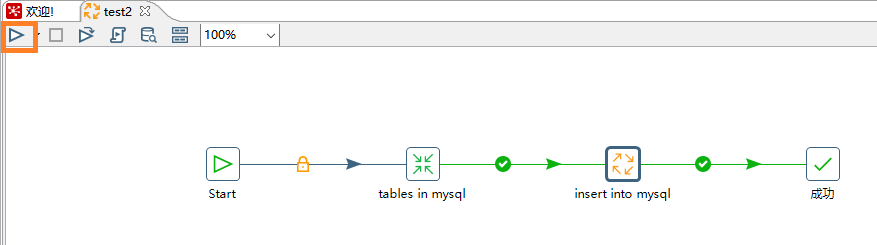
点击执行即可。

执行过程如下,日志记录了迁移的过程。

成功会有提示,过程中出错会终止,执行完作业可以去navicat查看mysql的表。
四、步骤总结
在mysql里查找当前库下有哪些表格,或者从整理好的Excel读取,输出到结果记录
从结果记录里面每次取一行,设置成变量vtable
针对每次使用的变量值,去oracle数据源里生成对应的表输入(通过变量生成)
把变量赋给表输出的表名,其他配置不变,因为表名和字段都和源端oracle是一样的
针对每个“输出到结果记录”做循环,插入每个oracle表的数据到mysql