目录
一、Sharding-JDBC依赖
二、分片策略
1. 标准分片策略
2. 复合分片策略
3. Inline表达式分片策略
4. 通过Hint而非SQL解析的方式分片的策略
5. 不分片的策略
三、分片键
四、分片算法
1. 精确分片算法
2. 范围分片算法
3. 复合分片算法
4. Hint分片算法
五、代码实践
上一篇博文以Sharding-JDBC为契机,了解了ShardingSphere大家族的全貌概览,以及Sharding-JDBC的角色定位。
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
Sharding-JDBC目前已经迭代到4.0.0版本,并且进入了Apache孵化器,但Sharding-JDBC各个大版本之间不支持向下兼容(这里主要描述的是2.x到4.x),大版本和大版本之间犹如断层,如果涉及到升级,就需要改动代码,并且2.x到4.x多多少少都有点BUG,导致在业务系统引进Sharding-JDBC的过程略显艰难。
接下来将介绍Sharding-JDBC的2.0.3版本,以及它的长处和短板。
一、Sharding-JDBC依赖
<!-- sharding-jdbc-core --> <dependency> <groupId>io.shardingjdbc</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>2.0.3</version> </dependency> <!-- sharding-jdbc-spring-namespace --> <dependency> <groupId>io.shardingjdbc</groupId> <artifactId>sharding-jdbc-core-spring-namespace</artifactId> <version>2.0.3</version> </dependency>
Sharding-JDBC没有将Spring Schema上传至公网,需引入namespace依赖包。
二、分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略:标准分片策略、复合分片策略、Inline表达式分片策略、通过Hint而非SQL解析的方式分片的策略和不分片的策略。
1. 标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=、IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
2. 复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=、IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
3. Inline表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如 t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为 t_user_0 到 t_user_7 。
4. 通过Hint而非SQL解析的方式分片的策略
对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
5. 不分片的策略
对应NoneShardingStrategy。不分片的策略。
标准分片策略、复合分片策略和Inline表达式分片策略要求分片键(即分片字段)必须存在于SQL中和数据表结构中,否则无法正确分片;相反,若分片键不存在于SQL中和数据表结构中,则可以使用Hint方式进行强制路由。
三、分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
四、分片算法
通过分片算法将数据分片,支持通过=、IN和BETWEEN AND分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
1. 精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
2. 范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
3. 复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
4. Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
五、代码实践
在正式介绍代码之前,有必要先描述下业务背景,便于理解代码的用途。
数据表结构:
CREATE TABLE `settlement_20180403` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `pay_serial_number` varchar(32) DEFAULT NULL COMMENT '支付流水号', `user_mobile` varchar(15) DEFAULT NULL COMMENT '用户手机号', `money` int(10) DEFAULT '0' COMMENT '支付或退款金额, 单位: 分', `operate_tm` timestamp NULL DEFAULT NULL COMMENT '操作时间', `refund` tinyint(1) DEFAULT NULL COMMENT '是否退款 1: 是 2: 否', `remark` varchar(32) DEFAULT NULL COMMENT '备注', PRIMARY KEY (`id`), UNIQUE KEY `PAY_SERIAL_NUM_UNIQUE` (`pay_serial_number`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
表结构中比较有趣的字段是 pay_serial_number ,以 232042018040353088 为例, pay_serial_number 由三部分组成:前5位是固定编码,样例中是23204,中间8位是日期,包含年月日,样例中是20180403,最后5位是随机数,样例中是53088,以上三部分组成了支付流水号。
随着业务量逐渐扩增, settlement 表数据量急剧,需要以时间作为分表条件水平切分数据,分表字段则为 pay_serial_number ,其中的日期则为分表条件。接下来的代码都是以此业务背景展开。
如下代码配置了标准分片策略中的精确分片算法PreciseShardingAlgorithm和Hint分片算法HintShardingAlgorithm。
XML配置:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:sharding="http://shardingjdbc.io/schema/shardingjdbc/sharding" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd http://shardingjdbc.io/schema/shardingjdbc/sharding http://shardingjdbc.io/schema/shardingjdbc/sharding/sharding.xsd"> <!-- 标准分片策略 --> <sharding:standard-strategy id="settlementTableShardingStandardStrategy" sharding-column="pay_serial_number" precise-algorithm-class="org.cellphone.finance.repo.sharding.PreciseTableShardingAlgorithm"/> <!-- 基于暗示(Hint)的数据分片策略 --> <sharding:hint-strategy id="settlementTableShardingHintStrategy" algorithm-class="org.cellphone.finance.repo.sharding.HintTableShardingAlgorithm"/> <!-- 加了分库分表插件,spring boot 启动会实例化两个dataSource,不知是否正常? --> <sharding:data-source id="shardingDataSource"> <!-- dataSource是数据库连接池 --> <sharding:sharding-rule data-source-names="dataSource"> <sharding:table-rules> <sharding:table-rule logic-table="settlement" table-strategy-ref="settlementTableShardingStandardStrategy"/> <!-- logic-table 一定要和SQL中的表名以及HintManager中配置的logicTable一致,否则无法找到对应的table rule --> <sharding:table-rule logic-table="settlement_hint" table-strategy-ref="settlementTableShardingHintStrategy"/> </sharding:table-rules> </sharding:sharding-rule> <sharding:props> <prop key="sql.show">true</prop> </sharding:props> </sharding:data-source> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="shardingDataSource"/> </bean> <tx:annotation-driven/> </beans>
精确分片算法:
package org.cellphone.finance.repo.sharding; import com.google.common.collect.Lists; import io.shardingjdbc.core.api.algorithm.sharding.PreciseShardingValue; import io.shardingjdbc.core.api.algorithm.sharding.standard.PreciseShardingAlgorithm; import org.apache.commons.collections.CollectionUtils; import org.cellphone.common.constant.CommonConst; import java.util.Collection; /** * 精确分片算法,属于标准分片算法,用于处理=和IN的分片 * <p> * 使用精确分片算法的前提:分片字段必须存在与SQL中、数据库表结构中,否则无法使用精确分片算法 * <p> * 此分片算法应用于SETTLEMENT数据表,这里是按天分表 * <p> * 特别说明:Sharding Jdbc版本:2.0.3 * <p> * Created by on 2018/4/9. */ public class PreciseTableShardingAlgorithm implements PreciseShardingAlgorithm<String> { /** * 精确分片算法 * * @param availableTargetNames 目标数据源名称或数据表名称,注意:是逻辑数据源名或逻辑数据表名,来自SQL * @param shardingValue 分片值,来自SQL中分片字段对应的值 * @return 真实数据源名称或数据表名称 */ @Override public String doSharding(final Collection<String> availableTargetNames, final PreciseShardingValue<String> shardingValue) { // 默认数据表名称,有可能数据库中不存在这张表 String tableName = "settlement"; // 逻辑表名为空,返回默认表名 if (CollectionUtils.isEmpty(availableTargetNames)) return tableName; // availableTargetNames来自SQL,只有一个元素 tableName = Lists.newArrayList(availableTargetNames).get(0); String paySerialNumber = shardingValue.getValue(); String suffix = paySerialNumber.substring(5, 13); return tableName + CommonConst.UNDERLINE + suffix; } }
上面说过,精确分片算法可以很完美的支持SQL语句中的=和IN的分片操作,因此PreciseTableShardingAlgorithm可以很好的支持简单的INSERT、UPDATE、DELETE和SELECT操作。
但如果要通过 pay_serial_number 查询数据就行不通了,因为分片键并不直接存在与SQL中和数据表结构中,而是间接存在于 pay_serial_number 中的时间数据,因此,就需要通过Hint方式来进行分片才能定位到真实的数据表。
Hint分片算法:
package org.cellphone.finance.repo.sharding; import com.google.common.collect.Lists; import io.shardingjdbc.core.api.algorithm.sharding.ListShardingValue; import io.shardingjdbc.core.api.algorithm.sharding.ShardingValue; import io.shardingjdbc.core.api.algorithm.sharding.hint.HintShardingAlgorithm; import org.apache.commons.collections.CollectionUtils; import org.apache.commons.lang3.StringUtils; import org.apache.commons.lang3.time.DateFormatUtils; import org.apache.commons.lang3.time.DateUtils; import org.cellphone.common.constant.CommonConst; import org.cellphone.common.constant.DateConst; import java.text.ParseException; import java.util.*; /** * Created by on 2019/4/27. */ public class HintTableShardingAlgorithm implements HintShardingAlgorithm { @Override public Collection<String> doSharding(Collection<String> availableTargetNames, ShardingValue shardingValue) { // 数据表名称列表 List<String> tableNames = new ArrayList<>(); // 逻辑表名为空 if (CollectionUtils.isEmpty(availableTargetNames)) return tableNames; // availableTargetNames来自SQL,只有一个元素 String tableName = Lists.newArrayList(availableTargetNames).get(0); tableName = tableName.replace("_hint", StringUtils.EMPTY); ListShardingValue<String> listShardingValue = (ListShardingValue<String>) shardingValue; List<String> list = Lists.newArrayList(listShardingValue.getValues()); Date startTm, endTm; try { startTm = DateUtils.parseDate(list.get(0), DateConst.DATE_FORMAT_NORMAL); endTm = DateUtils.parseDate(list.get(1), DateConst.DATE_FORMAT_NORMAL); } catch (ParseException e) { return tableNames; } Calendar calendar = Calendar.getInstance(); while (startTm.getTime() <= endTm.getTime()) { String suffix = DateFormatUtils.format(startTm, DateConst.DATE_FORMAT_YYYY_MM_DD); tableNames.add(tableName + CommonConst.UNDERLINE + suffix); calendar.setTime(startTm); calendar.add(Calendar.DATE, 1); startTm = calendar.getTime(); } return tableNames; } }
与Hint分片算法对应的Java查询方法 settlementMapper.selectByExample(example) :
public List<Settlement> querySettlements(SettlementExample example, String startTime, String endTime) { HintManager hintManager = HintManager.getInstance(); // logicTable必须和XML中的logic-table以及SQL中的逻辑表名称一致 hintManager.addTableShardingValue("settlement_hint", "start_time", startTime); hintManager.addTableShardingValue("settlement_hint", "end_time", endTime); List<Settlement> settlements = settlementMapper.selectByExample(example); hintManager.close(); return settlements; }
以及该查询方法对应的SQL语句:
select * from settlement_hint t where t.pay_serial_number = ?
单元测试代码:
@Test public void test004QuerySettlements() throws ParseException { String startTime = "2018-04-03 00:00:00", endTime = "2018-04-05 00:00:00"; SettlementExample example = new SettlementExample(); SettlementExample.Criteria criteria = example.createCriteria(); criteria.andPaySerialNumberEqualTo("232042018040353088"); List<Settlement> settlements = repository.querySettlements(example, startTime, endTime); Assert.assertEquals("136********", settlements.get(0).getUserMobile()); }
经过上述一波代码后,原以为单元测试可以完美通过,但天有不测风云,月有阴晴圆缺,单元测试竟然失败了,报错日志提示数据表不存在:
org.springframework.jdbc.BadSqlGrammarException: ### Error querying database. Cause: java.sql.SQLSyntaxErrorException: Table 'warehouse.settlement_hint' doesn't exist ### The error may exist in file [D:programsIdeaProjectswarehousewarehouse-financewarehouse-finance-service argetclassesmapperSettlementMapper.xml] ### The error may involve org.cellphone.finance.repo.mapper.SettlementMapper.selectByExample-Inline ### The error occurred while setting parameters ### SQL: select id, pay_serial_number, user_mobile, money, operate_tm, refund, remark from settlement_hint WHERE ( pay_serial_number = ? ) ### Cause: java.sql.SQLSyntaxErrorException: Table 'warehouse.settlement_hint' doesn't exist ; bad SQL grammar []; nested exception is java.sql.SQLSyntaxErrorException: Table 'warehouse.settlement_hint' doesn't exist at org.springframework.jdbc.support.SQLErrorCodeSQLExceptionTranslator.doTranslate(SQLErrorCodeSQLExceptionTranslator.java:234) at org.springframework.jdbc.support.AbstractFallbackSQLExceptionTranslator.translate(AbstractFallbackSQLExceptionTranslator.java:72) at org.mybatis.spring.MyBatisExceptionTranslator.translateExceptionIfPossible(MyBatisExceptionTranslator.java:73) at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:446) at com.sun.proxy.$Proxy94.selectList(Unknown Source) at org.mybatis.spring.SqlSessionTemplate.selectList(SqlSessionTemplate.java:230) at org.apache.ibatis.binding.MapperMethod.executeForMany(MapperMethod.java:139) at org.apache.ibatis.binding.MapperMethod.execute(MapperMethod.java:76) at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:59) at com.sun.proxy.$Proxy95.selectByExample(Unknown Source) at org.cellphone.finance.repo.SettlementRepository.querySettlements(SettlementRepository.java:62) at org.cellphone.finance.repo.SettlementRepository$$FastClassBySpringCGLIB$$c5ad592f.invoke(<generated>) at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:204) at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.invokeJoinpoint(CglibAopProxy.java:746) at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:163) at org.springframework.dao.support.PersistenceExceptionTranslationInterceptor.invoke(PersistenceExceptionTranslationInterceptor.java:139) at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:185) at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:688) at org.cellphone.finance.repo.SettlementRepository$$EnhancerBySpringCGLIB$$9133dcc1.querySettlements(<generated>) at org.cellphone.finance.SettlementRepositoryTest.test004QuerySettlements(SettlementRepositoryTest.java:89) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50) at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12) at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47) at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17) at org.springframework.test.context.junit4.statements.RunBeforeTestExecutionCallbacks.evaluate(RunBeforeTestExecutionCallbacks.java:73) at org.springframework.test.context.junit4.statements.RunAfterTestExecutionCallbacks.evaluate(RunAfterTestExecutionCallbacks.java:83) at org.springframework.test.context.junit4.statements.RunBeforeTestMethodCallbacks.evaluate(RunBeforeTestMethodCallbacks.java:75) at org.springframework.test.context.junit4.statements.RunAfterTestMethodCallbacks.evaluate(RunAfterTestMethodCallbacks.java:86) at org.springframework.test.context.junit4.statements.SpringRepeat.evaluate(SpringRepeat.java:84) at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325) at org.springframework.test.context.junit4.SpringJUnit4ClassRunner.runChild(SpringJUnit4ClassRunner.java:251) at org.springframework.test.context.junit4.SpringJUnit4ClassRunner.runChild(SpringJUnit4ClassRunner.java:97) at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290) at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71) at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288) at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58) at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268) at org.springframework.test.context.junit4.statements.RunBeforeTestClassCallbacks.evaluate(RunBeforeTestClassCallbacks.java:61) at org.springframework.test.context.junit4.statements.RunAfterTestClassCallbacks.evaluate(RunAfterTestClassCallbacks.java:70) at org.junit.runners.ParentRunner.run(ParentRunner.java:363) at org.springframework.test.context.junit4.SpringJUnit4ClassRunner.run(SpringJUnit4ClassRunner.java:190) at org.junit.runner.JUnitCore.run(JUnitCore.java:137) at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:68) at com.intellij.rt.execution.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:47) at com.intellij.rt.execution.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:242) at com.intellij.rt.execution.junit.JUnitStarter.main(JUnitStarter.java:70) Caused by: java.sql.SQLSyntaxErrorException: Table 'warehouse.settlement_hint' doesn't exist at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:120) at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:97) at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122) at com.mysql.cj.jdbc.ClientPreparedStatement.executeInternal(ClientPreparedStatement.java:975) at com.mysql.cj.jdbc.ClientPreparedStatement.execute(ClientPreparedStatement.java:392) at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3409) at com.alibaba.druid.filter.FilterEventAdapter.preparedStatement_execute(FilterEventAdapter.java:440) at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3407) at com.alibaba.druid.proxy.jdbc.PreparedStatementProxyImpl.execute(PreparedStatementProxyImpl.java:167) at com.alibaba.druid.pool.DruidPooledPreparedStatement.execute(DruidPooledPreparedStatement.java:498) at io.shardingjdbc.core.executor.type.prepared.PreparedStatementExecutor$3.execute(PreparedStatementExecutor.java:101) at io.shardingjdbc.core.executor.type.prepared.PreparedStatementExecutor$3.execute(PreparedStatementExecutor.java:97) at io.shardingjdbc.core.executor.ExecutorEngine.executeInternal(ExecutorEngine.java:187) at io.shardingjdbc.core.executor.ExecutorEngine.syncExecute(ExecutorEngine.java:167) at io.shardingjdbc.core.executor.ExecutorEngine.execute(ExecutorEngine.java:131) at io.shardingjdbc.core.executor.ExecutorEngine.executePreparedStatement(ExecutorEngine.java:98) at io.shardingjdbc.core.executor.type.prepared.PreparedStatementExecutor.execute(PreparedStatementExecutor.java:97) at io.shardingjdbc.core.jdbc.core.statement.ShardingPreparedStatement.execute(ShardingPreparedStatement.java:141) at org.apache.ibatis.executor.statement.PreparedStatementHandler.query(PreparedStatementHandler.java:63) at org.apache.ibatis.executor.statement.RoutingStatementHandler.query(RoutingStatementHandler.java:79) at org.apache.ibatis.executor.SimpleExecutor.doQuery(SimpleExecutor.java:63) at org.apache.ibatis.executor.BaseExecutor.queryFromDatabase(BaseExecutor.java:326) at org.apache.ibatis.executor.BaseExecutor.query(BaseExecutor.java:156) at org.apache.ibatis.executor.CachingExecutor.query(CachingExecutor.java:109) at com.github.pagehelper.PageInterceptor.intercept(PageInterceptor.java:108) at org.apache.ibatis.plugin.Plugin.invoke(Plugin.java:61) at com.sun.proxy.$Proxy117.query(Unknown Source) at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:148) at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:141) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:433) ... 46 more
抛出错误堆栈后,很纳闷为何没有将逻辑表名 settlement_hint 转换为真实表名 settlement_20180403 ,于是就跟踪了Sharding-JDBC源码。
经过DEBUG,得知所有JDBC操作都会调用 io.shardingjdbc.core.routing.type.simple.SimpleRoutingEngine#route 方法:
/* * Copyright 1999-2015 dangdang.com. * <p> * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. * </p> */ package io.shardingjdbc.core.routing.type.simple; import io.shardingjdbc.core.api.algorithm.sharding.ShardingValue; import io.shardingjdbc.core.hint.HintManagerHolder; import io.shardingjdbc.core.hint.ShardingKey; import io.shardingjdbc.core.parsing.parser.context.condition.Column; import io.shardingjdbc.core.parsing.parser.context.condition.Condition; import io.shardingjdbc.core.parsing.parser.sql.SQLStatement; import io.shardingjdbc.core.routing.strategy.ShardingStrategy; import io.shardingjdbc.core.routing.type.RoutingEngine; import io.shardingjdbc.core.routing.type.RoutingResult; import io.shardingjdbc.core.routing.type.TableUnit; import io.shardingjdbc.core.rule.DataNode; import io.shardingjdbc.core.rule.ShardingRule; import io.shardingjdbc.core.rule.TableRule; import com.google.common.base.Optional; import com.google.common.base.Preconditions; import lombok.RequiredArgsConstructor; import java.util.ArrayList; import java.util.Collection; import java.util.LinkedList; import java.util.List; /** * Simple routing engine. * * @author zhangliang */ @RequiredArgsConstructor public final class SimpleRoutingEngine implements RoutingEngine { private final ShardingRule shardingRule; private final List<Object> parameters; private final String logicTableName; private final SQLStatement sqlStatement; /** * Sharding-JDBC路由方法,所有JDBC操作都会调用此方法,路由到真实表 * * @return */ @Override public RoutingResult route() { // 从XML中根据逻辑表名获取配置的数据表规则 TableRule tableRule = shardingRule.getTableRule(logicTableName); // 获取数据源分片值,分片值来自逻辑SQL中的数据,由于XML只配置了单个数据源,暂时不深入分析此环节 List<ShardingValue> databaseShardingValues = getDatabaseShardingValues(tableRule); // 获取数据表分片值,分片值来自逻辑SQL中的数据,重点分析这部分代码 List<ShardingValue> tableShardingValues = getTableShardingValues(tableRule); // 计算需要路由的真实数据源 Collection<String> routedDataSources = routeDataSources(tableRule, databaseShardingValues); Collection<DataNode> routedDataNodes = new LinkedList<>(); for (String each : routedDataSources) { // routeTables方法计算需要路由的真实数据表,重点分析这部分代码 routedDataNodes.addAll(routeTables(tableRule, each, tableShardingValues)); } // 产生路由结果 return generateRoutingResult(routedDataNodes); } private List<ShardingValue> getDatabaseShardingValues(final TableRule tableRule) { ShardingStrategy strategy = shardingRule.getDatabaseShardingStrategy(tableRule); return HintManagerHolder.isUseShardingHint() ? getDatabaseShardingValuesFromHint(strategy.getShardingColumns()) : getShardingValues(strategy.getShardingColumns()); } /** * 获取数据表分片值 * 分片值由上面提到的querySettlements通过hintManager传入 * * @param tableRule 数据表规则,从XML文件中获取 * @return 分片值列表 */ private List<ShardingValue> getTableShardingValues(final TableRule tableRule) { // 从XML文件中获取数据表规则 ShardingStrategy strategy = shardingRule.getTableShardingStrategy(tableRule); /* * 判断是否使用了Hint分片算法: * 1. 是:根据ShardingStrategy中拿到的shardingColumns来获取shardingValues,问题就出在这里!!! * 2. 否:从SQL中根据shardingColumns来获取shardingValues */ return HintManagerHolder.isUseShardingHint() ? getTableShardingValuesFromHint(strategy.getShardingColumns()) : getShardingValues(strategy.getShardingColumns()); } private List<ShardingValue> getDatabaseShardingValuesFromHint(final Collection<String> shardingColumns) { List<ShardingValue> result = new ArrayList<>(shardingColumns.size()); for (String each : shardingColumns) { Optional<ShardingValue> shardingValue = HintManagerHolder.getDatabaseShardingValue(new ShardingKey(logicTableName, each)); if (shardingValue.isPresent()) { result.add(shardingValue.get()); } } return result; } /** * 从Hint分片算法中获取shardingValues * * @param shardingColumns 分片键 * @return 分片值列表 */ private List<ShardingValue> getTableShardingValuesFromHint(final Collection<String> shardingColumns) { List<ShardingValue> result = new ArrayList<>(shardingColumns.size()); for (String each : shardingColumns) { // 从HintManagerHolder获取sharding values Optional<ShardingValue> shardingValue = HintManagerHolder.getTableShardingValue(new ShardingKey(logicTableName, each)); if (shardingValue.isPresent()) { result.add(shardingValue.get()); } } return result; } private List<ShardingValue> getShardingValues(final Collection<String> shardingColumns) { List<ShardingValue> result = new ArrayList<>(shardingColumns.size()); for (String each : shardingColumns) { Optional<Condition> condition = sqlStatement.getConditions().find(new Column(each, logicTableName)); if (condition.isPresent()) { result.add(condition.get().getShardingValue(parameters)); } } return result; } private Collection<String> routeDataSources(final TableRule tableRule, final List<ShardingValue> databaseShardingValues) { Collection<String> availableTargetDatabases = tableRule.getActualDatasourceNames(); if (databaseShardingValues.isEmpty()) { return availableTargetDatabases; } Collection<String> result = shardingRule.getDatabaseShardingStrategy(tableRule).doSharding(availableTargetDatabases, databaseShardingValues); Preconditions.checkState(!result.isEmpty(), "no database route info"); return result; } /** * 计算需要路由的真实数据表 * * @param tableRule 数据表规则,从XML中获取 * @param routedDataSource 需要路由的数据源 * @param tableShardingValues 数据表分片值 * @return 需要路由的真实数据节点 */ private Collection<DataNode> routeTables(final TableRule tableRule, final String routedDataSource, final List<ShardingValue> tableShardingValues) { // 所有的真实数据表名,在XML中可以显式配置,也可以省略 Collection<String> availableTargetTables = tableRule.getActualTableNames(routedDataSource); /* * table sharding values是否为空: * 1. 是:路由到所有真实表 * 2. 否:路由到自定义的分表策略算法定义的数据表 * * 问题就出在这里:tableShardingValues.isEmpty()为true,导致无法使用自定义分表策略算法 */ Collection<String> routedTables = tableShardingValues.isEmpty() ? availableTargetTables : shardingRule.getTableShardingStrategy(tableRule).doSharding(availableTargetTables, tableShardingValues); Preconditions.checkState(!routedTables.isEmpty(), "no table route info"); Collection<DataNode> result = new LinkedList<>(); for (String each : routedTables) { result.add(new DataNode(routedDataSource, each)); } return result; } private RoutingResult generateRoutingResult(final Collection<DataNode> routedDataNodes) { RoutingResult result = new RoutingResult(); for (DataNode each : routedDataNodes) { result.getTableUnits().getTableUnits().add(new TableUnit(each.getDataSourceName(), logicTableName, each.getTableName())); } return result; } }
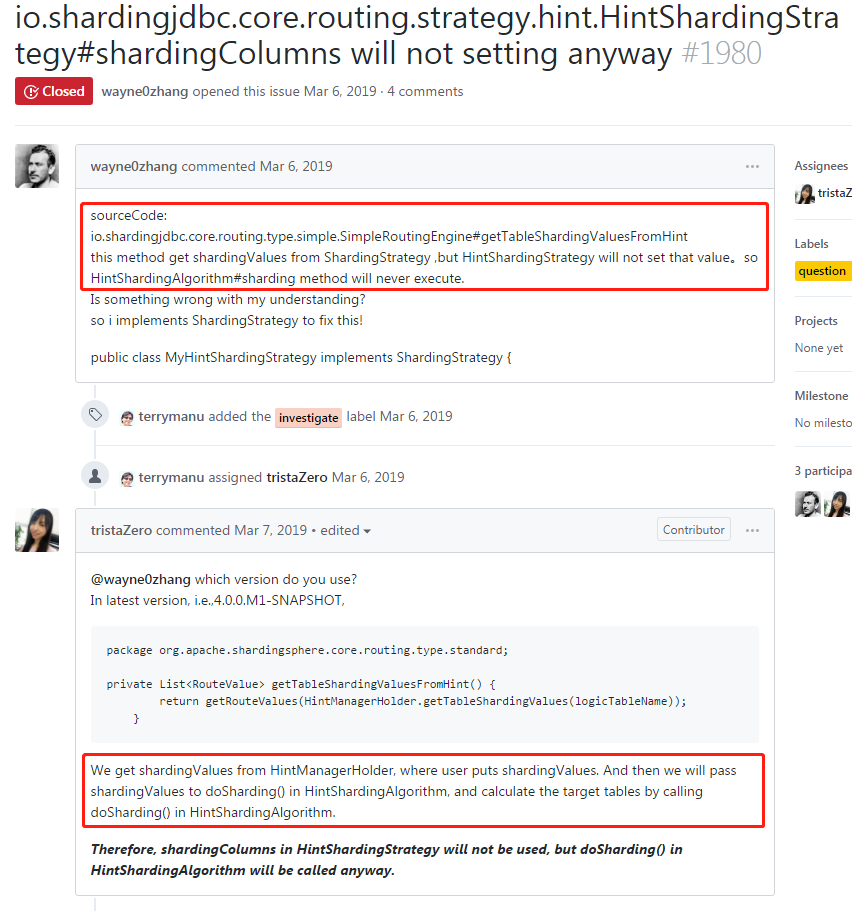
上述代码中, getTableShardingValuesFromHint 返回的 List<ShardingValue> 为空,原因是 getTableShardingValuesFromHint 的入参 strategy.getShardingColumns() 为空列表,而此参数来自Sharding-JDBC的默认实现HintShardingStrategy:
/* * Copyright 1999-2015 dangdang.com. * <p> * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. * </p> */ package io.shardingjdbc.core.routing.strategy.hint; import io.shardingjdbc.core.api.algorithm.sharding.hint.HintShardingAlgorithm; import io.shardingjdbc.core.api.algorithm.sharding.ShardingValue; import io.shardingjdbc.core.routing.strategy.ShardingStrategy; import lombok.Getter; import java.util.Collection; import java.util.TreeSet; /** * Hint sharding strategy. * final类,无法继承此类来重定义内部逻辑 * * * @author zhangliang */ public final class HintShardingStrategy implements ShardingStrategy { /** * 没有提供Setter方法和可以配置的入口,无法设置shardingColumns,这是2.0.3版本的BUG * * github issue: https://github.com/apache/incubator-shardingsphere/issues/1980 */ @Getter private final Collection<String> shardingColumns; private final HintShardingAlgorithm shardingAlgorithm; public HintShardingStrategy(final HintShardingAlgorithm shardingAlgorithm) { this.shardingColumns = new TreeSet<>(String.CASE_INSENSITIVE_ORDER); this.shardingAlgorithm = shardingAlgorithm; } @Override public Collection<String> doSharding(final Collection<String> availableTargetNames, final Collection<ShardingValue> shardingValues) { Collection<String> shardingResult = shardingAlgorithm.doSharding(availableTargetNames, shardingValues.iterator().next()); Collection<String> result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER); result.addAll(shardingResult); return result; } }
跟踪到此,Hint分片算法无法使用的原因一路了然,这是Sharding-JDBC 2.0.3版本的BUG,但在后续版本4.x中得到了修复。