Protocol Buffers是Google开发一种数据描述语言,能够将结构化数据序列化,可用于数据存储、通信协议等方面。
不了解Protocol Buffers的同学可以把它理解为更快、更简单、更小的JSON或者XML,区别在于Protocol Buffers是二进制格式,而JSON和XML是文本格式。
相对于XML,Protocol Buffers的具有如下几个优点:
- 简洁
- 体积小:消息大小只需要XML的1/10 ~ 1/3;
- 速度快:解析速度比XML快20 ~ 100倍;
- 使用Protocol Buffers的编译器,可以生成更容易在编程中使用的数据访问代码;
- 更好的兼容性,Protocol Buffers设计的一个原则就是要能够很好的支持向下或向上兼容。
看一个简单的对比例子,表达一个用户的三个基本的属性,如果使用XML消息体大小为82 bytes。
<person> <id>1234</id> <name>John Doe</name> <email>jdoe@example.com</email> </person>
如果使用JSON消息体大小为56 bytes。
{
"id": 1234,
"name": "John Doe",
"email": "jdoe@example.com"
}
使用Protocol Buffers则只需要 31 bytes。
0A
08 4A 6F 6E 20 44 6F 65
10
D2 09
1A
10 6A 64 6F 65 40 65 78 61 6d 70 6C 65 2E 63 6F 6D
下面是几种序列化方式的对比:
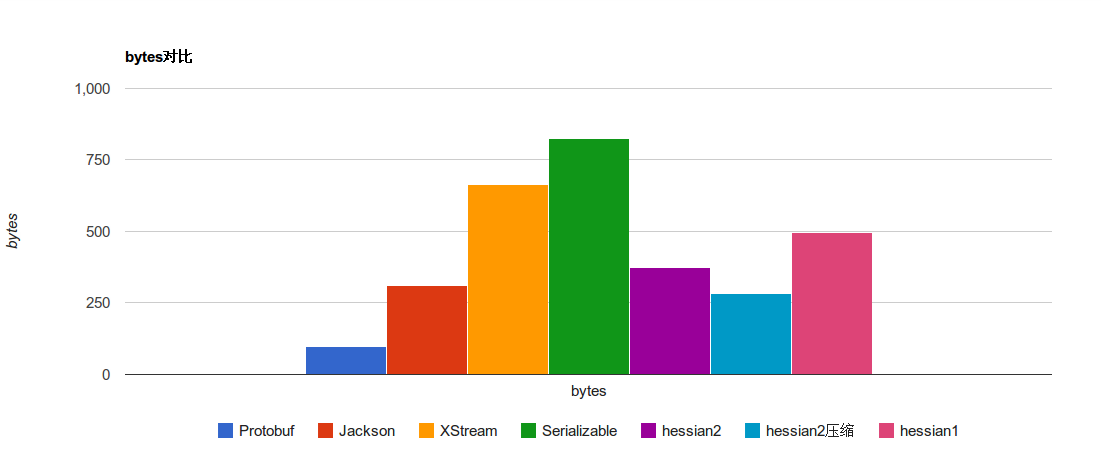

| Protobuf | Jackson | XStream | Serializable | hessian2 | hessian2压缩 | hessian1 | |
| 序列化(单位:ns) | 1154 | 5421 | 92406 | 10189 | 26794 | 100766 | 29027 |
| 反序列化(单位:ns) | 1334 | 8743 | 117329 | 64027 | 37871 | 188432 | 37596 |
| bytes | 97 | 311 | 664 | 824 | 374 | 283 | 495 |
尽管Protocol Buffers有序列化速度快、报文体积小以及更好的兼容性等优点,但同时也有一些缺点,在使用时要根据实际情况来选择使用。
- 缺乏自描述,可读性差,可以使用TextFormat;
- 适用于内部服务和存储,而不适合直接对外公开,如Open API,protobuf v3将加入对json的支持,可解决此问题。
图片转载:Protobuf协议的Java应用例子