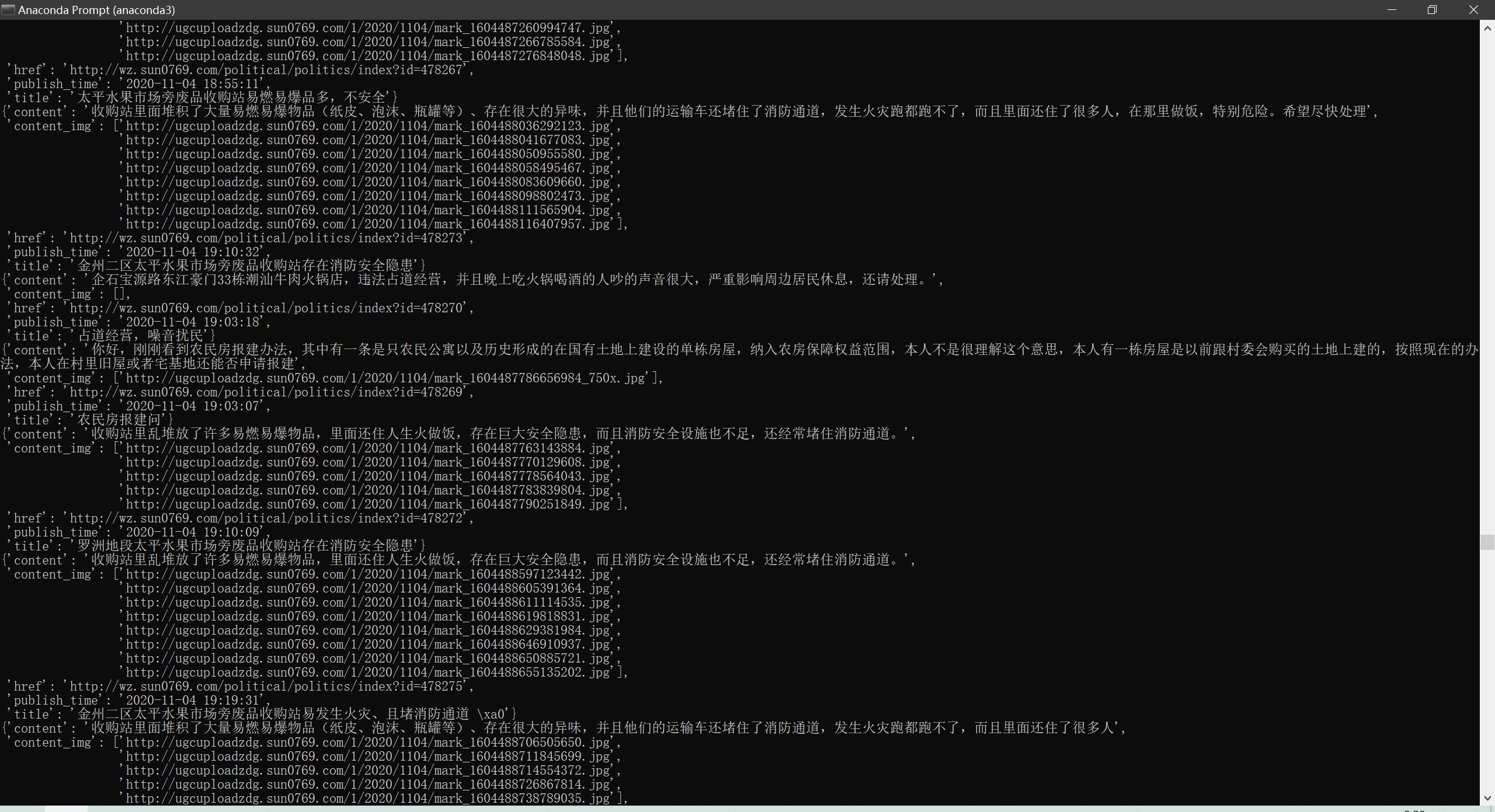
目的:
爬取阳光热线问政平台问题中每个帖子的标题、详情URL、详情内容、图片以及发布时间
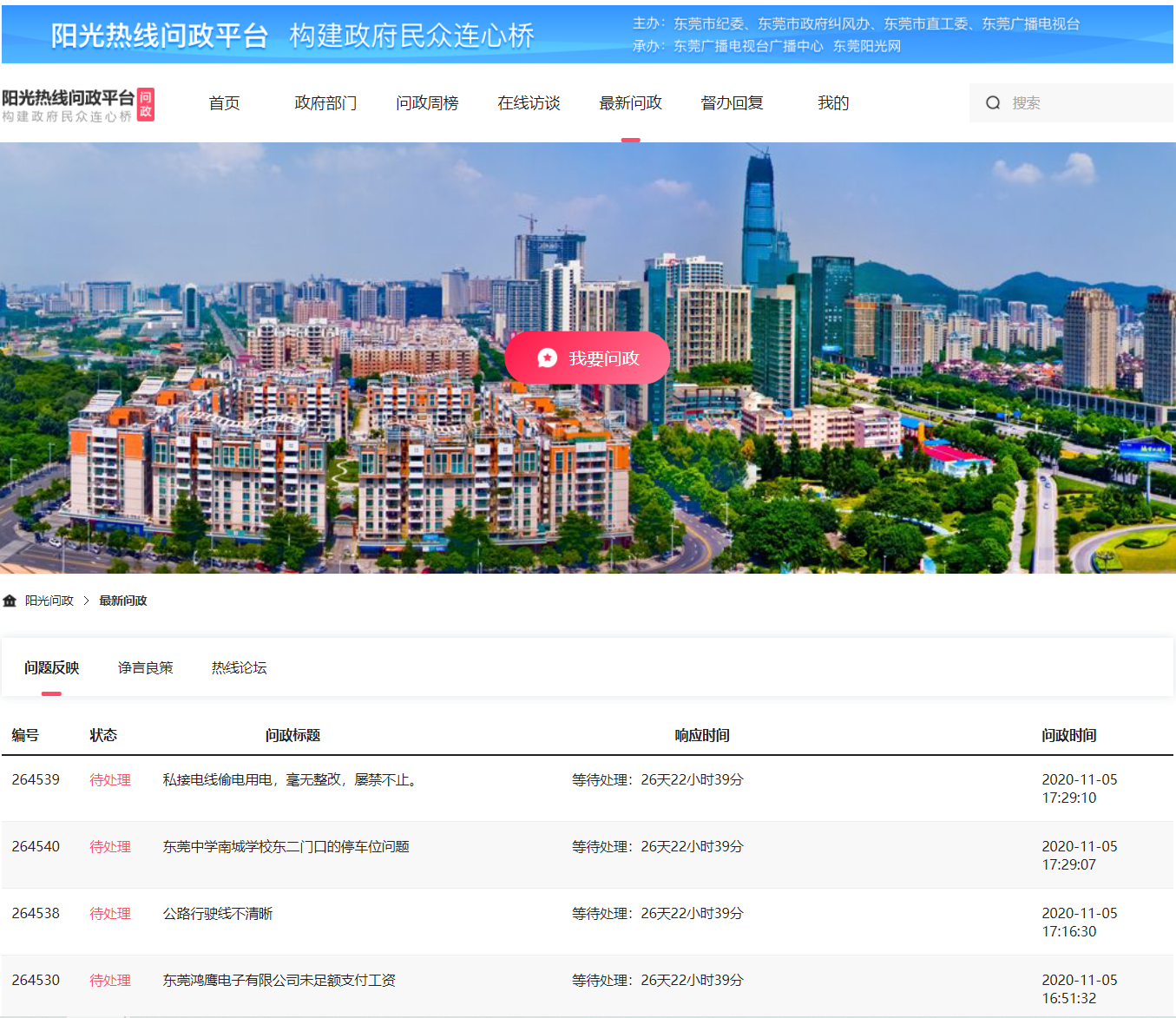

步骤:
1、创建爬虫项目
1 scrapy startproject yangguang 2 cd yangguang 3 scrapy genspider yangguang sun0769.com
2、设置item.py文件
import scrapy class YangguangItem(scrapy.Item): # 每条帖子的标题 title = scrapy.Field() # 帖子链接 href = scrapy.Field() # 发布日期 publish_time = scrapy.Field() # 详情内容 content = scrapy.Field() # 详情图片 content_img = scrapy.Field()
3、编写爬虫文件
1 import scrapy 2 from yangguang.items import YangguangItem 3 4 5 class YgSpider(scrapy.Spider): 6 name = 'yg' 7 allowed_domains = ['sun0769.com'] 8 start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1'] 9 10 page = 1 11 url = "http://wz.sun0769.com/political/index/politicsNewest?id=1&page= {}" 12 13 def parse(self, response): 14 # 分组 15 li_list = response.xpath("//ul[@class='title-state-ul']/li") 16 for li in li_list: 17 item = YangguangItem() 18 item["title"] = li.xpath("./span[@class='state3']/a/text()").extract_first() 19 item["href"] = "http://wz.sun0769.com" + li.xpath("./span[@class='state3']/a/@href").extract_first() 20 item["publish_time"] = li.xpath("./span[@class='state5 ']/text()").extract_first() 21 22 yield scrapy.Request( 23 item["href"], 24 callback=self.parse_detail, 25 meta={ 26 "item": item, 27 "proxy": "http://171.12.221.51:9999" 28 } 29 ) 30 # 翻页 31 if self.page < 10: 32 self.page += 1 33 next_url = self.url.format(self.page) 34 35 yield scrapy.Request(next_url, callback=self.parse, meta={"proxy": "http://123.163.118.71:9999"}) 36 37 def parse_detail(self, response): # 处理详情页 38 item = response.meta["item"] 39 item["content"] = response.xpath("//div[@class='details-box']/pre/text()").extract_first() 40 item["content_img"] = response.xpath("//div[@class='clear details-img-list Picture-img']/img/@src").extract() 41 yield item
4、测试
scrapy crawl yg