要求:
1.选一个自己感兴趣的主题或网站。(所有同学不能雷同)
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
注:本来是打算爬取单机游戏吧前1000个帖子和其中所有的回复,后因实在是太多,爬的太慢,所以缩小到100个。。。回复也因为不能登陆百度账号所以无法爬取楼中楼的回复。。。。哪怕是用上伪·4线程爬虫(因为某历史遗留问题)也太慢了。。
一、主页内容:
生成主页链接:
def HomePageUrlBuild(): HomePageUrl=[] for i in range(0,101,50): HomePageUrl.append("https://tieba.baidu.com/f?kw=%E5%8D%95%E6%9C%BA%E6%B8%B8%E6%88%8F&ie=utf-8&pn="+str(i)) return(HomePageUrl)
单机吧每页有50个帖子,所以以50为步长生成两个主页链接,共爬取100个帖子
爬取主页:
def HomePage(HomePageUrl): #爬虫伪装 head = {} head['user-agent']='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' MainPage=requests.get(HomePageUrl,headers=head) MainPage.encoding='utf-8' return(MainPage)
二、分页内容:
爬取生成分页链接:
def PagingLink(MainPage): #存放链接 TitleLink=[] TitleLinkMate=[] IndexTitle=[] for i in range(2): TitleLinkMate.append(re.findall('href="/p/(.*?)" title="(.*?)"',MainPage[i].text,re.S)) for temp in range(2): for i in TitleLinkMate[temp]: #存放标题与链接 TitleLinkItems={} TitleLinkItems["标题"]=str(i[1]) TitleLinkItems["链接"]="https://tieba.baidu.com/p/"+str(i[0]) TitleLink.append(TitleLinkItems["链接"]) IndexTitle.append(TitleLinkItems) return(IndexTitle,TitleLink)
生成分页链接,并和该链接的标题一起存到字典TitleLinkItems中
爬取分页:
Paging(TitleLink): #爬虫伪装 head = {} head['user-agent']='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' PagingPage=requests.get(TitleLink,headers=head) PagingPage.encoding='utf-8' #分析分页并提取文章与回复 AnalysisResult=AnalysisPaging(PagingPage) return(AnalysisResult)
将爬取到的分页源代码传到AnalysisPaging函数中分析
分析分页并提取文章与回复:
def AnalysisPaging(PagingPage): PagingSoup=BeautifulSoup(PagingPage.text,'html.parser') AllReply=[] for i in PagingSoup.select("div.l_post.l_post_bright.j_l_post.clearfix"): if len(i)!=5: ReplyItems1={} #ID ReplyItems1["ID"]=i.select(".d_name")[0].text #内容 ReplyItems1["内容"]=i.select(".d_post_content")[0].text #时间 b=i.select(".tail-info") for y in i.select(".tail-info"): if len(re.findall("d+-d+-d+sd+:d+",y.text,re.S))>0: time1=datetime.datetime.strptime(y.text,'%Y-%m-%d %H:%M') ReplyItems1["时间"]=time1 #将字典1存入数组AllReply AllReply.append(ReplyItems1) return(AllReply)
在该函数中爬取分页的回复,回复ID,回复时间,发帖ID,发帖时间并存为字典放到列表AllReply中(在该函数本来是打算爬取楼中楼回复的,但是最后发现爬虫没登录百度账号所以爬取的网页源代码中并没有楼中楼回复的源代码,之前没发现这个问题是老是以为出BUG了)
三、主函数入口:
#***************************************************************************************************************************** #函数入口 if __name__ == '__main__': #4线程 pool=tp(4) #主页链接 HomePageUrl=HomePageUrlBuild() print(HomePageUrl) #爬取主页 MainPageContent=pool.map(HomePage,HomePageUrl) #爬取分页链接 TitleLink=PagingLink(MainPageContent)[1] AllPagingDetail=[] ##爬取分页 PagingDetail=pool.map(Paging,TitleLink)
主要是用来调用各个函数的。。。(pool.map即为多线程方式爬取,因为我的电脑只有4核,所以最多只能4线程。。。)
四、保存爬取的信息:
for i in PagingDetail: for ii in i: AllPagingDetail.append(ii) abc=[] for ab in AllPagingDetail: abc.append(ab["内容"]) #把标题与链接存为表格 df=pandas.DataFrame(PagingLink(MainPageContent)[0]) df.to_csv("TitleAndLink.csv") #将回复等存为表格 dff=pandas.DataFrame(AllPagingDetail) dff.to_csv("AllPagingDetail.csv") #将回复存为文本 fo=open('content.txt','w',encoding='utf-8') fo.write(str(abc)) fo.close
存文本是为了好进行词云分析,至于为什么标题回复要存两个CSV文件。。。不能白爬!!!
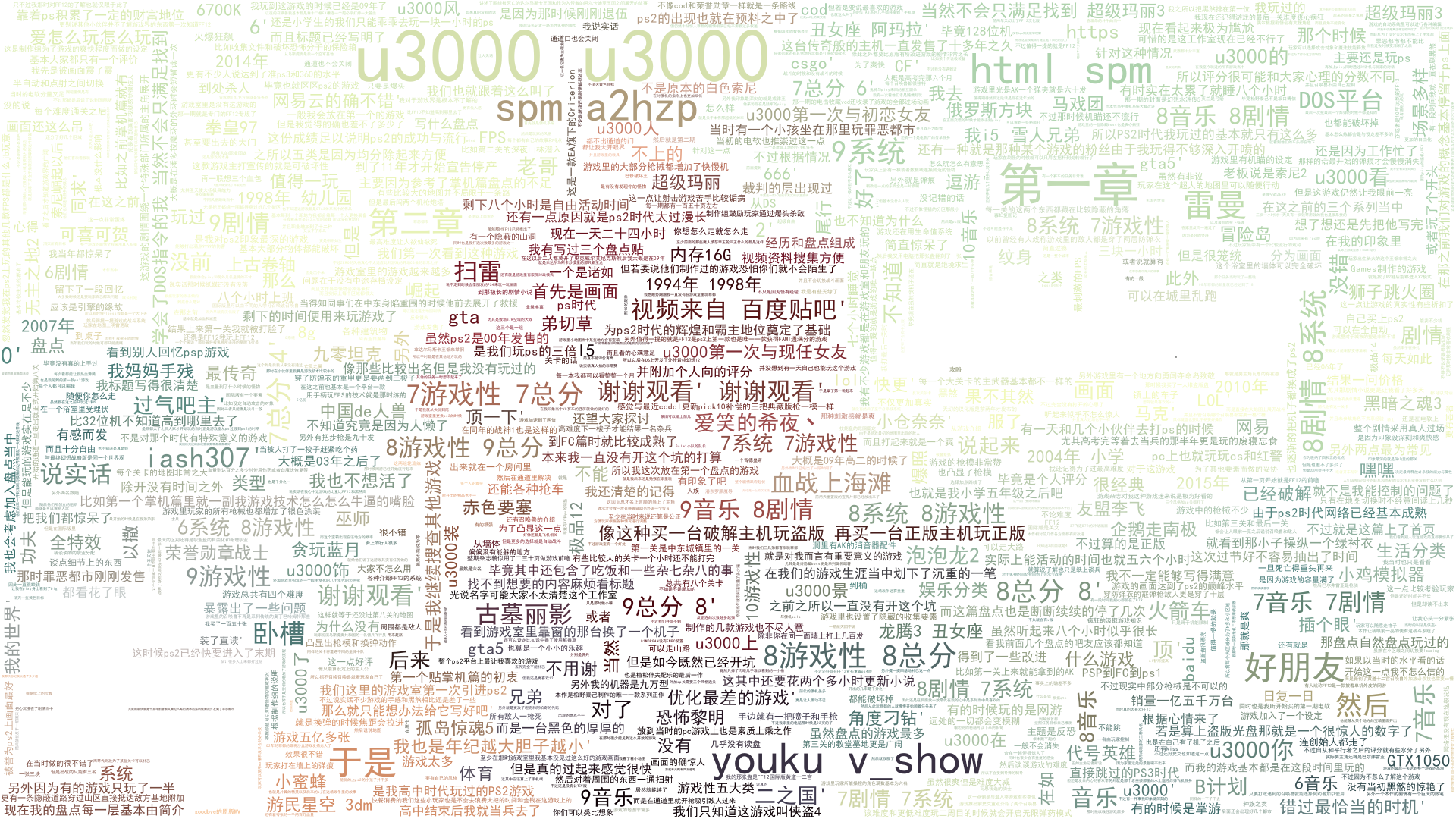
五、词云分析:
back_color = imread('01.jpg') # 解析该图片 wc = WordCloud(background_color='white', # 背景颜色 max_words=1000, # 最大词数 mask=back_color, # 以该参数值作图绘制词云,这个参数不为空时,width和height会被忽略 max_font_size=100, # 显示字体的最大值 stopwords=STOPWORDS.add(' '), # 使用内置的屏蔽词,再添加'苟利国' font_path="C:WindowsWinSxSamd64_microsoft-windows-font-truetype-simhei_31bf3856ad364e35_10.0.16299.15_none_1713e250e539567esimhei.ttf", # 解决显示口字型乱码问题,可进入C:/Windows/Fonts/目录更换字体 random_state=42, # 为每个词返回一个PIL颜色 # width=1000, # 图片的宽 # height=860 #图片的长 ) f = open('content.txt', 'r',encoding='utf-8').read() wc.generate(f) # 基于彩色图像生成相应彩色 image_colors = ImageColorGenerator(back_color) # 显示图片 plt.imshow(wc) # 关闭坐标轴 plt.axis('off') # 绘制词云 plt.figure() plt.imshow(wc.recolor(color_func=image_colors)) plt.axis('off') # 保存图片 wc.to_file('result.png')
在做个词云分析时,一直提示(”cannot open resource“),说明我解决汉字乱码的字体文件没导入成功,折腾许久,终于从系统的某个角落找到了可以用 的字体。。。。
六、所有代码:
# coding: utf-8 from multiprocessing.dummy import Pool as tp import requests from bs4 import BeautifulSoup import re import pandas import datetime import string import jieba from scipy.misc import imread # 这是一个处理图像的函数 from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator import matplotlib.pyplot as plt #爬取分页链接 def PagingLink(MainPage): #存放链接 TitleLink=[] TitleLinkMate=[] IndexTitle=[] for i in range(2): TitleLinkMate.append(re.findall('href="/p/(.*?)" title="(.*?)"',MainPage[i].text,re.S)) for temp in range(2): for i in TitleLinkMate[temp]: #存放标题与链接 TitleLinkItems={} TitleLinkItems["标题"]=str(i[1]) TitleLinkItems["链接"]="https://tieba.baidu.com/p/"+str(i[0]) TitleLink.append(TitleLinkItems["链接"]) IndexTitle.append(TitleLinkItems) return(IndexTitle,TitleLink) #爬取分页 def Paging(TitleLink): #爬虫伪装 head = {} head['user-agent']='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' PagingPage=requests.get(TitleLink,headers=head) PagingPage.encoding='utf-8' #分析分页并提取文章与回复 AnalysisResult=AnalysisPaging(PagingPage) return(AnalysisResult) #分析分页并提取文章与回复 def AnalysisPaging(PagingPage): PagingSoup=BeautifulSoup(PagingPage.text,'html.parser') AllReply=[] for i in PagingSoup.select("div.l_post.l_post_bright.j_l_post.clearfix"): if len(i)!=5: ReplyItems1={} #ID ReplyItems1["ID"]=i.select(".d_name")[0].text #内容 ReplyItems1["内容"]=i.select(".d_post_content")[0].text #时间 b=i.select(".tail-info") for y in i.select(".tail-info"): if len(re.findall("d+-d+-d+sd+:d+",y.text,re.S))>0: time1=datetime.datetime.strptime(y.text,'%Y-%m-%d %H:%M') ReplyItems1["时间"]=time1 #将字典1存入数组AllReply AllReply.append(ReplyItems1) return(AllReply) #爬取主页 def HomePage(HomePageUrl): #爬虫伪装 head = {} head['user-agent']='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' MainPage=requests.get(HomePageUrl,headers=head) MainPage.encoding='utf-8' return(MainPage) #生成主页链接 def HomePageUrlBuild(): HomePageUrl=[] for i in range(0,101,50): HomePageUrl.append("https://tieba.baidu.com/f?kw=%E5%8D%95%E6%9C%BA%E6%B8%B8%E6%88%8F&ie=utf-8&pn="+str(i)) return(HomePageUrl) #***************************************************************************************************************************** #函数入口 if __name__ == '__main__': #4线程 pool=tp(4) #主页链接 HomePageUrl=HomePageUrlBuild() print(HomePageUrl) #爬取主页 MainPageContent=pool.map(HomePage,HomePageUrl) #爬取分页链接 TitleLink=PagingLink(MainPageContent)[1] AllPagingDetail=[] ##爬取分页 PagingDetail=pool.map(Paging,TitleLink) for i in PagingDetail: for ii in i: AllPagingDetail.append(ii) abc=[] for ab in AllPagingDetail: abc.append(ab["内容"]) #把标题与链接存为表格 df=pandas.DataFrame(PagingLink(MainPageContent)[0]) df.to_csv("TitleAndLink.csv") #将回复等存为表格 dff=pandas.DataFrame(AllPagingDetail) dff.to_csv("AllPagingDetail.csv") #将回复存为文本 fo=open('content.txt','w',encoding='utf-8') fo.write(str(abc)) fo.close back_color = imread('01.jpg') # 解析该图片 wc = WordCloud(background_color='white', # 背景颜色 max_words=1000, # 最大词数 mask=back_color, # 以该参数值作图绘制词云,这个参数不为空时,width和height会被忽略 max_font_size=100, # 显示字体的最大值 stopwords=STOPWORDS.add(' '), # 使用内置的屏蔽词,再添加'苟利国' font_path="C:WindowsWinSxSamd64_microsoft-windows-font-truetype-simhei_31bf3856ad364e35_10.0.16299.15_none_1713e250e539567esimhei.ttf", # 解决显示口字型乱码问题,可进入C:/Windows/Fonts/目录更换字体 random_state=42, # 为每个词返回一个PIL颜色 # width=1000, # 图片的宽 # height=860 #图片的长 ) f = open('content.txt', 'r',encoding='utf-8').read() wc.generate(f) # 基于彩色图像生成相应彩色 image_colors = ImageColorGenerator(back_color) # 显示图片 plt.imshow(wc) # 关闭坐标轴 plt.axis('off') # 绘制词云 plt.figure() plt.imshow(wc.recolor(color_func=image_colors)) plt.axis('off') # 保存图片 wc.to_file('result.png')
#把标题与链接存为表格
df=pandas.DataFrame(PagingLink(MainPageContent)[0])
df.to_csv("TitleAndLink.csv")
#将回复等存为表格
dff=pandas.DataFrame(AllPagingDetail)
dff.to_csv("AllPagingDetail.csv")

#将回复存为文本
fo=open('content.txt','w',encoding='utf-8')
fo.write(str(abc))
fo.close

原图片01.jpg:

分析完的图片: