首先,复习一下索引的创建:
普通的索引的创建:
CREATE INDEX (自定义)索引名 ON 数据表(字段);
复合索引的创建:
CREATE INDEX (自定义)索引名 ON 数据表(字段,字段,。。。);
删除索引:DROP INDEX 索引名;
以下通过explain显示出mysql执行的字段内容:
-
id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.
-
select_type: SELECT 查询的类型.
-
table: 查询的是哪个表
-
partitions: 匹配的分区
-
type: join 类型
-
possible_keys: 此次查询中可能选用的索引
-
key: 此次查询中确切使用到的索引.
-
ref: 哪个字段或常数与 key 一起被使用
-
rows: 显示此查询一共扫描了多少行. 这个是一个估计值.
-
filtered: 表示此查询条件所过滤的数据的百分比
-
extra: 额外的信息
索引查询失效的几个情况:

2、or语句前后没有同时使用索引。当or左右查询字段只有一个是索引,该索引失效,只有当or左右查询字段均为索引时,才会生效


3、组合索引,不是使用第一列索引,索引失效。

4、数据类型出现隐式转化。如varchar不加单引号的话可能会自动转换为int型,使索引无效,产生全表扫描。
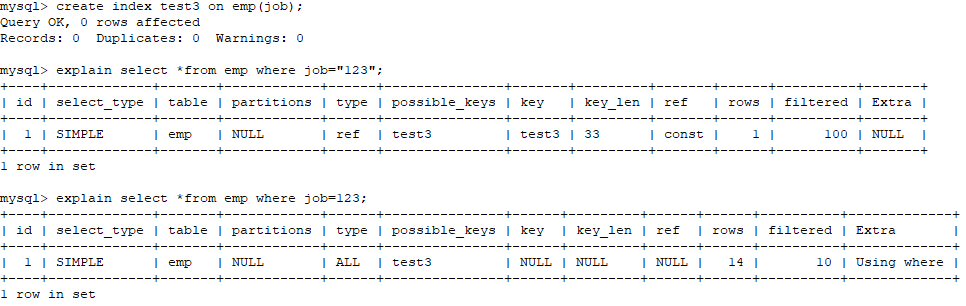
5、在索引列上使用 IS NULL 或 IS NOT NULL操作。索引是不索引空值的,所以这样的操作不能使用索引,可以用其他的办法处理,例如:数字类型,判断大于0,字符串类型设置一个默认值,判断是否等于默认值即可。(此处是错误的!)

解释以上错误:
此处我将重新创建一个emp表
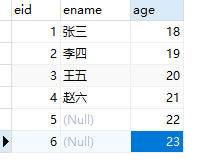
创建新的索引

查看索引

执行SQL语句


由此可发现有使用到索引
总结:在索引列上使用 IS NULL 或 IS NOT NULL操作,索引不一定失效!!!
使用联合查询请参考:https://www.jianshu.com/p/3cae3e364946
错误详解请参考:https://mp.weixin.qq.com/s/CEJFsDBizdl0SvugGX7UmQ
6、在索引字段上使用not,<>,!=。不等于操作符是永远不会用到索引的,因此对它的处理只会产生全表扫描。 优化方法: key<>0 改为 key>0 or key<0。


7、对索引字段进行计算操作、字段上使用函数。(索引为 emp(ename,empno,sal))


8、当全表扫描速度比索引速度快时,mysql会使用全表扫描,此时索引失效。
索引失效分析工具:
可以使用explain命令加在要分析的sql语句前面,在执行结果中查看key这一列的值,如果为NULL,说明没有使用索引。
explain命令的详细用法,可以查看这篇文章:https://segmentfault.com/a/1190000008131735