如果你希望系统性的了解神经网络,请参考零基础入门深度学习系列 ,下面我会粗略的介绍一下本文中实现神经网络需要了解的知识。
什么是深度神经网络?
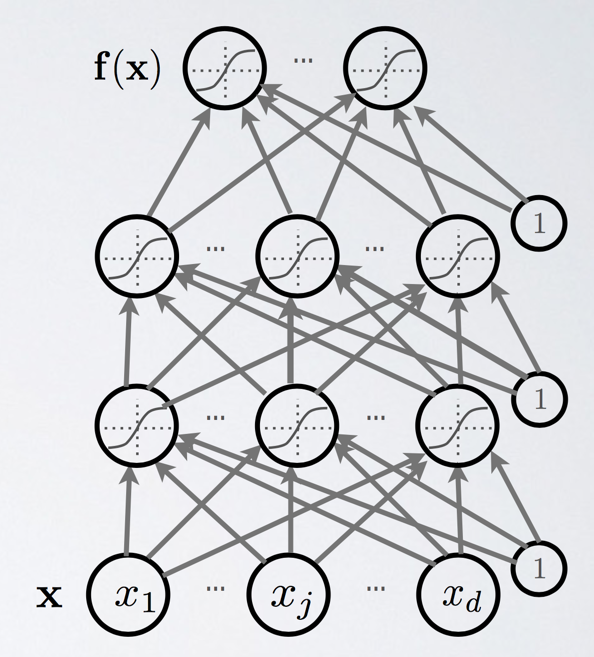
神经网络包含三层:输入层(X)、隐藏层和输出层:f(x)
每层之间每个节点都是完全连接的,其中包含权重(W)。每层都存在一个偏移值(b)。
每一层节点的计算方式如下:

其中g()代表激活函数,o()代表softmax输出函数。
使用Flow Graph的方式来表达如何正向推导神经网络,可以表达如下:
x: 输入值
a(x):表示每个隐藏层的pre-activation的数据,由前一个隐藏层数据(h)、权重(w)和偏移值(b)计算而来
h(x):表示每个隐藏层的数据
f(x):表示输出层数据

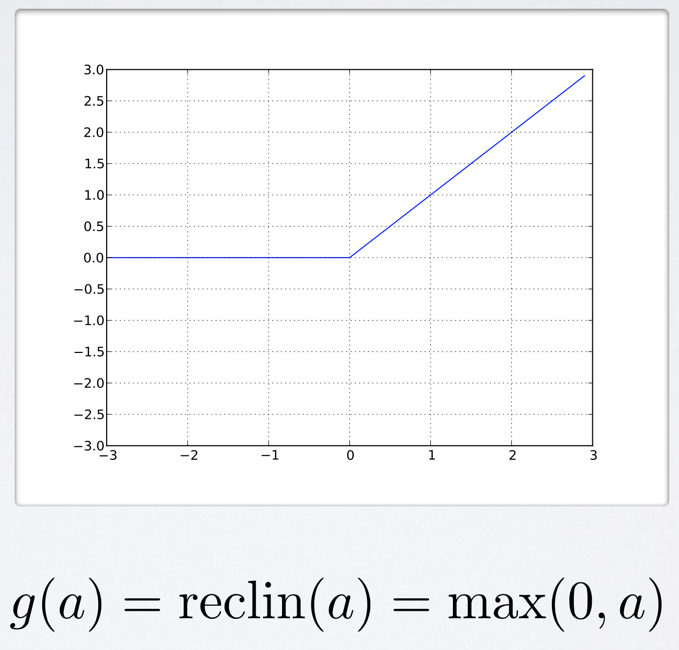
激活函数ReLUs
激活函数有很多种类,例如sigmoid、tanh、ReLUs,对于深度神经网络而言,目前最流行的是ReLUs。
关于几种激活函数的对比可以参见:常用激活函数的总结与比较
ReLUs函数如下:
反向传播
现在,我们需要知道一个神经网络的每个连接上的权值是如何得到的。我们可以说神经网络是一个模型,那么这些权值就是模型的参数,也就是模型要学习的东西。然而,一个神经网络的连接方式、网络的层数、每层的节点数这些参数,则不是学习出来的,而是人为事先设置的。对于这些人为设置的参数,我们称之为超参数(Hyper-Parameters)。
接下来,我们将要介绍神经网络的训练算法:反向传播算法。
具体内容请参考:零基础入门深度学习(3) - 神经网络和反向传播算法
SGD
梯度下降算法是一种不断调整参数值从而达到减少Loss function的方法,通过不断迭代而获得最佳的权重值。梯度下降传统上是每次迭代都使用全部训练数据来进行参数调整,随机梯度下降则是使用少量训练数据来进行调整。
关于GD和SGD的区别可以参考:GD(梯度下降)和SGD(随机梯度下降)
正则化和Dropout
正则化和Dropout都是一些防止过度拟合的方法,详细介绍可以参考:正则化方法:L1和L2 regularization、数据集扩增、dropout
正则化:通过在Loss function中加入对权重(w)的惩罚,可以限制权重值变得非常大

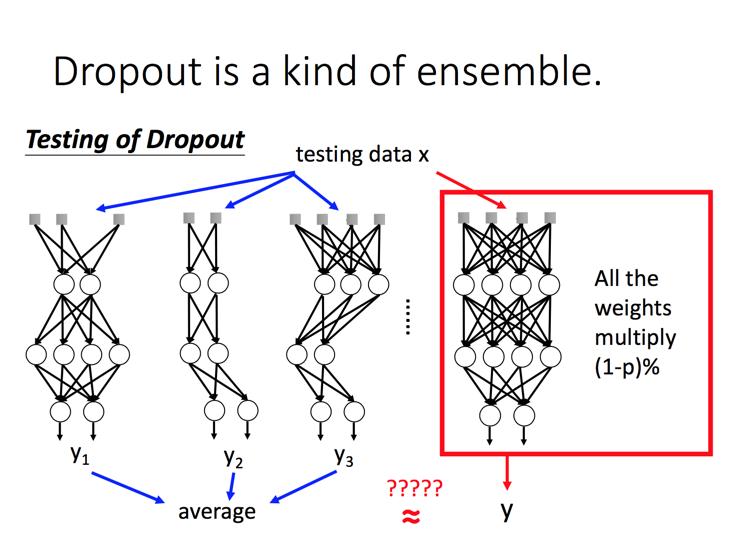
Dropout: 通过随机抛弃一些节点,使得神经网络更加多样性,然后组合起来获得的结果更加通用。
好吧,基本的概念大概介绍了一遍,开始撸代码啦。
请先参考深度学习实践系列(1)- 从零搭建notMNIST逻辑回归模型,获得notMNIST.pickle的训练数据。
1. 引用第三方库
# These are all the modules we'll be using later. Make sure you can import them # before proceeding further. from __future__ import print_function import numpy as np import tensorflow as tf from six.moves import cPickle as pickle from six.moves import range
2. 读取数据
pickle_file = 'notMNIST.pickle' with open(pickle_file, 'rb') as f: save = pickle.load(f) train_dataset = save['train_dataset'] train_labels = save['train_labels'] valid_dataset = save['valid_dataset'] valid_labels = save['valid_labels'] test_dataset = save['test_dataset'] test_labels = save['test_labels'] del save # hint to help gc free up memory print('Training set', train_dataset.shape, train_labels.shape) print('Validation set', valid_dataset.shape, valid_labels.shape) print('Test set', test_dataset.shape, test_labels.shape)
Training set (200000, 28, 28) (200000,) Validation set (10000, 28, 28) (10000,) Test set (10000, 28, 28) (10000,)
3. 调整数据格式以便后续训练
image_size = 28 num_labels = 10 def reformat(dataset, labels): dataset = dataset.reshape((-1, image_size * image_size)).astype(np.float32) # Map 0 to [1.0, 0.0, 0.0 ...], 1 to [0.0, 1.0, 0.0 ...] labels = (np.arange(num_labels) == labels[:,None]).astype(np.float32) return dataset, labels train_dataset, train_labels = reformat(train_dataset, train_labels) valid_dataset, valid_labels = reformat(valid_dataset, valid_labels) test_dataset, test_labels = reformat(test_dataset, test_labels) print('Training set', train_dataset.shape, train_labels.shape) print('Validation set', valid_dataset.shape, valid_labels.shape) print('Test set', test_dataset.shape, test_labels.shape)
Training set (200000, 784) (200000, 10) Validation set (10000, 784) (10000, 10) Test set (10000, 784) (10000, 10)
4. 定义神经网络
# With gradient descent training, even this much data is prohibitive. # Subset the training data for faster turnaround. train_subset = 10000 graph = tf.Graph() with graph.as_default(): # Input data. # Load the training, validation and test data into constants that are # attached to the graph. tf_train_dataset = tf.constant(train_dataset[:train_subset, :]) tf_train_labels = tf.constant(train_labels[:train_subset]) tf_valid_dataset = tf.constant(valid_dataset) tf_test_dataset = tf.constant(test_dataset) # Variables. # These are the parameters that we are going to be training. The weight # matrix will be initialized using random values following a (truncated) # normal distribution. The biases get initialized to zero. weights = tf.Variable( tf.truncated_normal([image_size * image_size, num_labels])) biases = tf.Variable(tf.zeros([num_labels])) # Training computation. # We multiply the inputs with the weight matrix, and add biases. We compute # the softmax and cross-entropy (it's one operation in TensorFlow, because # it's very common, and it can be optimized). We take the average of this # cross-entropy across all training examples: that's our loss. logits = tf.matmul(tf_train_dataset, weights) + biases loss = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(labels=tf_train_labels, logits=logits)) # Optimizer. # We are going to find the minimum of this loss using gradient descent. optimizer = tf.train.GradientDescentOptimizer(0.5).minimize(loss) # Predictions for the training, validation, and test data. # These are not part of training, but merely here so that we can report # accuracy figures as we train. train_prediction = tf.nn.softmax(logits) valid_prediction = tf.nn.softmax( tf.matmul(tf_valid_dataset, weights) + biases) test_prediction = tf.nn.softmax(tf.matmul(tf_test_dataset, weights) + biases)
5. 使用梯度下降(GD)训练神经网络
num_steps = 801 def accuracy(predictions, labels): return (100.0 * np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1)) / predictions.shape[0]) with tf.Session(graph=graph) as session: # This is a one-time operation which ensures the parameters get initialized as # we described in the graph: random weights for the matrix, zeros for the # biases. tf.global_variables_initializer().run() print('Initialized') for step in range(num_steps): # Run the computations. We tell .run() that we want to run the optimizer, # and get the loss value and the training predictions returned as numpy # arrays. _, l, predictions = session.run([optimizer, loss, train_prediction]) if (step % 100 == 0): print('Loss at step %d: %f' % (step, l)) print('Training accuracy: %.1f%%' % accuracy( predictions, train_labels[:train_subset, :])) # Calling .eval() on valid_prediction is basically like calling run(), but # just to get that one numpy array. Note that it recomputes all its graph # dependencies. print('Validation accuracy: %.1f%%' % accuracy( valid_prediction.eval(), valid_labels)) print('Test accuracy: %.1f%%' % accuracy(test_prediction.eval(), test_labels))
Initialized Loss at step 0: 16.516306 Training accuracy: 11.4% Validation accuracy: 11.7% Loss at step 100: 2.269041 Training accuracy: 71.8% Validation accuracy: 70.2% Loss at step 200: 1.816886 Training accuracy: 74.8% Validation accuracy: 72.6% Loss at step 300: 1.574824 Training accuracy: 76.0% Validation accuracy: 73.6% Loss at step 400: 1.415523 Training accuracy: 77.1% Validation accuracy: 73.9% Loss at step 500: 1.299691 Training accuracy: 78.0% Validation accuracy: 74.4% Loss at step 600: 1.209450 Training accuracy: 78.6% Validation accuracy: 74.6% Loss at step 700: 1.135888 Training accuracy: 79.0% Validation accuracy: 74.9% Loss at step 800: 1.074228 Training accuracy: 79.5% Validation accuracy: 75.0% Test accuracy: 82.3%
6. 使用随机梯度下降(SGD)算法
batch_size = 128 graph = tf.Graph() with graph.as_default(): # Input data. For the training data, we use a placeholder that will be fed # at run time with a training minibatch. tf_train_dataset = tf.placeholder(tf.float32, shape=(batch_size, image_size * image_size)) tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels)) tf_valid_dataset = tf.constant(valid_dataset) tf_test_dataset = tf.constant(test_dataset) # Variables. weights = tf.Variable( tf.truncated_normal([image_size * image_size, num_labels])) biases = tf.Variable(tf.zeros([num_labels])) # Training computation. logits = tf.matmul(tf_train_dataset, weights) + biases loss = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(labels=tf_train_labels, logits=logits)) # Optimizer. optimizer = tf.train.GradientDescentOptimizer(0.5).minimize(loss) # Predictions for the training, validation, and test data. train_prediction = tf.nn.softmax(logits) valid_prediction = tf.nn.softmax( tf.matmul(tf_valid_dataset, weights) + biases) test_prediction = tf.nn.softmax(tf.matmul(tf_test_dataset, weights) + biases) num_steps = 3001 with tf.Session(graph=graph) as session: tf.global_variables_initializer().run() print("Initialized") for step in range(num_steps): # Pick an offset within the training data, which has been randomized. # Note: we could use better randomization across epochs. offset = (step * batch_size) % (train_labels.shape[0] - batch_size) # Generate a minibatch. batch_data = train_dataset[offset:(offset + batch_size), :] batch_labels = train_labels[offset:(offset + batch_size), :] # Prepare a dictionary telling the session where to feed the minibatch. # The key of the dictionary is the placeholder node of the graph to be fed, # and the value is the numpy array to feed to it. feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels} _, l, predictions = session.run( [optimizer, loss, train_prediction], feed_dict=feed_dict) if (step % 500 == 0): print("Minibatch loss at step %d: %f" % (step, l)) print("Minibatch accuracy: %.1f%%" % accuracy(predictions, batch_labels)) print("Validation accuracy: %.1f%%" % accuracy( valid_prediction.eval(), valid_labels)) print("Test accuracy: %.1f%%" % accuracy(test_prediction.eval(), test_labels))
Initialized Minibatch loss at step 0: 18.121506 Minibatch accuracy: 11.7% Validation accuracy: 15.0% Minibatch loss at step 500: 1.192153 Minibatch accuracy: 80.5% Validation accuracy: 76.1% Minibatch loss at step 1000: 1.309419 Minibatch accuracy: 75.8% Validation accuracy: 76.8% Minibatch loss at step 1500: 0.739157 Minibatch accuracy: 83.6% Validation accuracy: 77.3% Minibatch loss at step 2000: 0.854160 Minibatch accuracy: 85.2% Validation accuracy: 77.5% Minibatch loss at step 2500: 1.045702 Minibatch accuracy: 76.6% Validation accuracy: 78.8% Minibatch loss at step 3000: 0.940078 Minibatch accuracy: 79.7% Validation accuracy: 78.8% Test accuracy: 85.8%
7. 使用ReLUs激活函数
batch_size = 128 hidden_layer_size = 1024 graph = tf.Graph() with graph.as_default(): # Input data. For the training data, we use a placeholder that will be fed # at run time with a training minibatch. tf_train_dataset = tf.placeholder(tf.float32, shape=(batch_size, image_size * image_size)) tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels)) tf_valid_dataset = tf.constant(valid_dataset) tf_test_dataset = tf.constant(test_dataset) # Variables. # Hidden layer (RELU magic) weights_hidden = tf.Variable( tf.truncated_normal([image_size * image_size, hidden_layer_size])) biases_hidden = tf.Variable(tf.zeros([hidden_layer_size])) hidden = tf.nn.relu(tf.matmul(tf_train_dataset, weights_hidden) + biases_hidden) # Output layer weights_output = tf.Variable( tf.truncated_normal([hidden_layer_size, num_labels])) biases_output = tf.Variable(tf.zeros([num_labels])) # Training computation. logits = tf.matmul(hidden, weights_output) + biases_output loss = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(labels=tf_train_labels, logits=logits)) # Optimizer. optimizer = tf.train.GradientDescentOptimizer(0.5).minimize(loss) # Predictions for the training, validation, and test data. # Creation of hidden layer of RELU for the validation and testing process train_prediction = tf.nn.softmax(logits) hidden_validation = tf.nn.relu(tf.matmul(tf_valid_dataset, weights_hidden) + biases_hidden) valid_prediction = tf.nn.softmax( tf.matmul(hidden_validation, weights_output) + biases_output) hidden_prediction = tf.nn.relu(tf.matmul(tf_test_dataset, weights_hidden) + biases_hidden) test_prediction = tf.nn.softmax(tf.matmul(hidden_prediction, weights_output) + biases_output) num_steps = 3001 def accuracy(predictions, labels): return (100.0 * np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1)) / predictions.shape[0]) with tf.Session(graph=graph) as session: tf.initialize_all_variables().run() print("Initialized") for step in range(num_steps): # Pick an offset within the training data, which has been randomized. # Note: we could use better randomization across epochs. offset = (step * batch_size) % (train_labels.shape[0] - batch_size) # Generate a minibatch. batch_data = train_dataset[offset:(offset + batch_size), :] batch_labels = train_labels[offset:(offset + batch_size), :] # Prepare a dictionary telling the session where to feed the minibatch. # The key of the dictionary is the placeholder node of the graph to be fed, # and the value is the numpy array to feed to it. feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels} _, l, predictions = session.run( [optimizer, loss, train_prediction], feed_dict=feed_dict) if (step % 500 == 0): print("Minibatch loss at step %d: %f" % (step, l)) print("Minibatch accuracy: %.1f%%" % accuracy(predictions, batch_labels)) print("Validation accuracy: %.1f%%" % accuracy( valid_prediction.eval(), valid_labels)) print("Test accuracy: %.1f%%" % accuracy(test_prediction.eval(), test_labels))
Initialized Minibatch loss at step 0: 282.291931 Minibatch accuracy: 14.1% Validation accuracy: 32.1% Minibatch loss at step 500: 18.090569 Minibatch accuracy: 82.0% Validation accuracy: 79.7% Minibatch loss at step 1000: 15.504422 Minibatch accuracy: 75.0% Validation accuracy: 80.8% Minibatch loss at step 1500: 5.314545 Minibatch accuracy: 87.5% Validation accuracy: 80.6% Minibatch loss at step 2000: 3.442260 Minibatch accuracy: 86.7% Validation accuracy: 81.5% Minibatch loss at step 2500: 2.226066 Minibatch accuracy: 83.6% Validation accuracy: 82.6% Minibatch loss at step 3000: 2.228517 Minibatch accuracy: 83.6% Validation accuracy: 82.5% Test accuracy: 89.6%
8. 正则化
import math batch_size = 128 hidden_layer_size = 1024 # Doubled because half of the results are discarded regularization_beta = 5e-4 graph = tf.Graph() with graph.as_default(): # Input data. For the training data, we use a placeholder that will be fed # at run time with a training minibatch. tf_train_dataset = tf.placeholder(tf.float32, shape=(batch_size, image_size * image_size)) tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels)) tf_valid_dataset = tf.constant(valid_dataset) tf_test_dataset = tf.constant(test_dataset) # Variables. # Hidden layer (RELU magic) weights_hidden_1 = tf.Variable( tf.truncated_normal([image_size * image_size, hidden_layer_size], stddev=1 / math.sqrt(float(image_size * image_size)))) biases_hidden_1 = tf.Variable(tf.zeros([hidden_layer_size])) hidden_1 = tf.nn.relu(tf.matmul(tf_train_dataset, weights_hidden_1) + biases_hidden_1) weights_hidden_2 = tf.Variable(tf.truncated_normal([hidden_layer_size, hidden_layer_size], stddev=1 / math.sqrt(float(image_size * image_size)))) biases_hidden_2 = tf.Variable(tf.zeros([hidden_layer_size])) hidden_2 = tf.nn.relu(tf.matmul(hidden_1, weights_hidden_2) + biases_hidden_2) # Output layer weights_output = tf.Variable( tf.truncated_normal([hidden_layer_size, num_labels], stddev=1 / math.sqrt(float(image_size * image_size)))) biases_output = tf.Variable(tf.zeros([num_labels])) # Training computation. logits = tf.matmul(hidden_2, weights_output) + biases_output loss = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(labels=tf_train_labels, logits=logits)) # L2 regularization on hidden and output weights and biases regularizers = (tf.nn.l2_loss(weights_hidden_1) + tf.nn.l2_loss(biases_hidden_1) + tf.nn.l2_loss(weights_hidden_2) + tf.nn.l2_loss(biases_hidden_2) + tf.nn.l2_loss(weights_output) + tf.nn.l2_loss(biases_output)) loss = loss + regularization_beta * regularizers # Optimizer. optimizer = tf.train.GradientDescentOptimizer(0.5).minimize(loss) # Predictions for the training, validation, and test data. # Creation of hidden layer of RELU for the validation and testing process train_prediction = tf.nn.softmax(logits) hidden_validation_1 = tf.nn.relu(tf.matmul(tf_valid_dataset, weights_hidden_1) + biases_hidden_1) hidden_validation_2 = tf.nn.relu(tf.matmul(hidden_validation_1, weights_hidden_2) + biases_hidden_2) valid_prediction = tf.nn.softmax( tf.matmul(hidden_validation_2, weights_output) + biases_output) hidden_prediction_1 = tf.nn.relu(tf.matmul(tf_test_dataset, weights_hidden_1) + biases_hidden_1) hidden_prediction_2 = tf.nn.relu(tf.matmul(hidden_prediction_1, weights_hidden_2) + biases_hidden_2) test_prediction = tf.nn.softmax(tf.matmul(hidden_prediction_2, weights_output) + biases_output) num_steps = 3001 def accuracy(predictions, labels): return (100.0 * np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1)) / predictions.shape[0]) with tf.Session(graph=graph) as session: tf.initialize_all_variables().run() print("Initialized") for step in range(num_steps): # Pick an offset within the training data, which has been randomized. # Note: we could use better randomization across epochs. offset = (step * batch_size) % (train_labels.shape[0] - batch_size) # Generate a minibatch. batch_data = train_dataset[offset:(offset + batch_size), :] batch_labels = train_labels[offset:(offset + batch_size), :] # Prepare a dictionary telling the session where to feed the minibatch. # The key of the dictionary is the placeholder node of the graph to be fed, # and the value is the numpy array to feed to it. feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels} _, l, predictions = session.run( [optimizer, loss, train_prediction], feed_dict=feed_dict) if (step % 500 == 0): print("Minibatch loss at step %d: %f" % (step, l)) print("Minibatch accuracy: %.1f%%" % accuracy(predictions, batch_labels)) print("Validation accuracy: %.1f%%" % accuracy( valid_prediction.eval(), valid_labels)) print("Test accuracy: %.1f%%" % accuracy(test_prediction.eval(), test_labels))
Initialized Minibatch loss at step 0: 2.769384 Minibatch accuracy: 8.6% Validation accuracy: 34.8% Minibatch loss at step 500: 0.735681 Minibatch accuracy: 89.1% Validation accuracy: 86.2% Minibatch loss at step 1000: 0.791112 Minibatch accuracy: 85.9% Validation accuracy: 86.9% Minibatch loss at step 1500: 0.523572 Minibatch accuracy: 93.0% Validation accuracy: 88.1% Minibatch loss at step 2000: 0.487140 Minibatch accuracy: 95.3% Validation accuracy: 88.5% Minibatch loss at step 2500: 0.529468 Minibatch accuracy: 89.8% Validation accuracy: 88.4% Minibatch loss at step 3000: 0.531258 Minibatch accuracy: 86.7% Validation accuracy: 88.9% Test accuracy: 94.7%
9. Dropout
import math batch_size = 128 hidden_layer_size = 2048 # Doubled because half of the results are discarded regularization_beta = 5e-4 graph = tf.Graph() with graph.as_default(): # Input data. For the training data, we use a placeholder that will be fed # at run time with a training minibatch. tf_train_dataset = tf.placeholder(tf.float32, shape=(batch_size, image_size * image_size)) tf_train_labels = tf.placeholder(tf.float32, shape=(batch_size, num_labels)) tf_valid_dataset = tf.constant(valid_dataset) tf_test_dataset = tf.constant(test_dataset) # Variables. # Hidden layer (RELU magic) weights_hidden_1 = tf.Variable( tf.truncated_normal([image_size * image_size, hidden_layer_size], stddev=1 / math.sqrt(float(image_size * image_size)))) biases_hidden_1 = tf.Variable(tf.zeros([hidden_layer_size])) hidden_1 = tf.nn.relu(tf.matmul(tf_train_dataset, weights_hidden_1) + biases_hidden_1) weights_hidden_2 = tf.Variable(tf.truncated_normal([hidden_layer_size, hidden_layer_size], stddev=1 / math.sqrt(float(image_size * image_size)))) biases_hidden_2 = tf.Variable(tf.zeros([hidden_layer_size])) hidden_2 = tf.nn.relu(tf.matmul(tf.nn.dropout(hidden_1, 0.5), weights_hidden_2) + biases_hidden_2) # Output layer weights_output = tf.Variable( tf.truncated_normal([hidden_layer_size, num_labels], stddev=1 / math.sqrt(float(image_size * image_size)))) biases_output = tf.Variable(tf.zeros([num_labels])) # Training computation. logits = tf.matmul(tf.nn.dropout(hidden_2, 0.5), weights_output) + biases_output loss = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(labels=tf_train_labels, logits=logits)) # L2 regularization on hidden and output weights and biases regularizers = (tf.nn.l2_loss(weights_hidden_1) + tf.nn.l2_loss(biases_hidden_1) + tf.nn.l2_loss(weights_hidden_2) + tf.nn.l2_loss(biases_hidden_2) + tf.nn.l2_loss(weights_output) + tf.nn.l2_loss(biases_output)) loss = loss + regularization_beta * regularizers # Optimizer. optimizer = tf.train.GradientDescentOptimizer(0.5).minimize(loss) # Predictions for the training, validation, and test data. # Creation of hidden layer of RELU for the validation and testing process train_prediction = tf.nn.softmax(logits) hidden_validation_1 = tf.nn.relu(tf.matmul(tf_valid_dataset, weights_hidden_1) + biases_hidden_1) hidden_validation_2 = tf.nn.relu(tf.matmul(hidden_validation_1, weights_hidden_2) + biases_hidden_2) valid_prediction = tf.nn.softmax( tf.matmul(hidden_validation_2, weights_output) + biases_output) hidden_prediction_1 = tf.nn.relu(tf.matmul(tf_test_dataset, weights_hidden_1) + biases_hidden_1) hidden_prediction_2 = tf.nn.relu(tf.matmul(hidden_prediction_1, weights_hidden_2) + biases_hidden_2) test_prediction = tf.nn.softmax(tf.matmul(hidden_prediction_2, weights_output) + biases_output) num_steps = 5001 def accuracy(predictions, labels): return (100.0 * np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1)) / predictions.shape[0]) with tf.Session(graph=graph) as session: tf.initialize_all_variables().run() print("Initialized") for step in range(num_steps): # Pick an offset within the training data, which has been randomized. # Note: we could use better randomization across epochs. offset = (step * batch_size) % (train_labels.shape[0] - batch_size) # Generate a minibatch. batch_data = train_dataset[offset:(offset + batch_size), :] batch_labels = train_labels[offset:(offset + batch_size), :] # Prepare a dictionary telling the session where to feed the minibatch. # The key of the dictionary is the placeholder node of the graph to be fed, # and the value is the numpy array to feed to it. feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels} _, l, predictions = session.run( [optimizer, loss, train_prediction], feed_dict=feed_dict) if (step % 500 == 0): print("Minibatch loss at step %d: %f" % (step, l)) print("Minibatch accuracy: %.1f%%" % accuracy(predictions, batch_labels)) print("Validation accuracy: %.1f%%" % accuracy( valid_prediction.eval(), valid_labels)) print("Test accuracy: %.1f%%" % accuracy(test_prediction.eval(), test_labels))
WARNING:tensorflow:From <ipython-input-12-3684c7218154>:8: initialize_all_variables (from tensorflow.python.ops.variables) is deprecated and will be removed after 2017-03-02. Instructions for updating: Use `tf.global_variables_initializer` instead. Initialized Minibatch loss at step 0: 4.059163 Minibatch accuracy: 7.8% Validation accuracy: 31.5% Minibatch loss at step 500: 1.626858 Minibatch accuracy: 86.7% Validation accuracy: 84.8% Minibatch loss at step 1000: 1.492026 Minibatch accuracy: 82.0% Validation accuracy: 85.8% Minibatch loss at step 1500: 1.139689 Minibatch accuracy: 92.2% Validation accuracy: 87.1% Minibatch loss at step 2000: 0.970064 Minibatch accuracy: 93.0% Validation accuracy: 87.1% Minibatch loss at step 2500: 0.963178 Minibatch accuracy: 87.5% Validation accuracy: 87.6% Minibatch loss at step 3000: 0.870884 Minibatch accuracy: 87.5% Validation accuracy: 87.6% Minibatch loss at step 3500: 0.898399 Minibatch accuracy: 85.2% Validation accuracy: 87.7% Minibatch loss at step 4000: 0.737084 Minibatch accuracy: 91.4% Validation accuracy: 88.0% Minibatch loss at step 4500: 0.646125 Minibatch accuracy: 88.3% Validation accuracy: 87.7% Minibatch loss at step 5000: 0.685591 Minibatch accuracy: 88.3% Validation accuracy: 88.6% Test accuracy: 94.4%
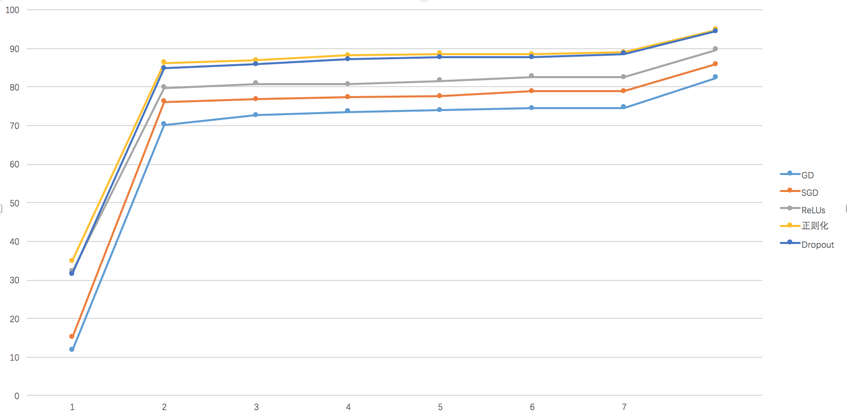
最后总结一下各种算法的训练表现,可以看出使用正则化和Dropout后训练效果明显变好,最后趋近于95%的准确率了。