python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

Chunking with NLTK
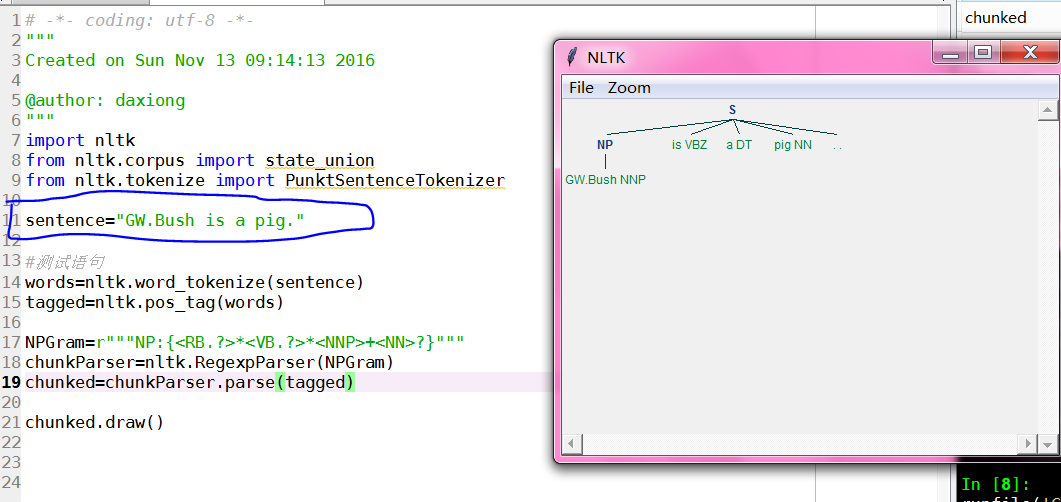
对chunk分类数据结构可以图形化输出,用于分析英语句子主干结构
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 13 09:14:13 2016
@author: daxiong
"""
import nltk
sentence="GW.Bush is a big pig."
#切分单词
words=nltk.word_tokenize(sentence)
#词性标记
tagged=nltk.pos_tag(words)
#正则表达式,定义包含所有名词的re
NPGram=r"""NP:{<NNP>|<NN>|<NNS>|<NNPS>}"""
chunkParser=nltk.RegexpParser(NPGram)
chunked=chunkParser.parse(tagged)
#树状图展示
chunked.draw()
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 13 09:14:13 2016
@author: daxiong
"""
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
#训练数据
train_text=state_union.raw("2005-GWBush.txt")
#测试数据
sample_text=state_union.raw("2006-GWBush.txt")
'''
Punkt is designed to learn parameters (a list of abbreviations, etc.)
unsupervised from a corpus similar to the target domain.
The pre-packaged models may therefore be unsuitable:
use PunktSentenceTokenizer(text) to learn parameters from the given text
'''
#我们现在训练punkttokenizer(分句器)
custom_sent_tokenizer=PunktSentenceTokenizer(train_text)
#训练后,我们可以使用punkttokenizer(分句器)
tokenized=custom_sent_tokenizer.tokenize(sample_text)
'''
nltk.pos_tag(["fire"]) #pos_tag(列表)
Out[19]: [('fire', 'NN')]
'''
words=nltk.word_tokenize(tokenized[0])
tagged=nltk.pos_tag(words)
chunkGram=r"""Chunk:{<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser=nltk.RegexpParser(chunkGram)
chunked=chunkParser.parse(tagged)
#lambda t:t.label()=='Chunk' 包含Chunk标签的列
for subtree in chunked.subtrees(filter=lambda t:t.label()=='Chunk'):
print(subtree)
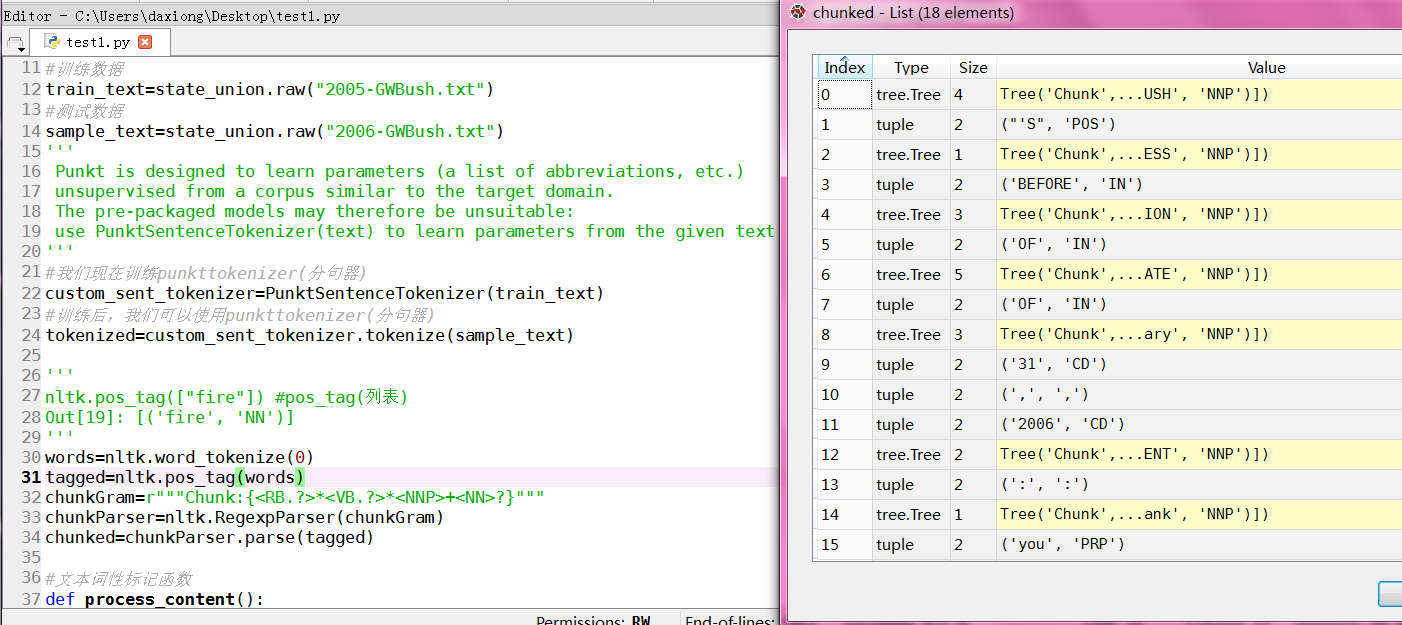
数据类型:chunked 是树结构
#lambda t:t.label()=='Chunk' 包含Chunk标签的列
输出只包含Chunk标签的列

完整代码
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 13 09:14:13 2016
@author: daxiong
"""
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
#训练数据
train_text=state_union.raw("2005-GWBush.txt")
#测试数据
sample_text=state_union.raw("2006-GWBush.txt")
'''
Punkt is designed to learn parameters (a list of abbreviations, etc.)
unsupervised from a corpus similar to the target domain.
The pre-packaged models may therefore be unsuitable:
use PunktSentenceTokenizer(text) to learn parameters from the given text
'''
#我们现在训练punkttokenizer(分句器)
custom_sent_tokenizer=PunktSentenceTokenizer(train_text)
#训练后,我们可以使用punkttokenizer(分句器)
tokenized=custom_sent_tokenizer.tokenize(sample_text)
'''
nltk.pos_tag(["fire"]) #pos_tag(列表)
Out[19]: [('fire', 'NN')]
'''
'''
#测试语句
words=nltk.word_tokenize(tokenized[0])
tagged=nltk.pos_tag(words)
chunkGram=r"""Chunk:{<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser=nltk.RegexpParser(chunkGram)
chunked=chunkParser.parse(tagged)
#lambda t:t.label()=='Chunk' 包含Chunk标签的列
for subtree in chunked.subtrees(filter=lambda t:t.label()=='Chunk'):
print(subtree)
'''
#文本词性标记函数
def process_content():
try:
for i in tokenized[0:5]:
words=nltk.word_tokenize(i)
tagged=nltk.pos_tag(words)
#RB副词,VB动词,NNP专有名词单数形式,NN单数名词
chunkGram=r"""Chunk:{<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser=nltk.RegexpParser(chunkGram)
chunked=chunkParser.parse(tagged)
#print(chunked)
for subtree in chunked.subtrees(filter=lambda t:t.label()=='Chunk'):
print(subtree)
#chunked.draw()
except Exception as e:
print(str(e))
process_content()
得到所有名词分类
Now that we know the parts of speech, we can do what is called chunking, and group words into hopefully meaningful chunks. One of the main goals of chunking is to group into what are known as "noun phrases." These are phrases of one or more words that contain a noun, maybe some descriptive words, maybe a verb, and maybe something like an adverb. The idea is to group nouns with the words that are in relation to them.
In order to chunk, we combine the part of speech tags with regular expressions. Mainly from regular expressions, we are going to utilize the following:
+ = match 1 or more
? = match 0 or 1 repetitions.
* = match 0 or MORE repetitions
. = Any character except a new line
See the tutorial linked above if you need help with regular expressions. The last things to note is that the part of speech tags are denoted with the "<" and ">" and we can also place regular expressions within the tags themselves, so account for things like "all nouns" (<N.*>)
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
The result of this is something like:
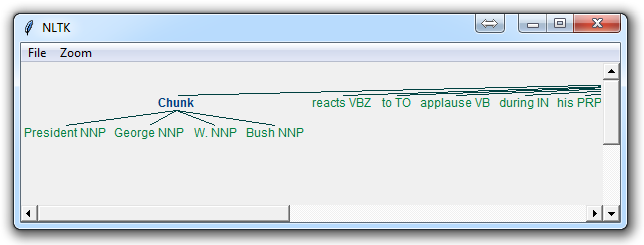
The main line here in question is:
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
This line, broken down:
<RB.?>* = "0 or more of any tense of adverb," followed by:
<VB.?>* = "0 or more of any tense of verb," followed by:
<NNP>+ = "One or more proper nouns," followed by
<NN>? = "zero or one singular noun."
Try playing around with combinations to group various instances until you feel comfortable with chunking.
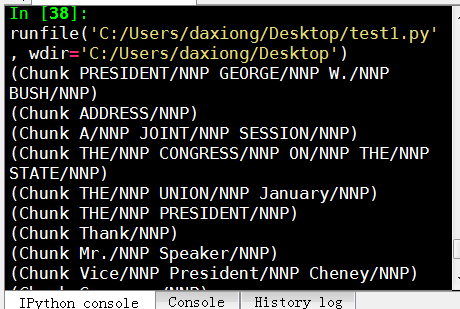
Not covered in the video, but also a reasonable task is to actually access the chunks specifically. This is something rarely talked about, but can be an essential step depending on what you're doing. Say you print the chunks out, you are going to see output like:
(S
(Chunk PRESIDENT/NNP GEORGE/NNP W./NNP BUSH/NNP)
'S/POS
(Chunk
ADDRESS/NNP
BEFORE/NNP
A/NNP
JOINT/NNP
SESSION/NNP
OF/NNP
THE/NNP
CONGRESS/NNP
ON/NNP
THE/NNP
STATE/NNP
OF/NNP
THE/NNP
UNION/NNP
January/NNP)
31/CD
,/,
2006/CD
THE/DT
(Chunk PRESIDENT/NNP)
:/:
(Chunk Thank/NNP)
you/PRP
all/DT
./.)
Cool, that helps us visually, but what if we want to access this data via our program? Well, what is happening here is our "chunked" variable is an NLTK tree. Each "chunk" and "non chunk" is a "subtree" of the tree. We can reference these by doing something like chunked.subtrees. We can then iterate through these subtrees like so:
for subtree in chunked.subtrees():
print(subtree)
Next, we might be only interested in getting just the chunks, ignoring the rest. We can use the filter parameter in the chunked.subtrees() call.
for subtree in chunked.subtrees(filter=lambda t: t.label() == 'Chunk'):
print(subtree)
Now, we're filtering to only show the subtrees with the label of "Chunk." Keep in mind, this isn't "Chunk" as in the NLTK chunk attribute... this is "Chunk" literally because that's the label we gave it here: chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
Had we said instead something like chunkGram = r"""Pythons: {<RB.?>*<VB.?>*<NNP>+<NN>?}""", then we would filter by the label of "Pythons." The result here should be something like:
- (Chunk PRESIDENT/NNP GEORGE/NNP W./NNP BUSH/NNP) (Chunk ADDRESS/NNP BEFORE/NNP A/NNP JOINT/NNP SESSION/NNP OF/NNP THE/NNP CONGRESS/NNP ON/NNP THE/NNP STATE/NNP OF/NNP THE/NNP UNION/NNP January/NNP) (Chunk PRESIDENT/NNP) (Chunk Thank/NNP)
Full code for this would be:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
print(chunked)
for subtree in chunked.subtrees(filter=lambda t: t.label() == 'Chunk'):
print(subtree)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
If you get particular enough, you may find that you may be better off if there was a way to chunk everything, except some stuff. This process is what is known as chinking, and that's what we're going to be covering next.
