python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

机器学习,统计项目合作QQ:231469242
http://baike.baidu.com/link?url=YFVbJFMkZO9A5CAvtCoKbI609HxXXSFd8flFG_LgB8OMhmiNOn7jqkgApvBwKr2f-QnngydyCazha3sA3y3Px8WZm-KvV67yMhvwztM4XS_
普林斯顿大学--wordnet官网
http://wordnet.princeton.edu/
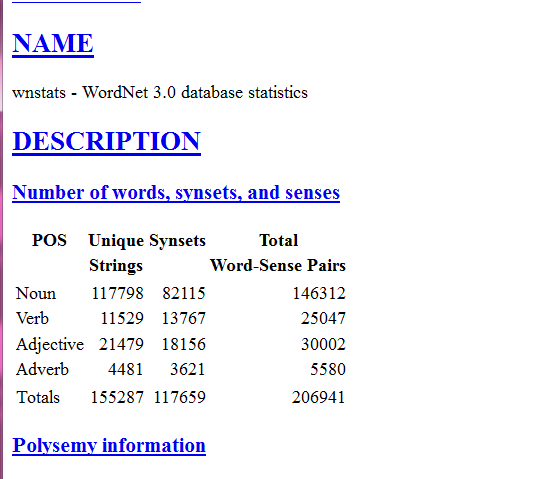
普林斯顿大学对核心单词统计,总体核心词15万左右,其他都是变体或合成词
http://wordnet.princeton.edu/wordnet/man/wnstats.7WN.html
WordNet是由Princeton 大学的心理学家,语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典。它不是光把单词以字母顺序排列,而且按照单词的意义组成一个“单词的网络”。
- 外文名
- WordNet
- 机 构
- Princeton 大学
- 类 型
- 英语词典
- 依 据
- 认知语言学
简介
编辑它是一个覆盖范围宽广的英语词汇语义网。名词,动词,形容词和副词各自被组织成一个同义词的网络,每个同义词集合都代
 表一个基本的语义概念,并且这些集合之间也由各种关系连接。(一个多义词将出现在它的每个意思的同义词集合中)。在WordNet的第一版中 (标记为1.x),四种不同词性的网络之间并无连接。WordNet的名词网络是第一个发展起来的,正因如此,我们下面将要讨论的大部分学者的工作都仅限 于名词网络。
表一个基本的语义概念,并且这些集合之间也由各种关系连接。(一个多义词将出现在它的每个意思的同义词集合中)。在WordNet的第一版中 (标记为1.x),四种不同词性的网络之间并无连接。WordNet的名词网络是第一个发展起来的,正因如此,我们下面将要讨论的大部分学者的工作都仅限 于名词网络。
名词网络的主干是蕴涵关系的层次(上位/下位关系),它占据了关系中的将 近80%。层次中的最顶层是11个抽象概念,称为基本类别始点(unique beginners),例如实体(entity,“有生命的或无生命的具体存在”),心理特征(psychological feature,“生命有机体的精神上的特征)。名词层次中最深的层次是16个节点。
详细介绍
编辑"WordNet: An Electronic Lexical Database"一书分三部分,16章。第一部分从第1章到第4章,前3章分别介绍WordNet中的名词,形容词,动词,第4章介绍WordNet的 设计细节及相关软件的情况(这主要是由普林斯顿大学认知科学实验室的研究人员写的);第二部分和第三部分主要是由普林斯顿认知科学实验室之外的参加 WordNet研究工作的研究人员撰写的。第5章和第6章描述了WordNet的改进;第7章从形式化的概念分析的角度描述了WordNet;第8到第 16章讨论了WordNet的各种不同应用。
(一)计算机与词库(computers and lexicon)
· 一个人即使不接受把人脑比作计算机的隐喻,也一定同意,计算机提供了一个良好的模式演练场,通过它,人们可以测试各种关于人类认知能力的理论模型。
· 越来越多的人认识到,一个大的词库对自然语言理解,人工智能的各方面研究都具有重要的价值。
· 对大规模机器可读词典的需求同时也带来许多基础问题。首先是如何构造这样一个词库,是手工编制还是机器自动生成?第二,词典中应包含什么样的信息?第三, 词典应如何设计,即信息如何组织,以及用户如何访问?实际上,这些问题涉及到词典的编纂方法,词典的内容,词典的使用方式这一系列非常基础的问题。
(二)构造词库数据库(constructing the lexical database)
· 构建词典的两种基本方式:自动获取 / 手工编制。
手工构建词典的优点之一是便于创建更为丰富的词条信息;其次是便于控制。
(三)WordNet的内容
· WordNet的描述对象包含compound(复合词)、phrasal verb(短语
动词)、collocation(搭配词)、idiomatic phrase(成语)、word(单词),其中word是最基本的单位。
· WordNet并不把词语分解成更小的有意义的单位(这是义素分析法/componential analyses的方法);WordNet也不包含比词更大的组织单位(如脚本、框架之类的单位);由于WordNet把4个开放词类区分为不同文件加以 处理,因而WordNet中也不包含词语的句法信息内容;WordNet包含紧凑短语,如bad person,这样的语言成分不能被作为单个词来加以解释。
· 人们经常区分词语知识和世界知识。前者体现在词典中,后者体现在百科全书中。事实上二者的界限是模糊的。比如hit(“打”)某人是一种带有敌意的行为, 这是百科知识;而hit跟strike(“击”)多多少少同义,并且hit可以带一个直接宾语论元,这是词语知识。但hit的直接宾语应该是固体(而不是 像gas这样的气体),这是词语知识还是百科知识就界限模糊了。不过毫无疑问,要理解语言,这两部分知识是缺一不可的。Kay(1989)指出我们的大脑 词库应该包含这两部分知识。但是百科知识太多难以驾驭,WordNet不试图包括百科知识。不过,在WordNet中,对于一些不常见的专业概念,比如不 常见的植物和动物,词语知识和百科知识是融合在一起的。
(四)WordNet的设计(the design of WordNet)
· 一般的词典都是按照单词拼写的正字法原则进行组织的。但如果为了获得词语意义信息的目的,通过词语语义属性来组织词典就更值得去做了。在线词典跟传统的纸张词典不同,允许使用者从不同的途径去访问词典信息。
· 第一个以意义作为组织原则的词典是罗杰斯同义词词林(Roget's Thesaurus)。传统的词典是通过提供给用户关于词语的信息来帮助用户理解那些他们不熟悉的词的概念意义。WordNet既非传统词典,也非同义词词林。它混合了这两种类型的词典。
(五)作为同义词词林的WordNet (WordNet as a thesaurus)
· WordNet跟同义词词林相似的地方是:它也是以同义词集合(synset)作为基本建构单位进行组织的。用户脑子里如果有一个已知的概念,就可以在同义词集合中中找到一个适合的词去表达这个概念。
· 但WordNet不仅仅是用同义词集合的方式罗列概念。同义词集合之间是以一定数量的关系类型相关联的。这些关系包括上下位关系、整体部分关系、
继承关系等。
(六)作为一般词典的WordNet (WordNet as a dictionary)
· WordNet跟传统的词典相似的地方是它给出了同义词集合的定义以及例句。在同义词集合中包含对这些同义词的定义。对一个同义词集合中的不同的词,分别给出适合的例句来加以区分。
(七)WordNet中的关系 (relations in WordNet)
· 不同句法词类中的语义关系类型也不同,比如尽管名词都动词都是分层级组织词语之间的语义关系,但在名词中,上下位关系是hyponymy关系,而动词中是 troponymy关系;动词中的entailment(继承)关系有些类似名词中的meronymy(整体部分)关系。名词的meronymy关系下面 还分出三种类型的子关系(见“WordNet中的名词”部分)。
(八)网球问题(the tennis problem)
· WordNet是基于同义性和反义(对义)性来描述词语和概念之间的各种语义关系类型的。由于WordNet的注意力不是在文本和话语篇章水平上来描述词 和概念的语义,因此WordNet中没有包含指示词语在特定的篇章话题领域的相关概念关系。例如,WordNet中没有将racquet(网球拍)、 ball(球)、net(球网)等词语以一定方式联系到一起。Roger Chaffin在一封私人信笺中,曾把这类问题称为“tennis problem”(网球问题),指的就是如何把racquet、ball、net、court game(场地比赛);或者把physician(内科医生)跟hospital(医院)联系到一起。这对电子词典来说,是一个挑战。已经有一些相关的研 究工作在探索如何从WordNet中包含的词汇和概念之间的语义关系,来推导出话题信息。Hirst和St-Onge描述了一种所谓的“词汇链” (lexical chain)的应用方法。“词汇链”是在基于名词的语义关系构成的上下文中的名词的序列。Al-Halimi和Kazman则在类似的基础上构造“词汇 树”(lexical tree)来推导出话题信息。
(九)新的观点,改进,应用 (new perspectives, enhancements, and applications)
· 许多WordNet的用户都对WordNet中缺乏跟语义处理的细节相匹配的句法信息而感到遗憾。的确,WordNet中几乎没有句法信息,因为它是作为 一个语义知识库构建的。但是,对形容词的部分句法约束信息是包含在WordNet中的(考虑形容词跟中心名词的关系,以及形容词作为属性形容词作表语使用 的情况)。句法对动词而言最为重要,对此,可以通过动词的名词论元、介词短语以及义素组成等不同来加以次范畴化(分出动词小类)。目前,WordNet的 每个动词同义词集中包含了及物性和论元类型的基本信息,但有关这些论元的性质的细节就很少提到。知识工程以及推理方面的应用系统特别受益于动名间关系的信 息。WordNet的一些用户依靠其他一些语法知识库,像COMLEX,来配合WordNet中的语义信息一道使用。事实上,有关动词的句法信息和语义信 息的区分基本是人为的。Levin(1985,1993)已经收集了令人印象深刻的证据来说明动词的语义性质跟其句法行为之间的紧密联系。
(十)词语和它的上下文 (words and their contexts)
· 为了提供词语的语境信息,普林斯顿(Princeton)认知科学实验室开发了一个语义检索工具(semantic concordance)——见《WordNet》一书第8章。该工具将文本和词库组成一个整体的数据库,从而使文本中的单词跟词库中合适的意义相关联。 这样的语义检索工具,既可以看作是这样一个文本,其中的单词带有句法和语义信息的标注;也可以看作是一个词库,其中的词条都配有指示义项用法环境的例句。 跟WordNet语义词库配合的文本是来自Brown语料库的语料(当代美国英语标准语料库)以及一个中短篇小说的全文(the complete text of a novella)。
(十一)意义排歧 (sense disambiguation)
· 尽管我们很清楚,在确定的上下文中,说者赋予多义词确定的一个意义,但排歧的过程并不容易。对计算机而言,排歧需要多大的语境就是一个大问题。
· Leacock和Chodorow(见《WordNet》一书第11章)测试了对多义动词“serve”进行多义词歧义消解的不同策略。在三个试验中,他 们发现,选择上下文的“窗口”大小为6个词比较适宜,所得结果最优;此外,当将上下文信息和WordNet中有关词语之间语义相似度的信息结合在一起使用 时,排歧准确度最高。
(十二)信息检索 (information retrieval)
· 意义排歧对许多应用来说都是关键因素,比如信息检索就是这样的应用领域。Voorhees(见《WordNet》一书第12章)解释说,要在大量文献中发 现所需的文档,计算机就要在被查询词语和文档标题或摘要之间进行有效地匹配操作。Voorhees探讨了WordNet在词语匹配方面的效力,发现意义分 辨方面的困难阻碍了有效利用WordNet中的语义信息。只有先依靠手工选择了概念,使得要查找的词语的意义已知,这种情况下,WordNet中的语义关 系信息才对提高检索结果有帮助。
(十三)语义关系与文本连贯性 (semantic relations and textual coherence)
· Hirst 和 St-Onge(见《WordNet》第13章)也讨论了上下文的问题,尤其是一个连贯的文本是如何组成的。基于语篇是由意义相关的概念串联起来的假设, 他们使用了“词汇链”(lexical chain)概念作为评估连贯性的一种方式。Hirst和St-Onge采用词汇链来检查文本中的用词错误情况(malapropism)。他们把用词错 误定义为:一个词所对应的概念跟该词所在的文本中的其他词所对应的概念无关。利用评估一个词汇链中链接强度的方法,Hirst和St-Onge认为,文本 中词语之间的语义距离越大,出现用词错误问题的可能性也越大。
· Al-Halimi和Kazman也对信息存贮,索引,检索等问题感兴趣(见《WordNet》第14章)。他们描述了一种自动对视频会议的脚本按照话题 进行索引的方法(不是按照关键词索引),以及利用话题索引结果,通过匹配对脚本进行信息检索。Al-Halimi和Kazman将话题信息描述为“词汇 树”(lexical tree)——这是对“词汇链”的一个修正。前者对后者的革新之一是考虑了不同的语义关系类型的信息相关性。
· Hirst和St-Onge指出,WordNet缺乏有关两个相关词之间语义距离的信息。他们举的例子是:more stew than steak(焖肉比牛排多),其中“more ... than”是一个格式,用来连接两个语义上相关的词语。在这个例子中,两个名词(stew和steak)分属6个同义词集合(synset),显然这无法 反映出它们真实的语义距离。说英语的人知道“good person”(好人,圣人)的两个上下位概念之间语义上是非常相似的。这两个上下位概念分别是{saint, holy man, holy person, angel},{plaster saint},而且这两个概念之间的相似性与它们跟第三个下位概念之间的相似性不同。第三个下位概念是{square shooter, straight arrow}(正人君子)。
(十四)知识工程 (knowledge engineering)
· WordNet的诸多应用中,最具雄心壮志的也许是知识工程(见《WordNet》一书第15,16章)。
· Harabagiu和Moldovan(见《WordNet》一书第16章)指出,为常识推理建模需要一个扩展的知识库,其中包括数量巨大的概念和关系。 WordNet提供了前者,但在关系方面不足以支持推理。他们的解决方案是对WordNet中的注释进行排歧,得到词语之间的更多关系,从而将 WordNet中的注释转变为语义网络,其中包含不同词类之间的关系。他们举了一个例子:在hungry(饿)和refrigerator(冰箱)之间存 在一个路径,因为这两个标记词在food(食物)这个节点上相撞,即通过food,可以把hungry和refrigerator联系到一起,从而用于常 识推理。
