python风控评分卡建模和风控常识(博客主亲自录制视频教程)

结论
结论只属于教学数据,每个场景不一样,结论不一样,仅供参考
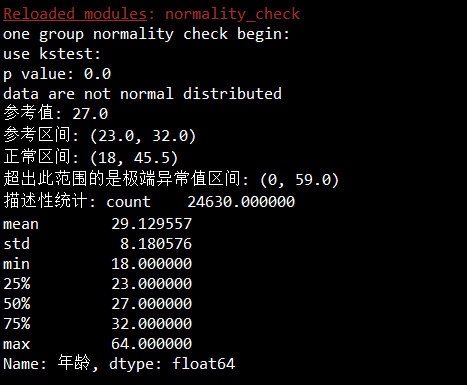
年龄45岁以上属于离群值,有欺诈嫌疑,建议不考虑放贷,可根据其他情况综合判定
1538/28720=0.535
年龄59岁以上属于极端离群值,非常可能是欺诈,不应该考虑放贷
50/28720=0.0017409470752089136
好坏客户比例无法区分:
年龄45岁以上好客户概率
772/1538=0.5019505851755527
年龄45岁以上坏客户概率
766/1538=0.4980494148244473
excel数据
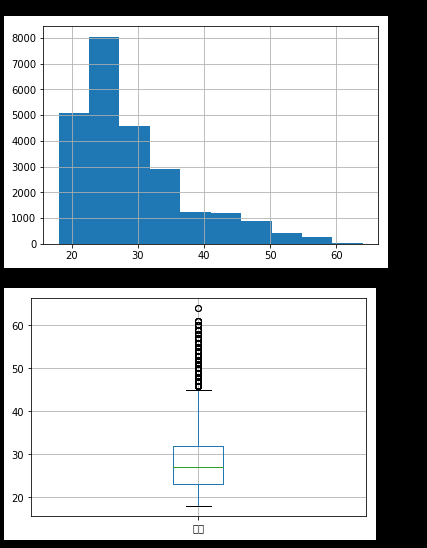
正太分布_箱形图_脱群值挖掘.py
# -*- coding: utf-8 -*- """
正太分布_箱形图_脱群值挖掘.py Created on Fri Mar 9 10:18:04 2018 @author: Toby QQ:231469242 Python视频集合 https://pythoner.taobao.com/ """ import pandas as pd import numpy as np import matplotlib.pyplot as plt import os import normality_check from scipy.stats import mode #读取文件 FileName="年龄.xlsx" #读取excel df=pd.read_excel(FileName) 年龄=df['年龄'] 描述性统计=年龄.describe() 样本量=描述性统计[0] 最小值=年龄.min() 最大值=年龄.max() 平均数=年龄.mean() 中位数=年龄.median() 众数=mode(年龄).mode[0] 四分之一位数=描述性统计[4] 四分之三位数=描述性统计[6] 标准差=描述性统计[2] IQR=四分之三位数-四分之一位数 异常值上线=四分之三位数+1.5*IQR 异常值下线=四分之一位数-1.5*IQR upper_outer_fence=四分之三位数+3*IQR lower_outer_fence=四分之一位数-3*IQR if lower_outer_fence<0: lower_outer_fence=0 #避免两端极值和商户活动降价影响 参考区间=(四分之一位数,四分之三位数) if 样本量>3: 正态性=normality_check.check_normality(年龄) else: 正态性=False 参考价格=中位数 market_price_range=(异常值下线,异常值上线) #绘制正太分布图 年龄.hist() df1=pd.DataFrame(年龄) fig,ax=plt.subplots() a=df1.boxplot(ax=ax) plt.savefig('pig.png') def 异常值判断(数字): if 数字>异常值上线 or 数字<异常值下线: print("%f 是异常值"%数字) return True else: print("%f 不是异常值"%数字) return False #箱型图市场价格取值范围 def Boxer_Market_price_range(异常值下线,异常值上线): if 异常值下线<最小值: 异常值下线=最小值 return (异常值下线,异常值上线) #正态分布市场价格取值范围 market_price_range=Boxer_Market_price_range(异常值下线,异常值上线) extreme_outlier=(lower_outer_fence,upper_outer_fence) print("参考值:",参考价格) print("参考区间:",参考区间) print("正常区间:",market_price_range) print("超出此范围的是极端异常值区间:",extreme_outlier) print("描述性统计:",描述性统计) #测试1.5万是否属于正常市场价格 #异常值判断(15000) #名称列表 list_名称=["样本量","最小值","最大值","平均数","中位数","众数","四分之一位数","四分之三位数","IQR","异常值上线","异常值下线","标准差","正态性","参考价格","参考区间","市场价格正常区间","(区间外)极端异常值"] list_value=[样本量,最小值,最大值,平均数,中位数,众数,四分之一位数,四分之三位数,IQR,异常值上线,异常值下线,标准差,正态性,参考价格,参考区间,market_price_range,extreme_outlier] df_save=pd.DataFrame(data=[list_value],index=[0],columns=list_名称) df_save.to_excel("统计结果.xlsx")
normality_check.py
# -*- coding: utf-8 -*- '''
normality_check.py
@author: Toby QQ:231469242 Python视频集合 https://pythoner.taobao.com/
all right reversed,no commercial use
正态性检验脚本 ''' import scipy from scipy.stats import f import numpy as np import matplotlib.pyplot as plt import scipy.stats as stats # additional packages from statsmodels.stats.diagnostic import lillifors #对一列数据进行正态分布测试 def check_normality(testData): print("one group normality check begin:") #20<样本数<50用normal test算法检验正态分布性 if 20<len(testData) <50: p_value= stats.normaltest(testData)[1] if p_value<0.05: print("use normaltest") print("p value:",p_value) print ("data are not normal distributed") return False else: print("use normaltest") print("p value:",p_value) print ("data are normal distributed") return True #样本数小于50用Shapiro-Wilk算法检验正态分布性 if len(testData) <50: p_value= stats.shapiro(testData)[1] if p_value<0.05: print ("use shapiro:") print("p value:",p_value) print ("data are not normal distributed") return False else: print ("use shapiro:") print("p value:",p_value) print ("data are normal distributed") return True if 300>=len(testData) >=50: p_value= lillifors(testData)[1] if p_value<0.05: print ("use lillifors:") print("p value:",p_value) print ("data are not normal distributed") return False else: print ("use lillifors:") print("p value:",p_value) print ("data are normal distributed") return True if len(testData) >300: p_value= stats.kstest(testData,'norm')[1] if p_value<0.05: print ("use kstest:") print("p value:",p_value) print ("data are not normal distributed") return False else: print ("use kstest:") print("p value:",p_value) print ("data are normal distributed") return True #测试结束 print("-"*100) #对所有样本组进行正态性检验 def NormalTest(list_groups): for group in list_groups: #正态性检验 status=check_normality(group) if status==False : return False ''' group1=[5,2,4,2.5,3,3.5,2.5,3] group2=[1.5,2,1.5,2.5,3.3,2.3,4.2,2.5] group3=[96,90,95,92,95,94,94,94] list_groups=[group1,group2,group3] list_total=group1+group2+group3 #对所有样本组进行正态性检验 NormalTest(list_groups) '''
python风控建模实战lendingClub(博主录制,catboost,lightgbm建模,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149

微信扫二维码,免费学习更多python资源
