医药统计项目联系QQ:231469242
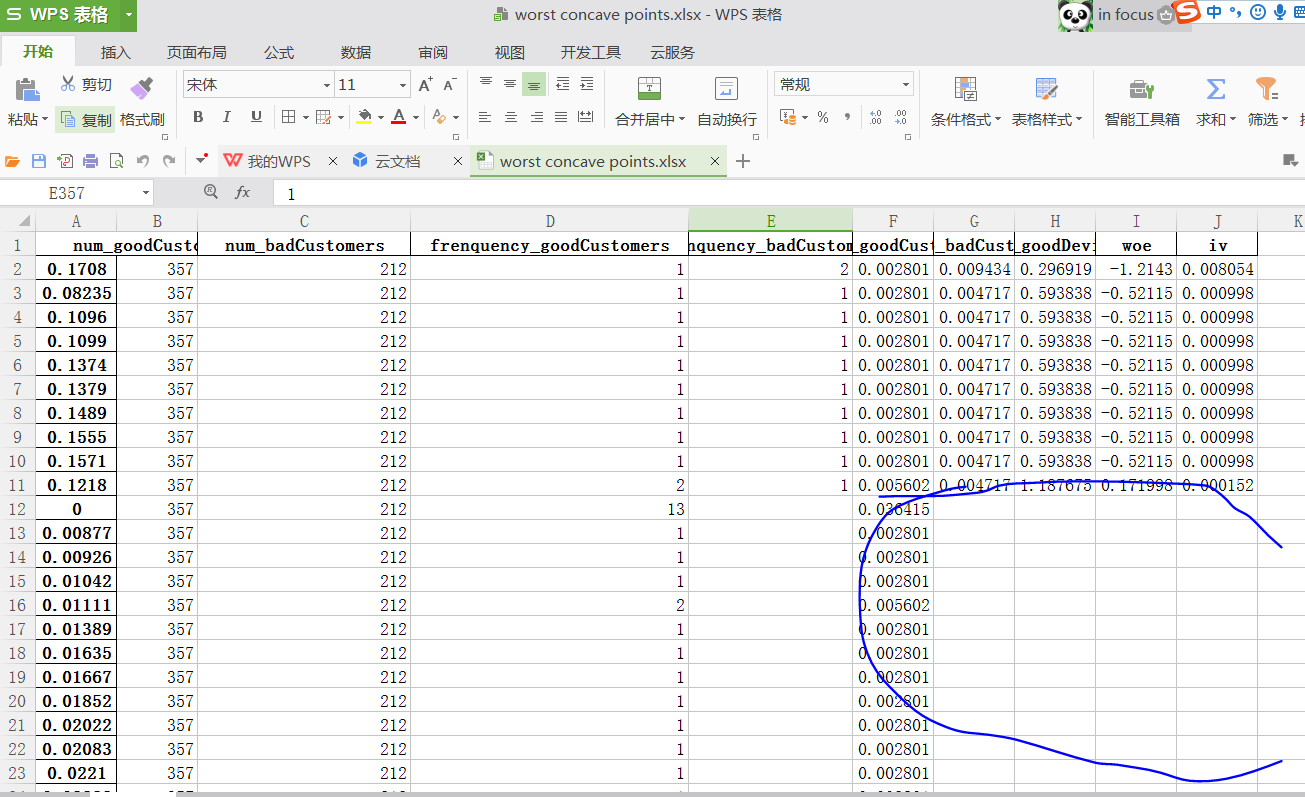
如果样本量太小,数据必须做分段化处理,否则会有很多空缺数据,woe效果不能有效发挥
随机森林结果

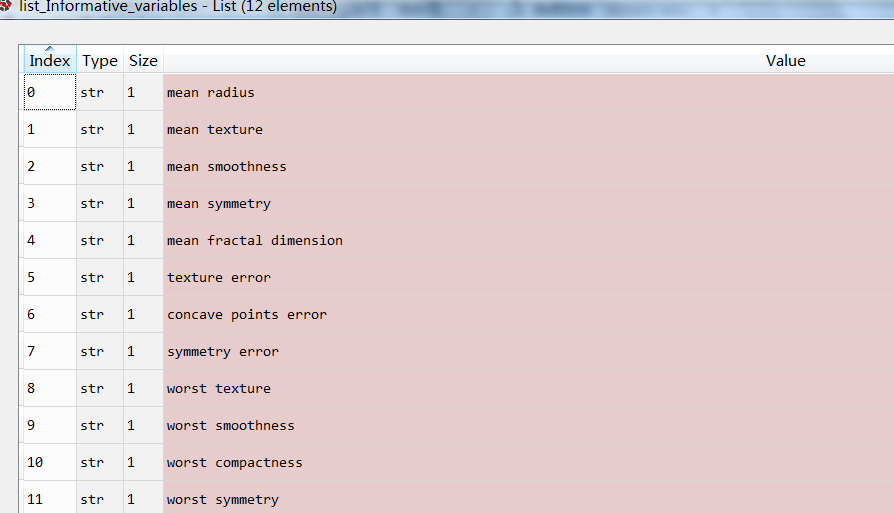
iv》0.02的因子在随机森林结果里都属于有效因子,但是随机森林重要性最强的因子没有出现在有效iv参数里,说明这些缺失重要变量没有做分段处理,数据离散造成。
数据文件
脚本备份
step1_customers_split_goodOrBad.py
# -*- coding: utf-8 -*- """ Created on Sun Jan 14 21:45:43 2018 @author QQ:231469242 把数据源分类为两个Excel,好客户Excel数据和坏客户Excel数据 """ import pandas as pd import numpy as np import matplotlib.pyplot as plt #读取文件 readFileName="breast_cancer_总.xlsx" #保存文件 saveFileName_good="result_good.xlsx" saveFileName_bad="result_bad.xlsx" #读取excel df=pd.read_excel(readFileName) #帅选数据 df_good=df[df.diagnosis=="B"] df_bad=df[df.diagnosis=="M"] #保存数据 df_good.to_excel(saveFileName_good, sheet_name='Sheet1') df_bad.to_excel(saveFileName_bad, sheet_name='Sheet1')
step2_automate_find_informative_variables.py
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 14 22:13:30 2018
@author: QQ:231469242
woe负数,好客户<坏客户
woe正数,好客户>坏客户
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
#创建save文件
newFile=os.mkdir("save/")
#读取文件
FileName_good="result_good.xlsx"
FileName_bad="result_bad.xlsx"
#保存文件
saveFileName="result_woe_iv.xlsx"
#读取excel
df_good=pd.read_excel(FileName_good)
df_bad=pd.read_excel(FileName_bad)
#所有变量列表
list_columns=list(df_good.columns[:-1])
index=0
def Ratio_goodDevideBad(index):
#第一列字段名(好客户属性)
columnName=list(df_good.columns)[index]
#第一列好客户内容和第二列坏客户内容
column_goodCustomers=df_good[columnName]
column_badCustomers=df_bad[columnName]
#去掉NAN
num_goodCustomers=column_goodCustomers.dropna()
#统计数量
num_goodCustomers=num_goodCustomers.size
#去掉NAN
num_badCustomers=column_badCustomers.dropna()
#统计数量
num_badCustomers=num_badCustomers.size
#第一列频率分析
frenquency_goodCustomers=column_goodCustomers.value_counts()
#第二列频率分析
frenquency_badCustomers=column_badCustomers.value_counts()
#各个元素占比
ratio_goodCustomers=frenquency_goodCustomers/num_goodCustomers
ratio_badCustomers=frenquency_badCustomers/num_badCustomers
#最终好坏比例
ratio_goodDevideBad=ratio_goodCustomers/ratio_badCustomers
return (columnName,num_goodCustomers,num_badCustomers,frenquency_goodCustomers,frenquency_badCustomers,ratio_goodCustomers,ratio_badCustomers,ratio_goodDevideBad)
#woe函数,阵列计算
def Woe(ratio_goodDevideBad):
woe=np.log(ratio_goodDevideBad)
return woe
'''
#iv函数,阵列计算
def Iv(woe):
iv=(ratio_goodCustomers-ratio_badCustomers)*woe
return iv
'''
#iv参数评估,参数iv_sum(变量iv总值)
def Iv_estimate(iv_sum):
#如果iv值大于0.02,为有效因子
if iv_sum>0.02:
print("informative")
return "A"
#评估能力一般
else:
print("not informative")
return "B"
'''
#详细参数输出
def Print():
print ("columnName:",columnName)
Iv_estimate(iv_sum)
print("iv_sum",iv_sum)
#print("",)
#print("",)
'''
#详细参数保存到excel,save文件里
def Write_singleVariable_to_Excel(index):
#index为变量索引,第一个变量,index=0
ratio=Ratio_goodDevideBad(index)
columnName,num_goodCustomers,num_badCustomers,frenquency_goodCustomers,frenquency_badCustomers,ratio_goodCustomers,ratio_badCustomers,ratio_goodDevideBad=ratio[0],ratio[1],ratio[2],ratio[3],ratio[4],ratio[5],ratio[6],ratio[7]
woe=Woe(ratio_goodDevideBad)
iv=(ratio_goodCustomers-ratio_badCustomers)*woe
df_woe_iv=pd.DataFrame({"num_goodCustomers":num_goodCustomers,"num_badCustomers":num_badCustomers,"frenquency_goodCustomers":frenquency_goodCustomers,
"frenquency_badCustomers":frenquency_badCustomers,"ratio_goodCustomers":ratio_goodCustomers,
"ratio_badCustomers":ratio_badCustomers,"ratio_goodDevideBad":ratio_goodDevideBad,
"woe":woe,"iv":iv},columns=["num_goodCustomers","num_badCustomers","frenquency_goodCustomers","frenquency_badCustomers",
"ratio_goodCustomers","ratio_badCustomers","ratio_goodDevideBad","woe","iv"])
#sort_values(by=...)用于对指定字段排序
df_sort=df_woe_iv.sort_values(by='iv',ascending=False)
#ratio_badDevideGood数据写入到result_compare_badDevideGood.xlsx文件
df_sort.to_excel("save/"+columnName+".xlsx")
#计算iv总和,评估整体变量
iv_sum=sum([i for i in iv if np.isnan(i)!=True])
print ("变量:",columnName)
#iv参数评估,参数iv_sum(变量iv总值)
iv_estimate=Iv_estimate(iv_sum)
print("iv_sum",iv_sum)
return iv_estimate,columnName
#y有价值变量列表存储器
list_Informative_variables=[]
#写入所有变量参数,保存到excel里,save文件
for i in range(len(list_columns)):
status=Write_singleVariable_to_Excel(i)[0]
columnName=Write_singleVariable_to_Excel(i)[1]
if status=="A":
list_Informative_variables.append(columnName)
最终得到一部分有效因子,共12个,经过数据分段化处理,会得到更多有效因子。