项目中有一处需求,需要把长网址缩为短网址,把结果通过短信、微信等渠道推送给客户。刚开始直接使用网上现成的开放服务,然后在某个周末突然手痒想自己动手实现一个别具特色的长网址(文本)缩短服务。
由于以前做过socket服务,对数据包的封装排列还有些印象,因此,短网址服务我第一反应是先设计数据的存储格式,我这里没有采用数据库,而是使用2个文件来实现:
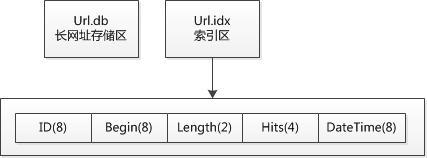
Url.db存储用户提交的长网址文本,Url.idx 存储数据索引,记录每次提交数据的位置(Begin)与长度(Length),还有一些附带信息(Hits,DateTime)。由于每次添加长网址,对 两个文件都是进行Append操作,因此即使这两个文件体积很大(比如若干GB),也没有太大的IO压力。
再看看Url.idx文件的结构,ID是主键,设为Int64类型,转换为字节数组后的长度为8,紧跟的是Begin,该值是把长网址数据续写到 Url.db文件之前,Url.db文件的长度,同样设为Int64类型。长网址的字符串长度有限,Int16足够使用 了,Int16.MaxValue==65536,比Url规范定义的4Kb长度还大,Int16转换为字节数组后长度为2字节。Hits表示短网址的解 析次数,设为Int32,字节长度为4,DateTime 设为Int64,长度8。由于ID不会像数据库那样自动递增,因此需要手工实现。因此在开始写入Url.idx前,需要预先读取最后一行(行是虚的,其实 就是最后30字节)中的的ID值,递增后才开始写入新的一行。
也就是说每次提交一个长网址,不管数据有多长(最大不能超过65536字节),Url.idx 文件都固定增加 30 字节。
数据结构一旦明确下来,整个网址缩短服务就变得简单明了。例如连续两次提交长网址,可能得到的短网址为http://域名/1000,与http://域名/1001,结果显然很丑陋,域名后面的ID全是数字,而且递增关系明显,很容易暴力枚举全部的数据。而且10进制的数字容量有限,一次提交100万条的长网址,产生的短网址越来越长,失去意义。
因此下面就开始对ID进行改造,改造的目标有2:
1、增加混淆机制,相邻两个ID表面上看不出区别。
2、增加容量,一次性提交100万条长网址,ID的长度不能有明显变化。
最简单最直接的混淆机制,就是把10进制转换为62进制(0-9a-zA-Z),由于顺序的abcdef…也很容易猜到下一个ID,因此62进制字符序列随机排列一次:
/// <summary>
/// 生成随机的0-9a-zA-Z字符串
/// </summary>
/// <returns></returns>
public static string GenerateKeys()
{
string[] Chars = "0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z".Split(',');
int SeekSeek = unchecked((int)DateTime.Now.Ticks);
Random SeekRand = new Random(SeekSeek);
for (int i = 0; i < 100000; i++)
{
int r = SeekRand.Next(1, Chars.Length);
string f = Chars[0];
Chars[0] = Chars[r - 1];
Chars[r - 1] = f;
}
return string.Join("", Chars);
}
运行一次上面的方法,得到随机序列:
string Seq = "s9LFkgy5RovixI1aOf8UhdY3r4DMplQZJXPqebE0WSjBn7wVzmN2Gc6THCAKut";
用这个序列字符串替代0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,具有很强的混淆特性。一个10进制的数字按上面的序列转换为62进制,将变得面目全非,附转换方法:
/// <summary>
/// 10进制转换为62进制
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
private static string Convert(long id)
{
if (id < 62)
{
return Seq[(int)id].ToString();
}
int y = (int)(id % 62);
long x = (long)(id / 62);
return Convert(x) + Seq[y];
}
/// <summary>
/// 将62进制转为10进制
/// </summary>
/// <param name="Num"></param>
/// <returns></returns>
private static long Convert(string Num)
{
long v = 0;
int Len = Num.Length;
for (int i = Len - 1; i >= 0; i--)
{
int t = Seq.IndexOf(Num[i]);
double s = (Len - i) - 1;
long m = (long)(Math.Pow(62, s) * t);
v += m;
}
return v;
}
例如执行 Convert(123456789) 得到 RYswX,执行 Convert(123456790) 得到 RYswP。
如果通过分析大量的连续数值,还是可以暴力算出上面的Seq序列值,进而猜测到某个ID左右两边的数值。下面进一步强化混淆,ID每次递增的单位不是固定的1,而是一个随机值,比如1000,1005,1013,1014,1020,毫无规律可言。
private static Int16 GetRnd(Random seekRand)
{
Int16 s = (Int16)seekRand.Next(1, 11);
return s;
}
即使把62进制的值逆向计算出10进制的ID值,也难于猜测到左右两边的值,大大增加暴力枚举的难度。难度虽然增加,但是连续产生的2个62进制值 如前面的RyswX与RyswP,仅个位数不同,还是很像,因此我们再进行第三次简单的混淆,把62进制字符向左(右)旋转一定次数(解析时反向旋转同样 的次数):
/// <summary>
/// 混淆id为字符串
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
private static string Mixup(long id)
{
string Key = Convert(id);
int s = 0;
foreach (char c in Key)
{
s += (int)c;
}
int Len = Key.Length;
int x = (s % Len);
char[] arr = Key.ToCharArray();
char[] newarr = new char[arr.Length];
Array.Copy(arr, x, newarr, 0, Len - x);
Array.Copy(arr, 0, newarr, Len - x, x);
string NewKey = "";
foreach (char c in newarr)
{
NewKey += c;
}
return NewKey;
}
/// <summary>
/// 解开混淆字符串
/// </summary>
/// <param name="Key"></param>
/// <returns></returns>
private static long UnMixup(string Key)
{
int s = 0;
foreach (char c in Key)
{
s += (int)c;
}
int Len = Key.Length;
int x = (s % Len);
x = Len - x;
char[] arr = Key.ToCharArray();
char[] newarr = new char[arr.Length];
Array.Copy(arr, x, newarr, 0, Len - x);
Array.Copy(arr, 0, newarr, Len - x, x);
string NewKey = "";
foreach (char c in newarr)
{
NewKey += c;
}
return Convert(NewKey);
}
执行 Mixup(123456789)得到wXRYs,假如随机递增值为7,则下一条记录的ID执行 Mixup(123456796)得到swWRY,肉眼上很难再联想到这两个ID值是相邻的。
以上讲述了数据结构与ID的混淆机制,下面讲述的是短网址的解析机制。
得到了短网址,如wXRYs,我们可以通过上面提供的UnMixup()方法,逆向计算出ID值,由于ID不是递增步长为1的数字,因此不能根据ID马上计算出记录在索引文件中的位置(如:ID * 30)。由于ID是按小到大的顺序排列,因此在索引文件中定位ID,非二分查找法莫属。
//二分法查找的核心代码片段
FileStream Index = new FileStream(IndexFile, FileMode.OpenOrCreate, FileAccess.ReadWrite);
long Id =;//解析短网址得到的真实ID
long Left = 0;
long Right = (long)(Index.Length / 30) - 1;
long Middle = -1;
while (Left <= Right)
{
Middle = (long)(Math.Floor((double)((Right + Left) / 2)));
if (Middle < 0) break;
Index.Position = Middle * 30;
Index.Read(buff, 0, 8);
long val = BitConverter.ToInt64(buff, 0);
if (val == Id) break;
if (val < Id)
{
Left = Middle + 1;
}
else
{
Right = Middle - 1;
}
}
Index.Close();
二分法查找的核心是不断移动指针,读取中间的8字节,转换为数字后再与目标ID比较的过程。这是一个非常高速的算法,如果有接近43亿条短网址记 录,查找某一个ID,最多只需要移动32次指针(上面的while循环32次)就能找到结果,因为2^32=4294967296。
用二分法查找是因为前面使用了随机递增步长,如果递增步长设为1,则二分法可免,直接从 ID*30 就能一次性精准定位到索引文件中的位置。
下面是完整的代码,封装了一个ShortenUrl类:
using System;
using System.Linq;
using System.Web;
using System.IO;
using System.Text;
/// <summary>
/// ShortenUrl 的摘要说明
/// </summary>
public class ShortenUrl
{
const string Seq = "s9LFkgy5RovixI1aOf8UhdY3r4DMplQZJXPqebE0WSjBn7wVzmN2Gc6THCAKut";
private static string DataFile
{
get { return HttpContext.Current.Server.MapPath("/Url.db"); }
}
private static string IndexFile
{
get { return HttpContext.Current.Server.MapPath("/Url.idx"); }
}
/// <summary>
/// 批量添加网址,按顺序返回Key。如果输入的一组网址中有不合法的元素,则返回数组的相同位置(下标)的元素将为null。
/// </summary>
/// <param name="Url"></param>
/// <returns></returns>
public static string[] AddUrl(string[] Url)
{
FileStream Index = new FileStream(IndexFile, FileMode.OpenOrCreate, FileAccess.ReadWrite);
FileStream Data = new FileStream(DataFile, FileMode.Append, FileAccess.Write);
Data.Position = Data.Length;
DateTime Now = DateTime.Now;
byte[] dt = BitConverter.GetBytes(Now.ToBinary());
int _Hits = 0;
byte[] Hits = BitConverter.GetBytes(_Hits);
string[] ResultKey = new string[Url.Length];
int seekSeek = unchecked((int)Now.Ticks);
Random seekRand = new Random(seekSeek);
string Host = HttpContext.Current.Request.Url.Host.ToLower();
byte[] Status = BitConverter.GetBytes(true);
//index: ID(8) + Begin(8) + Length(2) + Hits(4) + DateTime(8) = 30
for (int i = 0; i < Url.Length && i<1000; i++)
{
if (Url[i].ToLower().Contains(Host) || Url[i].Length ==0 || Url[i].Length > 4096) continue;
long Begin = Data.Position;
byte[] UrlData = Encoding.UTF8.GetBytes(Url[i]);
Data.Write(UrlData, 0, UrlData.Length);
byte[] buff = new byte[8];
long Last;
if (Index.Length >= 30) //读取上一条记录的ID
{
Index.Position = Index.Length - 30;
Index.Read(buff, 0, 8);
Index.Position += 22;
Last = BitConverter.ToInt64(buff, 0);
}
else
{
Last = 1000000; //起步ID,如果太小,生成的短网址会太短。
Index.Position = 0;
}
long RandKey = Last + (long)GetRnd(seekRand);
byte[] BeginData = BitConverter.GetBytes(Begin);
byte[] LengthData = BitConverter.GetBytes((Int16)(UrlData.Length));
byte[] RandKeyData = BitConverter.GetBytes(RandKey);
Index.Write(RandKeyData, 0, 8);
Index.Write(BeginData, 0, 8);
Index.Write(LengthData, 0, 2);
Index.Write(Hits, 0, Hits.Length);
Index.Write(dt, 0, dt.Length);
ResultKey[i] = Mixup(RandKey);
}
Data.Close();
Index.Close();
return ResultKey;
}
/// <summary>
/// 按顺序批量解析Key,返回一组长网址。
/// </summary>
/// <param name="Key"></param>
/// <returns></returns>
public static string[] ParseUrl(string[] Key)
{
FileStream Index = new FileStream(IndexFile, FileMode.OpenOrCreate, FileAccess.ReadWrite);
FileStream Data = new FileStream(DataFile, FileMode.Open, FileAccess.Read);
byte[] buff = new byte[8];
long[] Ids = Key.Select(n => UnMixup(n)).ToArray();
string[] Result = new string[Ids.Length];
long _Right = (long)(Index.Length / 30) - 1;
for (int j = 0; j < Ids.Length; j++)
{
long Id = Ids[j];
long Left = 0;
long Right = _Right;
long Middle = -1;
while (Left <= Right)
{
Middle = (long)(Math.Floor((double)((Right + Left) / 2)));
if (Middle < 0) break;
Index.Position = Middle * 30;
Index.Read(buff, 0, 8);
long val = BitConverter.ToInt64(buff, 0);
if (val == Id) break;
if (val < Id)
{
Left = Middle + 1;
}
else
{
Right = Middle - 1;
}
}
string Url = null;
if (Middle != -1)
{
Index.Position = Middle * 30 + 8; //跳过ID
Index.Read(buff, 0, buff.Length);
long Begin = BitConverter.ToInt64(buff, 0);
Index.Read(buff, 0, buff.Length);
Int16 Length = BitConverter.ToInt16(buff, 0);
byte[] UrlTxt = new byte[Length];
Data.Position = Begin;
Data.Read(UrlTxt, 0, UrlTxt.Length);
int Hits = BitConverter.ToInt32(buff, 2);//跳过2字节的Length
byte[] NewHits = BitConverter.GetBytes(Hits + 1);//解析次数递增, 4字节
Index.Position -= 6;//指针撤回到Length之后
Index.Write(NewHits, 0, NewHits.Length);//覆盖老的Hits
Url = Encoding.UTF8.GetString(UrlTxt);
}
Result[j] = Url;
}
Data.Close();
Index.Close();
return Result;
}
/// <summary>
/// 混淆id为字符串
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
private static string Mixup(long id)
{
string Key = Convert(id);
int s = 0;
foreach (char c in Key)
{
s += (int)c;
}
int Len = Key.Length;
int x = (s % Len);
char[] arr = Key.ToCharArray();
char[] newarr = new char[arr.Length];
Array.Copy(arr, x, newarr, 0, Len - x);
Array.Copy(arr, 0, newarr, Len - x, x);
string NewKey = "";
foreach (char c in newarr)
{
NewKey += c;
}
return NewKey;
}
/// <summary>
/// 解开混淆字符串
/// </summary>
/// <param name="Key"></param>
/// <returns></returns>
private static long UnMixup(string Key)
{
int s = 0;
foreach (char c in Key)
{
s += (int)c;
}
int Len = Key.Length;
int x = (s % Len);
x = Len - x;
char[] arr = Key.ToCharArray();
char[] newarr = new char[arr.Length];
Array.Copy(arr, x, newarr, 0, Len - x);
Array.Copy(arr, 0, newarr, Len - x, x);
string NewKey = "";
foreach (char c in newarr)
{
NewKey += c;
}
return Convert(NewKey);
}
/// <summary>
/// 10进制转换为62进制
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
private static string Convert(long id)
{
if (id < 62)
{
return Seq[(int)id].ToString();
}
int y = (int)(id % 62);
long x = (long)(id / 62);
return Convert(x) + Seq[y];
}
/// <summary>
/// 将62进制转为10进制
/// </summary>
/// <param name="Num"></param>
/// <returns></returns>
private static long Convert(string Num)
{
long v = 0;
int Len = Num.Length;
for (int i = Len - 1; i >= 0; i--)
{
int t = Seq.IndexOf(Num[i]);
double s = (Len - i) - 1;
long m = (long)(Math.Pow(62, s) * t);
v += m;
}
return v;
}
/// <summary>
/// 生成随机的0-9a-zA-Z字符串
/// </summary>
/// <returns></returns>
public static string GenerateKeys()
{
string[] Chars = "0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z".Split(',');
int SeekSeek = unchecked((int)DateTime.Now.Ticks);
Random SeekRand = new Random(SeekSeek);
for (int i = 0; i < 100000; i++)
{
int r = SeekRand.Next(1, Chars.Length);
string f = Chars[0];
Chars[0] = Chars[r - 1];
Chars[r - 1] = f;
}
return string.Join("", Chars);
}
/// <summary>
/// 返回随机递增步长
/// </summary>
/// <param name="SeekRand"></param>
/// <returns></returns>
private static Int16 GetRnd(Random SeekRand)
{
Int16 Step = (Int16)SeekRand.Next(1, 11);
return Step;
}
}
本方案的优点:
把10进制的ID转换为62进制的字符,6位数的62进制字符容量为 62^6约为568亿,如果每次随机递增值为1~10(取平均值为5),6位字符的容量仍然能容纳113.6亿条!这个数据已经远远大于一般的数据库承受 能力。由于每次提交长网址采用Append方式写入,因此写入性能也不会差。在解析短网址时由于采用二分法查找,仅移动文件指针与读取8字节的缓存,性能 上依然非常优秀。
缺点:在高并发的情况下,可能会出现文件打开失败等IO异常,如果改用单线程的Node.js来实现,或许可以杜绝这种情况。