起因:
因为最近在追的一部漫画因为版权原因被下架了,遂FQ去外面找到免费的版本,奈何网速慢而且一页只有一张图看的实在是影响阅读体验,网站也没有提供下载的功能,遂针对此网站写了一个爬虫工具,根据书号自动获取所有章节链接,然后遍历章节去获取每一张图片地址,最后将每章内容打包成pdf文件保存下来,方便阅读。
本次使用的爬虫工具是Htmlunit+Jsoup。jsoup是一款Java的HTML解析器,可直接解析某个URL地址、HTML文本内容。可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。但是jsoup只能针对静态页面,对于本次爬取的网站内容都是经过js渲染的,需要配合Htmlunit来一起使用。
jsoup最主要用到的就是的elements类和select()方法。elements类相当于网页元素中的标签,而select()方法用于按一定条件选取符合条件的标签,组成符合条件的标签数组。element支持转成字符串或者文本等,功能很强大。只需要了解一下select()方法的过滤规则即可上手用了。可以参考这个链接:[一点笔记]Jsoup中的select语法
在开发过程中,可以用jsoup配合谷歌浏览器的开发者控制台一起使用,对于要抓取的内容,直接右键点击代码行,copy–>copy selector,即可获得我们需要的数据,例如:
1.右键点击代码行,copy–>copy selector
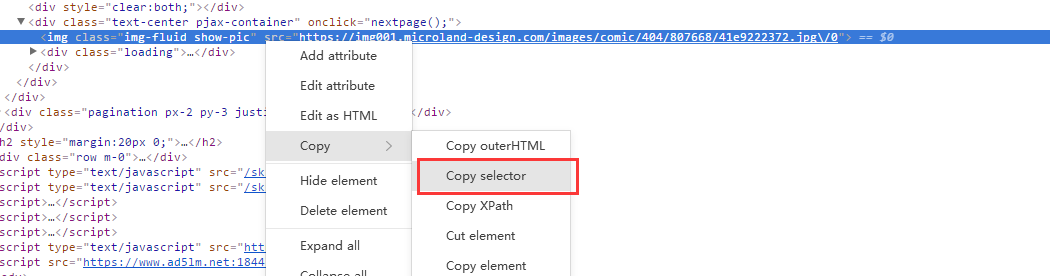
2.获得selector
“#all > div > div.text-center.pjax-container > img”
3.用jsoup抓取数据
String URL="网址";
Document document=Jsoup.cnnect("URL");
//在下载的document里进行检索的语句
elements img=document.select("#all").select("div").select("div.text-center.pjax-container").select("img");
//这样img标签就是我们最开始右键单击检查的标签
for (Element element : data) {
// 获取图片地址
String src = element.attr("abs:src");
}
下面上代码(网址部分已经和谐):
1.引入第三方工具类:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency><dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.33</version>
</dependency>
2.代码如下:
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.util.*;
/**
* @program: receiveDemo
* @description:
* @author: huang wei
* @create: 2021-04-07 20:22
*/
public class JsoupTest {
/**
* 章节图片地址集合
*/
private static Map<String, String> imgMap = new LinkedHashMap<>();
public static void main(String[] args) throws IOException {
String savePath = "H:\upload\test\";
String url = "http://爱国.敬业.民主/富强/书号";
String prefix = url.substring(0, url.indexOf("/", 8));
handle(savePath, prefix, url);
}
/**
* @throws Exception
* @Description: Htmlunit+Jsoup解析非静态页面
* 判断是目录页还是章节页,如果是目录页则抓取章节页列表地址
* 然后递归获取网页中图片链接,直到没有“下一页”,返回所有图片地址的封装
* @Param:
* @return:
* @author: hw
* @date: 2021/4/13 11:47
*/
public static void handle(String savePath, String url, String path) throws IOException {
//Htmlunit模拟的浏览器,设置css,js等支持及其它的一些简单设置
WebClient browser = new WebClient();
browser.getOptions().setCssEnabled(false);
browser.getOptions().setJavaScriptEnabled(true);
browser.getOptions().setThrowExceptionOnScriptError(false);
//获取页面
HtmlPage htmlPage = browser.getPage(path);
//设置等待js的加载时间
browser.waitForBackgroundJavaScript(3000);
//使用xml的方式解析获取到jsoup的document对象
Document document = Jsoup.parse(htmlPage.asXml());
Elements idTag = document.select("#list").select("a[href~=^http://m.j]");
if (!idTag.isEmpty() && idTag.hasText()) {
for (Element element : idTag) {
String src = element.attr("href");
//获取章节所有图片地址
handle(savePath, url, src);
//生成地址目录
String fileName = path.substring(path.lastIndexOf("/") + 1);
File directory = new File(savePath + fileName);
directory.mkdir();
String imgPath = directory.getAbsolutePath() + File.separator + element.text() + ".txt";
writeData(imgPath, dataHandle());
//生成pdf
File file = new File(imgPath);
ImgToPdfUtil.imgOfPdf(file);
}
} else {
// 根据页面属性设置对应的抓取规则--获取页面章节图片地址
Elements data = document.select("img[data-original]img[height=auto]");
for (Element element : data) {
String src = element.attr("abs:src");
imgMap.put(src, "");
}
// 获取下一章节地址
Elements aTag = document.select("body").select("div").select("div.bottom").select("ul").select("li.last").select("a");
for (Element element : aTag) {
String text = element.text();
if (text.equals("下一页")) {
String href = element.attr("href");
handle(savePath, url, url + href);
}
}
}
}
/**
* @throws Exception
* @Description: 集合数据输出
* @Param:
* @return:
* @author: hw
* @date: 2021/4/13 11:35
*/
public static String dataHandle() {
StringBuffer stringBuffer = new StringBuffer();
try {
Set<String> set = imgMap.keySet();
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
String key = iterator.next();
stringBuffer.append(key).append("
");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
imgMap.clear();
}
return stringBuffer.toString();
}
/**
* @throws Exception
* @Description: 文件写入
* @Param:
* @return:
* @author: hw
* @date: 2021/4/13 11:34
*/
public static void writeData(String filePath, String content) {
RandomAccessFile randomFile = null;
try {
// 打开一个随机访问文件流,按读写方式
randomFile = new RandomAccessFile(filePath, "rw");
// 文件长度,字节数
long fileLength = randomFile.length();
// 将写文件指针移到文件尾。
randomFile.seek(fileLength);
// 将数据转成byte防止中文乱码
byte buffer[] = new byte[1024];
buffer = content.getBytes();
randomFile.write(buffer);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (randomFile != null) {
try {
randomFile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}