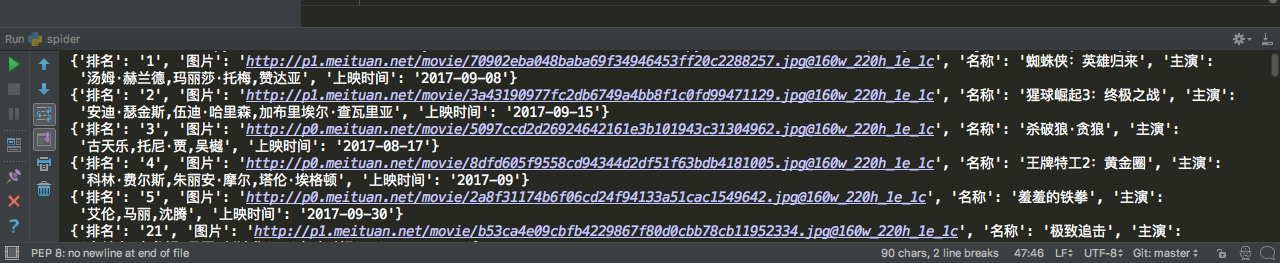
主要爬取猫眼电影最受期待榜的电影排名、图片链接、名称、主演、上映时间。
思路:1.定义一个获取网页源代码的函数;
2.定义一个解析网页源代码的函数;
3.定义一个将解析的数据保存为本地文件的函数;
4.定义主函数;
5.使用多进程爬取。
步骤一:首先,导入相关的库:
import requests
import re
import json
from multiprocessing import Pool
from requests.exceptions import RequestException
步骤二:定义获取网页源代码的函数,这里使用 requests.get() 方法来获取,并调用异常处理方法:
def get_one_page(url):
response = requests.get(url)
try:
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
步骤三:定义一个函数,利用正则表达式 re.findall() 等函数解析网页源代码,并利用 yield 生成器对解析的代码进行排布,转换为字典形式:
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?">(d+)</i>.*?data-src="(.*?)".*?</a>.*?'
+ '<a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'排名': item[0],
'图片': item[1],
'名称': item[2],
'主演': item[3].strip()[3:],
'上映时间': item[4].strip()[5:]
}
步骤四:定义主函数,爬取最受期待榜的 n 页:
def main(offset):
url = 'https://maoyan.com/board/6?offset=' +str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_one_page(item)
步骤五:多进程爬取,定义进程池,并调用 Pool.map() 方法进行多进程爬取,提高爬取效率:
if __name__ == "__main__":
pool = Pool()
pool.map(main, [i*10 for i in range(10)])
爬取的部分数据如下: