利用框架 pyspider 能实现快速抓取网页信息,而且代码简洁,抓取速度也不错。
环境:macOS;Python 版本:Python3。
1.首先,安装 pyspider 框架,使用pip3一键安装:
pip3 pyspider
2.终端输入 pyspider all 启动 pyspider:
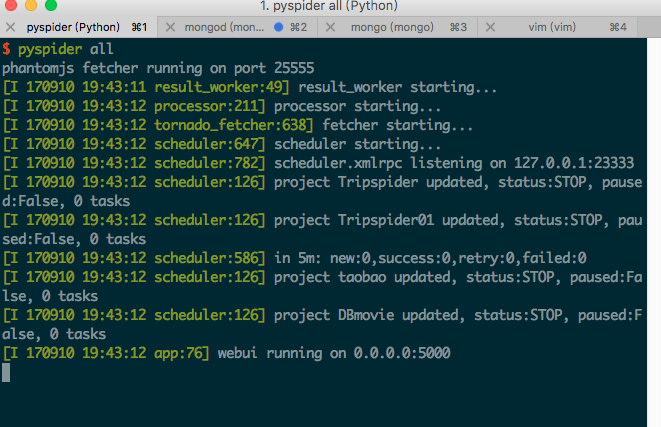
打开 Chrome,地址栏输入 localhost:5000 进入 pyspider 框架的webui界面。
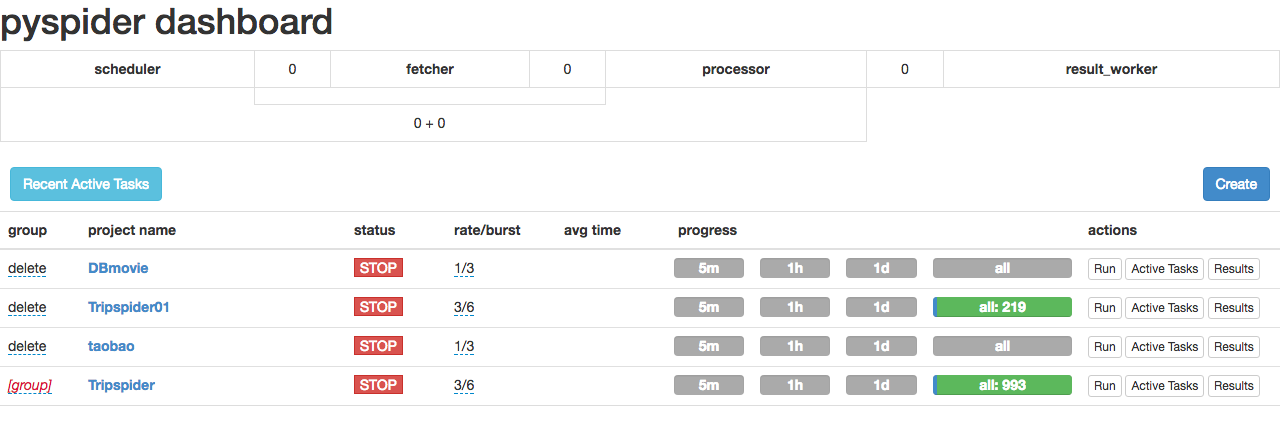
点击 create ,创建 一个新的project。
3.创建完 project 后,我们便进入了代码调试界面。
这次我们要抓取的信息是猫途鹰网关于布拉格的酒店信息,把网址填入 on_star 一栏并替换掉 on_star , 点击 save 保存,点击左上角 run 选项,然后点击出现的网址右侧的箭头的选项:
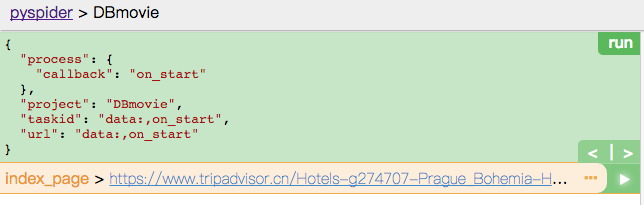
便出现 index_page 的页面,我们点击 web 选项卡,出现网页内容后点击 enable css selector helper ,选中酒店标题的超链接,这时上方便出现该标题的 CSS 选择器,把选择器内容复制粘贴替换掉右侧代码中的 a[href^="http"] ,save 后再次点击 run,但是 pyspider 的选择器并不一定准确,需要自己随时更改。这时我们便得到了我们想要的酒店标题超链接。
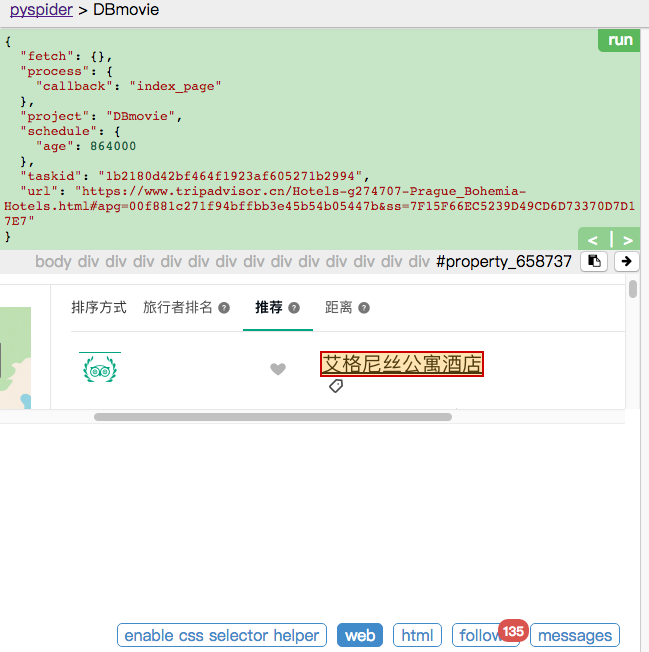
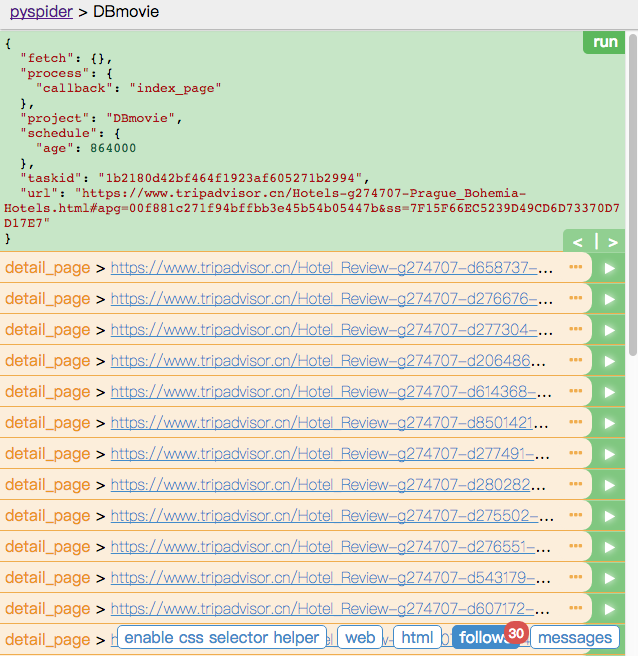
4.点击其中一个网页的右边的小箭头,进入详情页界面,我们要获取的信息便是详情页中的内容。类似的用 CSS 选择器获取酒店的信息,写入代码如下:
def detail_page(self, response):
url = response.url
name = response.doc('.heading_title').text()
rating = response.doc('.header_rating .taLnk').text()
ranking = response.doc('.prw_common_header_pop_index > span').text()
location = response.doc('.colCnt3').text()
phone = response.doc('.blEntry.phone > span:nth-child(2)').text()
grade = response.doc('.overallRating').text()
return {
"url": url,
"name": name,
"rating": rating,
"ranking": ranking,
"location": location,
"phone": phone,
"grade": grade
}
便返回酒店链接,名称,点评,排名,地址,电话,评分这七个信息,保存后点击 run,我们便能看到打印的信息。
5.存储信息到 MongoDB:
import pymongo
client = pymongo.MongoClient('localhost')
db = client['trip']
def on_result(self, result):
if result:
self.save_to_mongo(result)
def save_to_mongo(self, result):
if self.db['布拉格'].insert(result):
print('存储到 MongoDB 成功', result)
6.模拟翻页抓取多页面:
在 index_page(self, response) 函数中插入:
next = response.doc('.pagination .nav.next').attr.href
self.crawl(next, callback=self.index_page)
7.到这时,我们代码便写完了,退出 project ,在控制面板中 status 栏更改方式为 DEBUG ,点击 run,运行代码,Active Tasks 可以查看当前任务。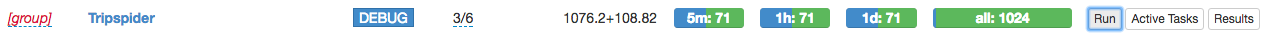
8.存储到MongoDB 的信息。
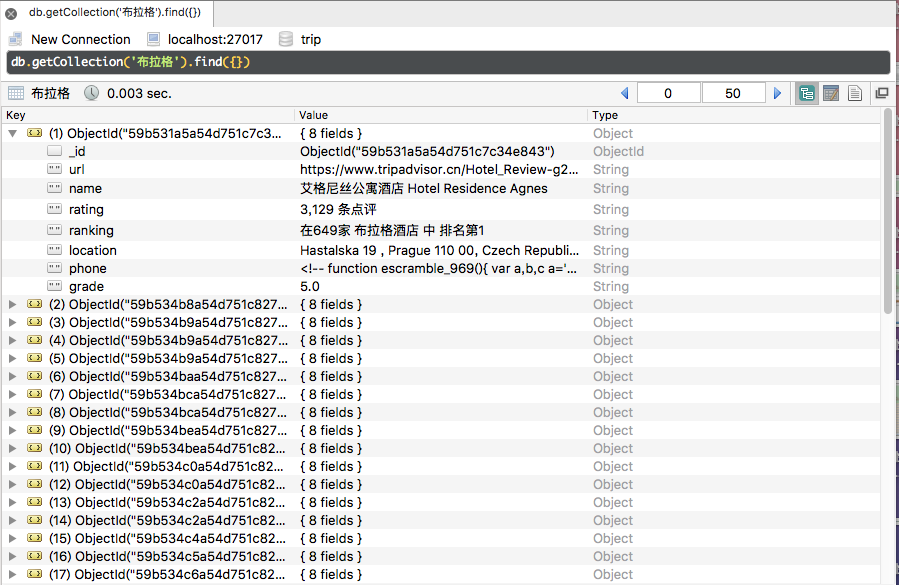
到现在,我们便完成了对猫途鹰网上布拉格酒店信息的爬取。
代码 github 地址:https://github.com/weixuqin/PythonProjects/blob/master/pyspider/spider.py