思路:
使用搜狗搜索爬取微信文章时由于官方有反爬虫措施,不更换代理容易被封,所以使用更换代理的方法爬取微信文章,代理池使用的是GitHub上的开源项目,地址如下:https://github.com/jhao104/proxy_pool,代理池配置参考开源项目的配置。
步骤:
1)分析网页结构,拿到网页请求参数
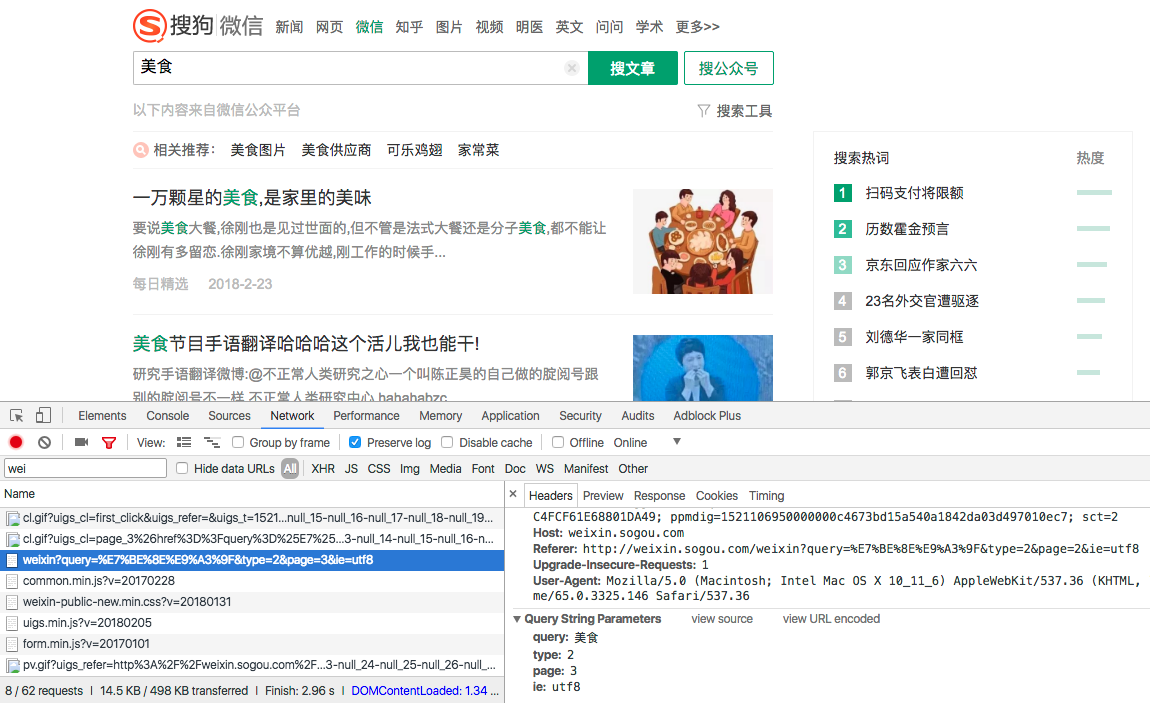
2)构造请求参数,获取索引页内容:
def get_index(keyword, page):
data = {
'query': keyword,
'type': 2,
'page': page
}
queries = urlencode(data)
url = base_url + queries
html = get_html(url)
return html
3)主要讲下代理IP的实现方法,先设置本地IP为默认代理,定义获取代理池IP地址的函数,当爬取出现403错误的时候更改代理,在获取网页源代码的时候传入代理IP地址,若获取网页源代码失败再次调用 get_html() 方法,再次进行获取尝试。
#初始化代理为本地IP
proxy = None
#定义获取代理函数
def get_proxy():
try:
response = requests.get('PROXY_POOL_URL')
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
#添加代理获取网页内容
def get_html(url, count=1):
print('Crawling', url)
print('Trying Count', count)
global proxy
if count >= MAX_COUNT:
print('Tried Too Many Counts')
return None
try:
if proxy:
proxies = {
'http': 'http://' + proxy
}
response = requests.get(url, allow_redirects=False, headers=headers, proxies=proxies)
else:
response = requests.get(url, allow_redirects=False, headers=headers)
if response.status_code == 200:
return response.text
if response.status_code == 302:
# Need Proxy
print('302')
proxy = get_proxy()
if proxy:
print('Using Proxy', proxy)
return get_html(url)
else:
print('Get Proxy Failed')
return None
except ConnectionError as e:
print('Error Occurred', e.args)
proxy = get_proxy()
count += 1
return get_html(url, count)
4)使用 pyquery 获取详情页详细微信文章信息(如:微信文章标题、内容、日期、公众号名称等):
def parse_detail(html):
try:
doc = pq(html)
title = doc('.rich_media_title').text()
content = doc('.rich_media_content').text()
date = doc('#post-date').text()
nickname = doc('#js_profile_qrcode > div > strong').text()
wechat = doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
return {
'title': title,
'content': content,
'date': date,
'nickname': nickname,
'wechat': wechat
}
except XMLSyntaxError:
return None
5)存储到MongoDB,去重操作:
def save_to_mongo(data):
if db['articles'].update({'title': data['title']}, {'$set': data}, True):
print('Saved to Mongo', data['title'])
else:
print('Saved to Mongo Failed', data['title'])
操作过程:
1)开启代理池:

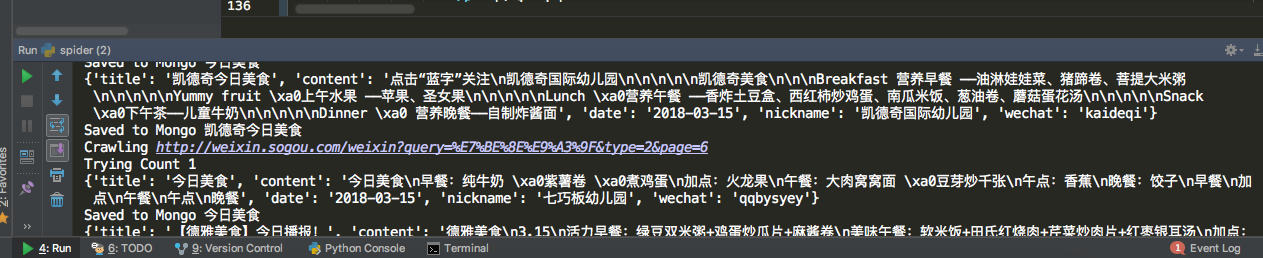
2)运行 spider.py 文件:
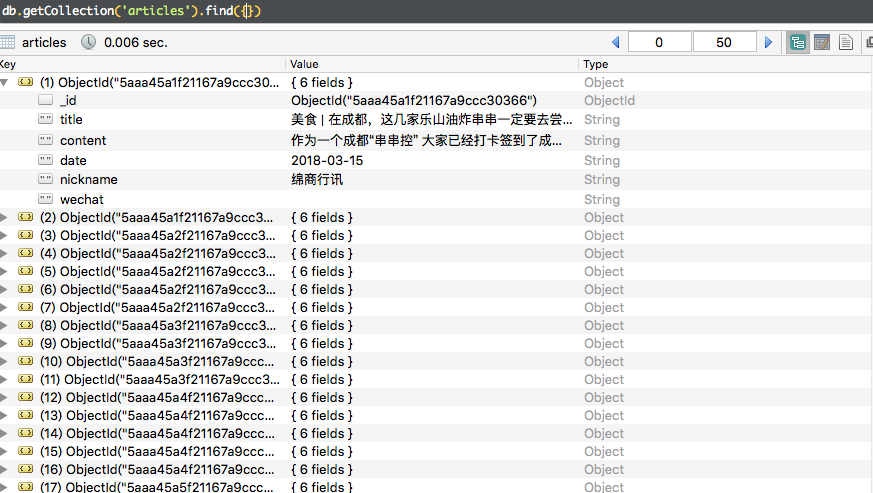
3) 查看保存在MongoDB的内容:
完整代码在GitHub上:https://github.com/weixuqin/PythonProjects/tree/master/WeixinArticles
PS:当我使用配置好的默认参数文件 config.py ,并导入当前目录下的 spider.py , 发现 pycharm 提示我错误,实际上并没有出错

原因是 pycharm 不会将当前文件目录自动加入自己的 sourse_path ,所以需要我们手动导入:右键make_directory as-->sources path将当前工作的文件夹加入source_path。
