本次采集的数据将作为app的后台数据使用,为了便于处理,直下载至本地,歌曲以UUID命名,如果采用中文命名,在后面HTTP请求数据解析音乐时,会让你乱码到怀疑人生哦!!!
歌曲的地址:https://www.kugou.com/yy/special/single/378394.html
items文件下的代码:
import scrapy
from scrapy import Field
class MusicItem(scrapy.Item):
# define the fields for your item here like:
album_name = scrapy.Field() #音乐名称
author_name = scrapy.Field() #歌手名称
music_img = scrapy.Field() #专辑图片
play_url = scrapy.Field() #音乐地址
#为了方便数据的处理,直接下载了图片和音乐到本地,并将文件名采用UUID命名
pipelines文件处理数据的存储:
from pymongo import MongoClient
class MusicPipeline(object):
def open_spider(self,spider):
self.client=MongoClient(host='127.0.0.1',port=27017)
self.coll=self.client["kugou"]["music"]
self.li=[]
def close_spider(self,spider):
self.insert()
self.client.close()
def insert(self):
self.coll.insert_many(self.li)
def process_item(self, item, spider):
if len(self.li)>10:
self.insert()
self.li=[]
print("成功插入10条数据-------------------------------------")
else:
self.li.append(dict(item))
return item
本次下载数据相对简单,没启用中间件来调度数据。
爬虫主文件kg.py代码:
# -*- coding: utf-8 -*-
import scrapy,requests
from music.items import MusicItem
from uuid import uuid4
import os
from conf import SONG_PATH,PHOTO_PATH
class KgSpider(scrapy.Spider):
name = 'kg'
# allowed_domains = ['www.kugou.com']
start_urls = ['https://www.kugou.com/yy/special/single/378394.html']
def parse(self, response):
item=MusicItem()
m_id = response.xpath('//div[@id="songs"]/ul/li/a/@data').extract()
for each in m_id:
music_id=each.split("|")[0]
url="https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash="+music_id
song_dict=requests.get(url=url).json().get("data")
item["album_name"]=self.get_album_name(song_dict)
filename = uuid4()
item["author_name"] = self.get_author_name(song_dict)
item["music_img"] = self.get_music_img(song_dict,filename)
item["play_url"] = self.get_play_url(song_dict,filename)
yield item
def get_album_name(self,response):
return response.get("album_name")
def get_author_name(self,response):
return response.get("author_name")
def get_music_img(self,response,filename):
img_url=response.get("img")
image=os.path.join(PHOTO_PATH,f"{filename}.jpg")
photo = requests.get(img_url)
with open(image,"wb")as f:
f.write(photo.content)
# return response.get("img")
return f"{filename}.jpg"
def get_play_url(self,response,filename):
song_url=response.get("play_url")
if len(song_url)>0:
song=os.path.join(SONG_PATH,f"{filename}.mp3")
music=requests.get(song_url)
with open(song,"wb")as f:
f.write(music.content)
else:
return "无效的URL"
return f"{filename}.mp3"
conf中对文件路径的配置:
import os
PHOTO_PATH="photo"
SONG_PATH="song"
主程序的入口:
from scrapy import cmdline
cmdline.execute('scrapy crawl kg'.split())
项目结构图如下:
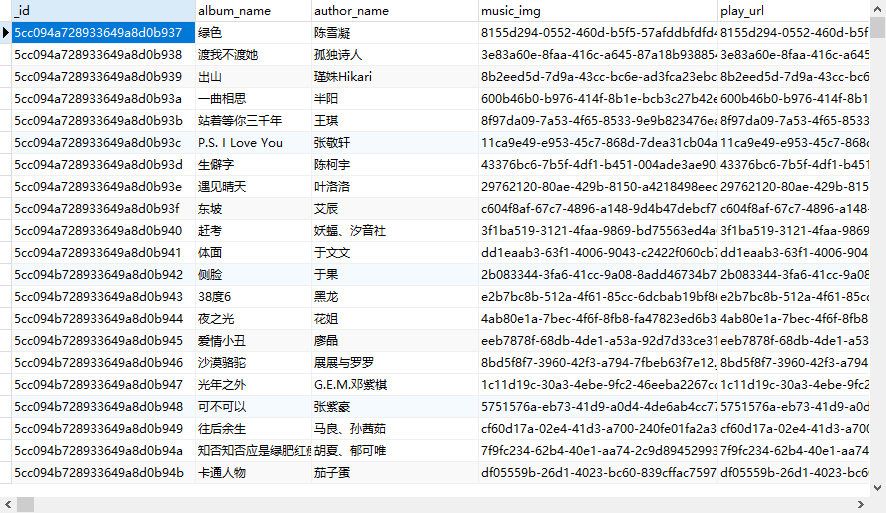
数据库中保存数据如下:
表格视图:
json视图:
