数据分析三剑客:Numpy Pandas Matplotlib
import numpy as np
np.array([1,2,3,4,5]) #创建一维数组
array([1, 2, 3, 4, 5])
np.random.randint(0,100,size=(5,6)) #创建二维数组
array([[73, 26, 72, 34, 26, 38],
[ 7, 10, 56, 19, 89, 22],
[90, 5, 58, 65, 68, 0],
[ 7, 55, 4, 82, 44, 89],
[14, 14, 27, 69, 85, 78]])
二维数组取值:
attr=np.random.randint(0,100,size=(5,6))
attr[[1,2]] #取数组中的1行到2行
atr[0:3] #从第一行到第三行
attr[;,2:4] #从第3列到第4列
关于数组的反转:
比如三维数组的操作:
import matplotlib.pyplot as plt
img=plt.imread('./mm.jpg')
plt.imshow(img[::-1,::-1,::-1])
上下倒置::-1 左右倒置::-1 像素倒置::-1
数组维度间的变形:
如一维变二维
a1=np.array([1,2,3,4,5,6])
a1.reshape(-1,2) #二维
a2.reshape(-1,2,2) #三维
二维变三维:
a2=np.random.randint(20,size=(4,5))
a2.reshape(-1,2,2)
数组的级联操作:就是指将两个或多个数组拼接起来
前提:维度必须相同,形状相符,要么横向长度相等(axis=1),要么纵向长度相等(axis=0)。
import numpy as np
a2=np.random.randint(20,size=(2,10)) #2行10列
a3=np.random.randint(30,size=(3,10)) #3行10列
np.concatenate((a2,a3),axis=0) #列相同,拼接列 axis=0
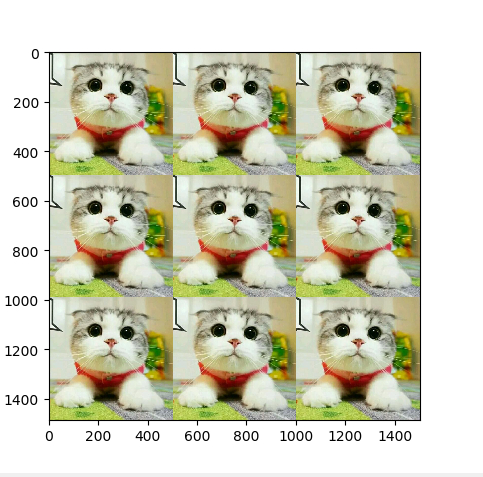
小案例:拼接九宫格图片
import numpy as np
from matplotlib import pyplot as plt
cat=plt.imread('./cat.jpg')
c3=np.concatenate((cat,cat,cat),axis=1) #横向拼接三张
c9=np.concatenate((c3,c3,c3),axis=0) #纵向拼接三张
plt.imshow(c9) #显示在jupyter中
plt.show() #在pycharm中调用显示图片
效果图如下:
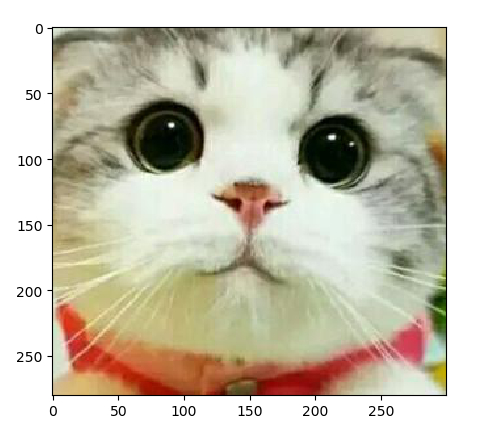
对指定图片进行裁剪:推荐使用切片
按照“井”形切割 由上到下,由左到右
plt.imshow(cat[50:330,100:400])
就能实现如下效果:
对于使用工具的环境搭建,pycharm画图方面没有jupyter简单专业。但也可以配置好了使用pycharm
直接使用anaconda中的Python.exe环境,等待导入pycharm的时间略长。
用于做数据清洗的pandas:
Series创建索引:
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
s1=Series(np.random.randint(1,50,size=(4,)),index=['a','p','e','f'],name='kevin')
w=Series(data=[2,3,5,7,11,11,5,6,7])
print(w.unique())
print(s1)
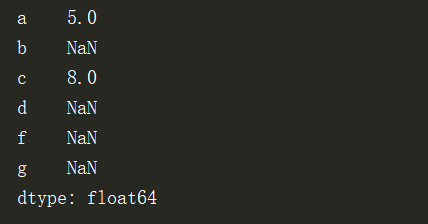
两个series对象进行加:索引对应的元素会相加,不对应的元素就补空
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
s1=Series([1,2,3,4],index=['a','b','c','d'])
s2=Series([4,5,6,7],index=['a','c','f','g'])
print(s1)
print(s2)
print(s1+s2)
即a和c有值,其余值为空,效果如图所示: 且值会以浮点型计算显示
DataFrame的使用:
from pandas import Series,DataFrame
dic={
"kevin":[66,77,88,99],
"lisa":[71,82,93,64],
"jack":[88,77,108,11]
}
df=DataFrame(data=dic,index=['语文','数学','外语','综合'])
print(df)
执行结果如下:

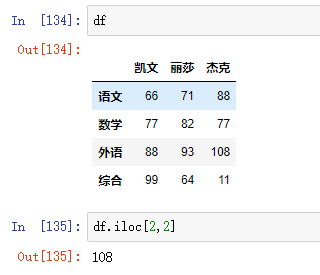
df.columns=['凯文','丽莎','杰克']
df
列属性被改变:修改的列属性个数一定要和列索引数量一致,否则会报错

索引操作:
找行数据:df.loc['语文']
找列数据:df.丽莎
找行列定位具体数据: df.loc['外语',‘丽莎’]
切片:
df[a:b] 切行
df[:,a:b] 切列

loc:取显示索引
iloc:取隐式索引
index_col :将列作为行索引
parse_dates :将某一列的数据转为时间序列
resample :对数据的重新取样 前提是源数据索引必须是时间序列
import tushare as ts import pandas as pd df=ts.get_k_data(code='002460',start='2015',end='2019-06-06') #查询2015到2019所有行情 df.to_csv('./jlgf.csv') #数据保存至文本 df=pd.read_csv('./jlgf.csv',index_col='date',parse_dates=['date']) #将日期由字符串改为日期对象 df.drop(labels='Unnamed: 0',axis=1,inplace=True) #移除掉空白的列元素 last_price=df['open'][-1] #当前上一个交易日 df_mounths=df.resample('M').first() #要买股票的次数 df_years=df.resample('Y').last()[:-1] #去除最后一年 不会卖出 count_money=0 #纯利润 hold=0 #持有股票 for year in range(2015,2020): df_mounths-=df_mounths.loc[str(year)]['open'].sum()*100 #当年买一百股花费本金 hold=len(df_mounths.loc[str(year)]['open'])*100 #当年持有股票数 if year !=2019: count_money+=df_years[str(year)]['open'][0]*hold #卖出当年持有全部股票 hold=0 #持有股票数清零 count_money+=hold*last_price #最终获利 print(count_money)