1、目的:
每天凌晨0点1分统计用户点击进入内容详情页的次数,对内容点击量形成榜单。
2、分析:
A、/data/log/epg.access.log日志实时打印用户访问页面的日志,并且每天凌晨0点会进行日志切割,将前一天的日志保存为epg.access.log_YYYYMMDD。
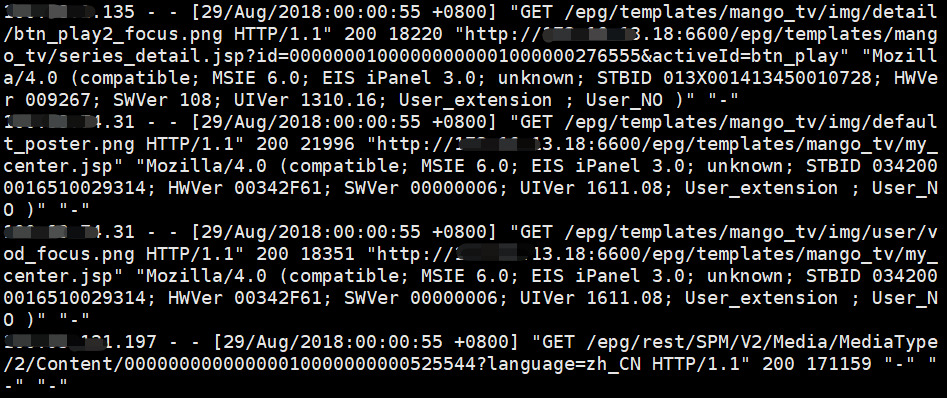
B、分析日志发现:用户进入详情页时,/data/log/epg.access.log日志会打印含series_detail.jsp的信息,且内容ID打印在该串信息中的第71位至102位。
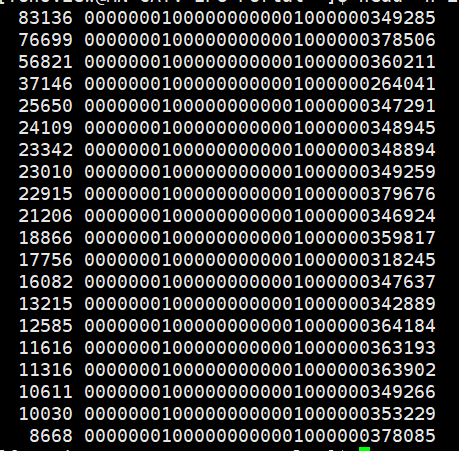
C、根据内容ID的点击量从大到小统计排序,输出一个文本文件。
3、脚本实现
1 #!/bin/bash 2 3 log_path="/data/log/" 4 src_ser="epg.access.log" 5 output_ser="PV" 6 date_str=`date +%Y%m%d -d '-1 days'` 7 dst_file=${src_ser}_${date_str} 8 outputfile=${output_ser}_${date_str} 9 cd $log_path 10 awk '{print $11}' $dst_file |grep 'series_detail.jsp' |cut -c71-102 |sort|uniq -c|sort -nr >> $outputfile
脚本中的第10行是本文重点:
awk '{print $11}':以默认的空格为分隔符,打印第11个字符串内容;
cut -c71-102:截取第71位至第102位字符;
sort|uniq -c:sort和uniq结合使用,对文件内容先进行排序,然后进行去重并计数(计数值显示在最左边);
sort -nr:参数n为依照数值的大小排序,参数r为以相反的顺序来排序(即从大到小)。
4、截图
原日志截图:
输出文件截图(第一列为点击量,第二列为内容ID):