为什么要内存对齐
虽然所有的变量最后都会保存到特定的地址内存中去,但是相应的内存空间必须满足内存对齐的要求,主要基于存在以下两个原因:
- 硬件平台原因:并不是所有的平台都能够访问任意地址上的任意数据,某些硬件平台只能够访问对齐的地址,否则就会出现硬件异常错误。
- 性能原因:如果数据存放在未对齐的内存空间中,则处理器在访问变量时要做两次次内存访问,而对齐的内存访问只需要一次。
上述两个原因,第一个原因从字面意思上就能够理解,那第二个原因是什么意思呢?
假定现在有一个 32 位微处理器,那这个处理器访问内存都是按照 32 位进行的,也就是说一次性读取或写入都是四字节。假设现在有一个处理器要读取一个大小为 4 字节的变量,在内存对齐的情况下,处理器是这样进行读取的:
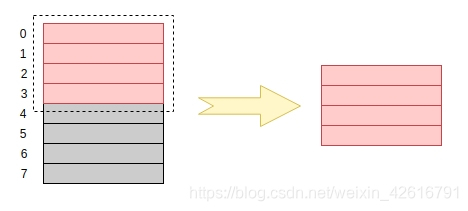
那如果数据存储没有按照内存对齐的方式进行的话,处理器就会这样进行读取:
对比内存对齐和内存没有对齐两种情况我们可以明显地看到:
在内存对齐的情况下,只需要两个个步骤就可以将数据读出来,首先处理器找到要读出变量所在的地址,然后将数据读出来。
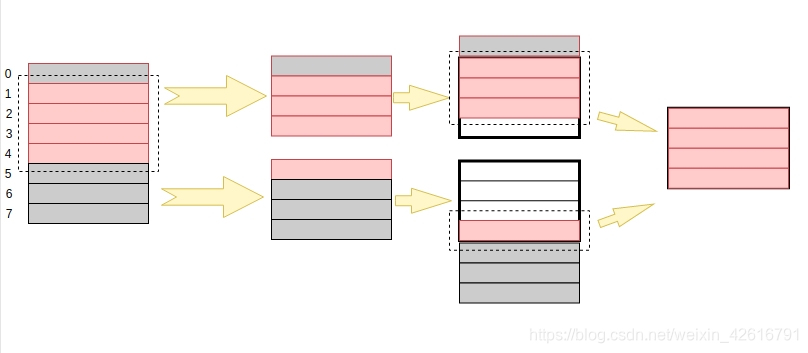
在内存没有对齐的情况下,却需要以下四个步骤才能够将数据取出来:
- 处理器找到要读取变量所在的地址,也就是图中红色方块所在位置。
- 由于此时内存未对齐,处理器是 32 位的,一次性读取或者写入都是 4 字节,所以需要将 0-3 地址内的数据和 4-7 地址里的数据都取出来。
- 由于 0 - 3 地址范围的 0 地址里的数据不属于我们要读取的数据,因此将这一小块的数据进行移位,把 0 地址里的数据移出去;同理, 4 - 7 地址范围里的数据也要进行移位,保留 4 地址里的数据
- 合并移位之后的数据,得出结果
通过上述的分析,我们可以知道内存对齐能够提升性能,这也是我们要进行内存对齐的原因之一。
结构体内存对齐
对齐原则
在明白了为何要进行内存对齐之后,我们来分析结构体内的内存对齐,在进行具体的实例分析前,需要给出结构体内存对齐的两条基本原则。
- 结构体各成员变量的内存空间的首地址必须是“对齐系数”和“变量实际长度”中较小者的整数倍。
- 对于结构体来说,在其各个数据都对齐之后,结构体本身也需要对齐,即结构体占用的总大小应该为“对齐系数”和“最大数据长度”中较小值的整数倍。
在给定了基本原则之后,我们通过一个例子来说明结构体的内存对齐,假定当前的处理器是 32 位的,对齐系数为4。在这里笔者选择在上一篇文章中涉及到的一个结构体进行解析,结构体如下:
struct data_test
{
char a; /*本身大小 1 字节*/
short b; /*本身大小 2 字节*/
char c[2]; /*数组单个成员 1 字节*/
double d; /*本身大小 8 字节*/
char e; /*本身大小 1 字节*/
int f; /*本身大小 4 字节*/
char g; /*本身大小 1 字节*/
}data;
根据我们刚刚给出的第一条对齐原则,先确定出每个变量的存储位置,变量存储方式是小端对齐,为了看起来更加形象,以 16 个字节作为一行来表示变量的存储位置(这里所说的存储位置是指相对于结构体起始地址地偏移)。
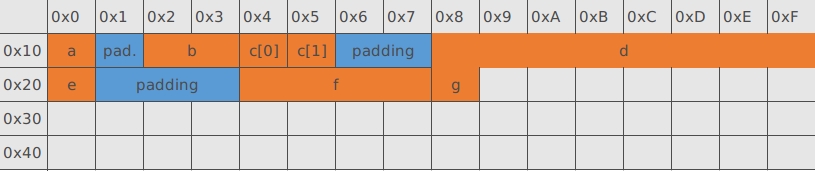
根据第一条规则:各成员的内存空间的首地址必须是对齐系数和变量本身大小较小者的整数倍,这里对齐系数是 4,因此变量 a 、数组 c 、变量 e 、变量 g 的首地址需要满足 1 的倍数,变量 b 的首地址需要满足 2 的倍数,变量 d 的首地址需要满足 4 的倍数,变量 f 的首地址需要 4 的倍数。所以也就有了上述表格中的变量存储位置。
那既然结构体内的成员都已经对齐了,为什么还存在第二条原则呢?也就是说为什么结构体内的成员已经内存对齐了,结构体本身还需要对齐?下面通过一个结构体数组来说明,比如我们定义了这样一个结构体数组:
struct data_test
{
char a; /*本身大小 1 字节*/
short b; /*本身大小 2 字节*/
char c[2]; /*数组单个成员 1 字节*/
double d; /*本身大小 8 字节*/
char e; /*本身大小 1 字节*/
int f; /*本身大小 4 字节*/
char g; /*本身大小 1 字节*/
}data[2];
我们在放置成员存储位置的时候,data[0] 按照成员对齐的原则依次存放,放到最后一个结构体成员时,如果不考虑结构体本身的对齐,按照数组元素是紧挨着存放的原则,那这个结构体数组应该是按照下图进行存储的:

从上图中我们可以看到虽然 data[0] 中的成员都对齐了,但是由于结构体本身的不对齐,导致 data[1] 中的好多成员都不对齐了,因此,在完成了结构体成员的内存对齐后,我们还需要依据第二条原则:结构体占用的总大小应该为“对齐系数”和“最大数据长度”中较小值的整数倍,来对结构体本身进行对齐,因此正确的结构体数组的存储位置应该如下图所示:
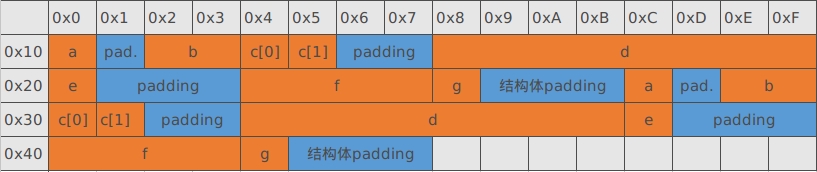
这里需要注意的是,上述原则针对的是结构体占用的总大小,而不是结构体的首地址,所以,在结构体本身还没有对齐的情况下,data[0] 的大小是 25 个字节,但是根据上述原则,在对齐系数为 4 的前提下,结构体大小应该是 4 的整数倍,所以要对结构体进行所占内存进行填充,因此:data[0] 最终的大小是 28 字节,结构体数组 data 的大小为 56 字节
结构体内成员顺序
通过上述分析我们可以很容易就想到,根据第一条原则,那么结构体成员定义的先后顺序会对最终结构体占用的内存造成影响,比如现在调整结构体 data 内成员的定义顺序,如下:
struct data_test
{
char a; /*本身大小 1 字节*/
char c[2]; /*数组单个成员 1 字节*/
char e; /*本身大小 1 字节*/
char g; /*本身大小 1 字节*/
short b; /*本身大小 2 字节*/
int f; /*本身大小 4 字节*/
double d; /*本身大小 8 字节*/
}data;
改变结构体成员顺序后的存储位置如下:

通过图片就可以看到只有一块蓝色的填充区域,在成员对齐之后,结构体大小是 20 ,已经是 4 的整数倍,已经无须再做填充,所以调整顺序后的结构体大小为 20 个字节,相比于之前没有改变顺序之前整整减少了 8 个字节,也可以看出结构体成员的定义顺序也是需要关注的一个问题,关于结构体内成员定义的顺序应该遵循这样一个原则:
按照长度递增的顺序依次定义各个成员
如何设定对齐系数
查看默认对齐系数
在上述我们对结构体内存对齐的分析中,我们都是假定对齐系数为 4 ,实际上对于编译器来说都有默认的对齐系数,我们可以输入伪指令,然后以报警信息的方式显示当前的对齐系数:
#pragma pack(show)
设置对齐系数
#pragma pack(1) /*设置一字节对齐*/
struct data_test
{
char a;
short b;
char c[2];
double d;
char e;
int f;
char g;
} data;
#pragma pack()/*取消一字节对齐,恢复默认对齐系数*/
在这里,设置1字节对齐其实也就相当于不进行内存对齐,因为任何地址都可以是 1 的整数倍,最后,需要注意的是使用这种方法设置字节对齐,要在想要取消一字节对齐的地方使用伪指令 #pragma pack() 取消一字节对齐,否则后面所定义的结构体会继续采用刚刚所设置的对齐方式。
除了采用上述这样设置一字节对齐的方式取消内存对齐,也可以采用下面的方式取消字节对齐:
struct __attribute__((packed)) data_test2
{
char a;
short b;
char c[2];
double d;
char e;
int f;
char g;
}data;
这种方式相对于上述方法来讲,不用执行取消操作,作用域只是本结构体,不会影响其他结构体的对齐方式。
最后,取消字节对齐的结构体(或者说是按照 1 字节对齐的结构体)data 的大小就是 19 个字节,即将结构体内的所有成员的字节大小相加即可。
总结
了解结构体的内存对齐,从而在定义结构体成员时按照最优的顺序进行定义,对于 RAM 资源比较紧缺的 MCU 来讲,也是非常重要的。同时,在笔者的上篇文章《union 的概念及在嵌入式编程中的应用中》,所讲到的运用 union 和 struct 嵌套来便捷地解析数据,也应该取消字节对齐(因为上篇文章最后一个例子结构体成员大小都是一个字节,内存对齐取消与否都不影响成员的存储位置,所以没取消)。
参考资料
[1] https://aticleworld.com/data-alignment-and-structure-padding-bytes/
[2] https://blog.51cto.com/zhangyu/673792
最后,如果您觉得我的文章对您有所帮助,欢迎关注我的个人公众号:wenzi嵌入式软件
