一、什么是MongoDB?
- MongoDB是一个基于分布式文件存储的文档数据库,旨在简化开发和扩展,为WEB应用提供可扩展的高性能数据存储解决方案。
- MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
二、为什么要了解MongoDB?
- 具有良好的伸缩性,在高负载的情况下,添加更多的节点,可以保证服务器性能(关系型数据库伸缩困难)。
- 数据模型直观,且它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。
- 支持多种存储引擎且查询语言丰富,可以方便的进行数据的增删改查。
- 可用性高,MongoDB的复制工具(称为副本集)提供了自动故障转移、数据冗余等功能。
三、MongoDB的关键特性
本文要介绍的MongoDB关键特性主要包含以下内容
- 文档数据模型
- ad hoc查询
- 索引
- 复制
- 加速与持久化
- 伸缩
3.1 文档数据模型
官方概述:
数据库很大程度上是由其数据模型定义的,MongoDB的数据模型是面向文档的。
MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。MongoDB文档类似于JSON对象。字段的值可以包括其他文档,数组和文档数组。
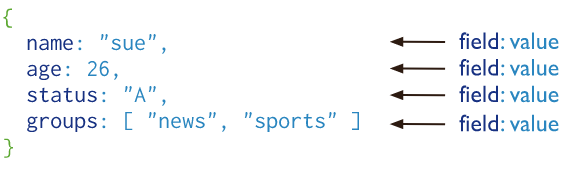
文档的优点:
- 文档(即对象)对应于许多编程语言中的本机数据类型。
- 嵌入式文档和数组减少了对昂贵连接的需求。
- 动态模式支持流畅的多态性。
注意事项:
MongoDB以二进制JSON格式存储文档数据,或者叫做BSON。BSON有相似的数据结构,是专门为文档存储设计。当我们查询Mongo并返回结果的时候,这些数据会转化为易于阅读的数据格式。
关系数据库中包含表,MongoDB拥有集合。换句话说,Mysql、Oracle等关系型数据库在表的行里保存数据,而MongoDB在集合的文档里保存数据(集合类似于表)。
MongoDB的集合中的数据存储在硬盘上,而且大部分查询需要指定查询的目标集合。
3.2 ad hoc查询
概述:
ad hoc queries(主动查询模式,也有翻译为“即席查询”的)是指不需要事先定义系统接收何种查询。
举例说明:
以关系型数据库来说,假设A表存储了整个医院门诊患者的基本信息,B表存储了患者的挂号信息,如果想查询张三医生接诊的年龄大约50的患者信息。
SELECT * FROM A LEFT JOIN B ON A.pat_no = B.pat_no WHERE A.age > 50 AND B.doctor = '张三';
等价的MongoDB查询,使用document文档作为匹配器。($gt:大于)
db.A.find({'doctor': '张三', 'age': {'$gt', 50}});
注意:
关系型数据库查询依赖于严格的范式模型,数据分别存放在A、B两张表中,MongoDB假设数据都存在每个A集合中。
以上两种方式都演示了任意组合属性的功能,这也是ad hoc查询的功能。
3.3 索引
创建索引原因:
随着数据库中添加的文档数量约来越多,查询的成本会变得约来越高,有时无异于大海捞针。
使用索引的好处:
索引类似于图书的目录,我们可以通过目录,快速查找想要知道的内容。
MongoDB的索引:
MongoDB中的索引使用了B-树(平衡树)数据结构,B-树索引也大量使用于许多关系型数据库中。
使用MongoDB,每个集合我们可以创建64个索引,例如升序、降序、复合键、哈希、文本以及地理空间索引等
3.4 复制
概述:
Mongo提供了数据库的复制特性,叫做可复制结合(replica set)。
MongoDB如何保证复制:
在多个机器上分布式存储数据,当服务器或网络出错时,实现数据冗余存取和自动灾备。
与其他数据库主从复制类似,可复制集合的主节点可以同时接受读/写操作,但是从节点只能进行读取操作。如果服务主节点失败,集群会选择一个从节点,并自动提升为主节点。当之前的主节点主节点恢复后,自动作为从节点进行工作。
3.5 加速与持久化
写入速度(write speed):
数据库给定的时间内插入、更新、删除的容量。
持久化(durability):
数据库写操作被永久保存的保证级别。
3.6 伸缩
伸缩数据库的最简单的方式就是升级服务器硬件(添加更快的磁盘、更多的内存、更强的CPU来接触数据库性能瓶颈)。
垂直扩展(vertical scaling 或 scaling up)
提升单节点参数的做法通常称为垂直扩展,垂直扩展非常简单、可靠,但是达到某个点后成本很高,最终达到一个无法低成本垂直扩展的临界点。
水平扩展(horizontally 或 scaling out)
水平扩展指的是在多台机器上分布式存储数据库,而不是提升单个节点的配置。水平扩展架构可以运行在许多台很小的、很廉价的机器上,通常可以减少硬件的成本。并且分布式存储数据可以降低宕机带来的丢失数据的后果。
MongoDB的伸缩性
MongoDB采用基于范围的分区机智来实现水平扩展,称为分片机智,它可以自动化管理每个分布式节点存储的数据。(另外,还有基于哈希和基于tag的分片机制)
分片系统处理额外的分片节点,而且它还会自动化灾备,每个独立的节点是一个可复制集合,至少由2台机器组成,确保节点失败的时候可以自动回复。
四、总结
总的来说,Mongo的概念理解起来不算太难,有关系型数据库相关经验的可以对比着进行学习。