第十一章 使用Apriori算法进行关联分析
一.导语
“啤酒和尿布”问题属于经典的关联分析。在零售业,医药业等我们经常需要是要关联分析。我们之所以要使用关联分析,其目的是为了从大量的数据中找到一些有趣的关系。这些有趣的关系将对我们的工作和生活提供指导作用。
二.关联分析的基本概念
所谓的关联分析就是从海量的数据中找到一些有趣的关系。关联分析它有两个目标,一个是发现频繁项集,另一个是发现关联规则。
关联分析常用到的四个概念是:频繁项集,关联规则,置信度,支持度。频繁项集指的是频繁同时出现的数据子集,这里的频繁是一般是根据支持度来确定的(当然你也可以根据其他的度量标准)。支持度指的是该项集最所有数据中出现的概率。关联规则指的是两个个体之间的关联性, 它一般用置信度来进行衡量。置信度指的是该项集出现的条件概率,这里的条件概率的条件也就是我们关联规则中的条件。比如 尿布->啤酒,那么此时的条件就是尿布。
三.Apriori原理
Apriori,顾名思义它是利用先验的知识,对未知的知识进行判断。
我们知道如果一个项集是频繁项集,那么它的子集必定也是频繁项集。比如{啤酒,尿布}是频繁项集,那么{尿布}和{啤酒}必定也是频繁项集。如果反向的思考的话,也就是说一个项集它不是频繁项集,那么它的超集就不会是频繁项集。Apriori算法正是利用了这个特点,对关联分析求解频繁项集的复杂度进行了很大程度的降低。
四.Apriori算法
如果直接的求解所有可能的频繁项集,那么它的复杂度太高,是无法忍受的,因此为了降低问题的复杂度,我们基于Apriori原理,提出了Apriori算法。换句话说Apriori算法是一种简便的求解频繁项集的方法。
Apriori算法的特点:
它的优点是:算法简单,容易实现
它的缺点是:不适用于大数据集
它的适用类型是:标称型数据
Apriori算法的过程是:首先生成单个商品的项集,然后根据最小支持度来去除不符合条件的项集,然后将剩下的商品进行两两组合,再根据最小支持度对不符合条件的项集进行删除,以此类推,直到所有不符合最小支持度的项集都被去掉。
以下是实现Apriori算法的python代码:
1.获取数据:

2.生成单个商品的项集:
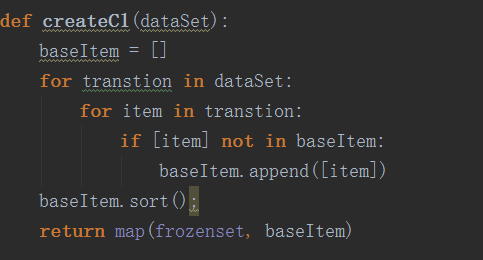
3.根据最支持度去除不符合条件的项集:
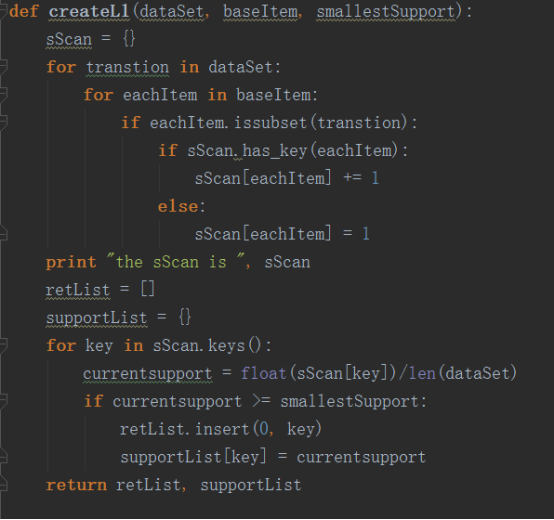
4.写一个函数用来获取包含k个item的项集

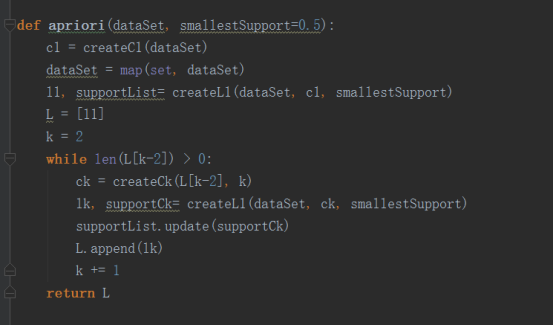
5.Apriori算法
五.从频繁项集中挖掘关联规则
频繁项集的度量指标是支持度,关联规则的度量指标是置信度。当一个规则的置信度满足一定的值时,我们就说这个规则是关联规则。关联规则具有和频繁项集类似的性质。当一规则不满足最小置信度的时候那么这个规则的子集也不满足最小置信度,换言之,如果可以从后件大小为1的规则出发,不断的产生新的规则。(这里所谓的后件,相当于结论,比如 尿布->啤酒, 这里的尿布是前件, 啤酒是后件)。
从求解关联规则的算法上看,他和apriori算法异曲同工,不过它有一个新的名字称之为分级算法。它就是先产生后件大小为1的规则,然后删除不满足置信度的规则,然后再利用剩下的规则,生出后件大小为2的规则,然后删除不满足置信度的规则,以此类推。
以下是python代码:
1.首先我们创建主函数
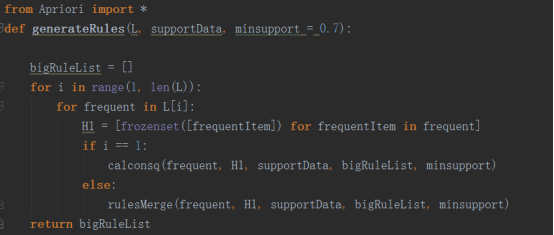
2.其次我们根据最小置信度来获取规则
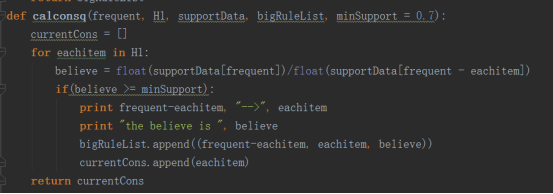
3.我们创建规则
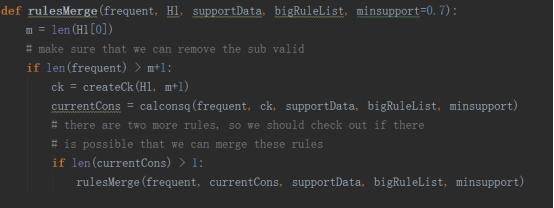
六.总结
关联分析的目的是为了寻找数据中有趣的关系,这里的有趣的关系有两层含义,一种是经常同时出现的项,也就是我们常说的寻找频繁项集;另一种是满足如果那么这种导出关系的项,也就是我们常说的寻找关联规则。频繁项集是由支持度来进行度量的,关联规则是由置信度进行度量的。
我们在进行关联分析的时候需要对结果进行组合,但是我们知道组合是很耗时的,为了简化计算,降低解空间,我们采用了Apriori算法。该算法的基本思想就是一个非频繁项集的超集也是非频繁项集。这个概念也可以拓展到关联规则,此时变为,一个规则不是关联规则那么它的超集也不是关联规则,该算法称之为分级算法。
虽然Apriori算法能够在一定的程度上减少计算量,但是因为它在每次频繁项集改变的时候都需要重新遍历一次数据库,不适用于大型数据,为了解决这个问题人们又提出了FP-growth算法。FP-growth算法和Apriori算法相比只需要遍历两次数据库,速度有了很大的提升。