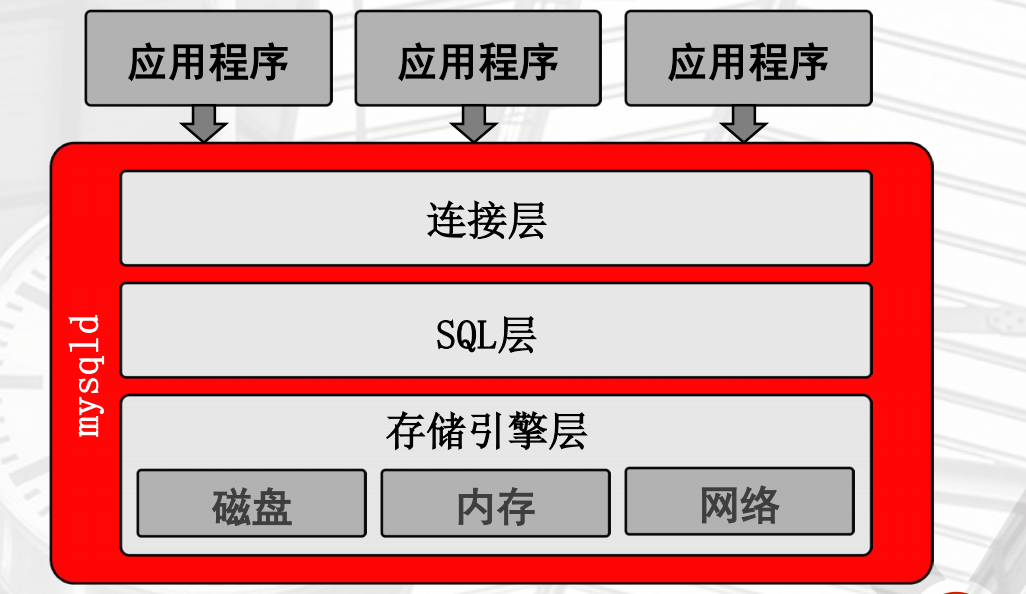
MySqld服务期程序构成
一. 连接层
mysqld是一个守护进程,无法自主启动的,它是实例中最核心的组成,负责所有协调的工作 包括线程
例子:
mysql -uroot -p123 select user,host,password from mysql.user;(当前数据库所有用户基本信息,是个表) 这条命令从开始运行到结束运行到低数据库做了什么 1) 首先客户端向服务端通过tcp/ip或socket发送请求 2) 验证用户名密码合法性 3) master thread分配一个专用线程(A thread) 接受后续的用户请求,但没有能力直接处理sql(通俗的将就是不认识他是谁),转给sql层继续处理
这时已经走完连接层了
二 .SQL层
1) sql收到了这个语句 一开始它也不理解这个语句 但是确认他认不认识之前要确认一件事 你输入的语句不能是你瞎写的语句吧(检查语法和语句) 所以你瞎写的一个语句 肯定会给你报错(error....) 2) 在检查语法的同时也在检查语意(看看你是要增还是删或改或查) '''前两步都是在解析语句''' 3) 如果语意是查(增删改)类的他就会让优化器(他认为)找到代价最小的执行方式,提供查加(增删改)类的解析器进行解析,再授权 4) 当然大多是都是看自己sql写的好不好 如果优化器觉得烂 只能走最慢的路径 如果写的好 会帮你走最快的路径 所以还是要看用户 5) 执行查询,生成磁盘数据的获取方式 6) 将信息送到存储引擎层 # 但是如果查询数据要走那么多层,会浪费时间,所有会把经常访问的数据,放到内存里 7) 获取出来的数据是二进制或也可能是16进制 8) 然后返回给sql层,sql抽象成表的方式 9) 通过连接线程,返回给用户