







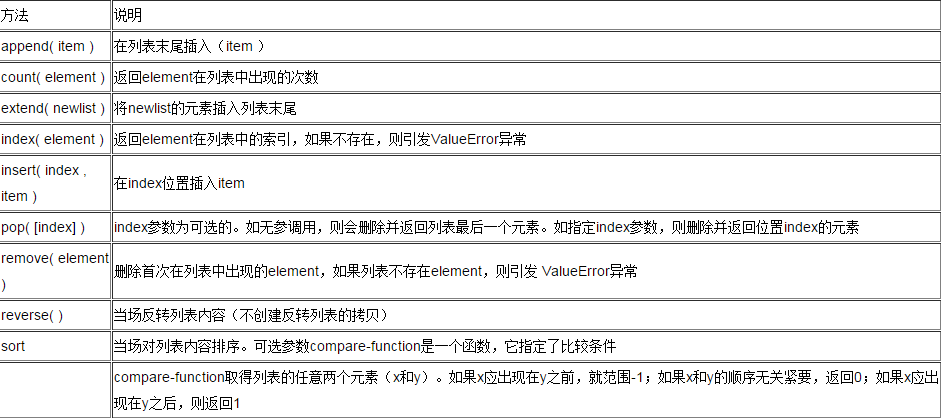
字母处理
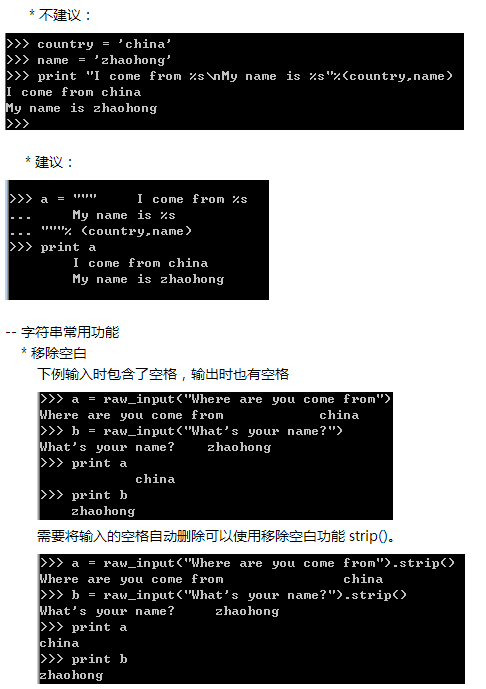
全部大写 :str.upper()
全部小写 :str.lower()

大小写互换:str.swapcase()

首字母大写,其余小写:str.capitalize()

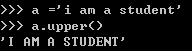
首字母大写:str.title()
格式化相关
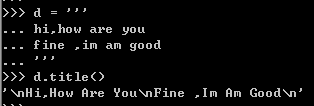
获取固定长度,右对齐,左边不够用空格补齐:str.rjust(width)
获取固定长度,左对齐,右边不够用空格补齐:str.ljust(width)

获取固定长度,中间对齐,两边不够用空格补齐:str.center(width)

获取固定长度,右对齐,左边不足用0补齐:str.zfill(width)

字符串搜索相关
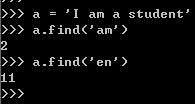
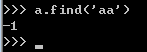
搜索指定字符串索引位置值,没有返回-1:str.find('字符串')
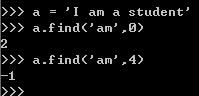
指定起始位置搜索:str.find('字符串',start)
指定起始及结束位置搜索:str.find('字符串',start,end)

从右边开始查找:str.rfind('字符串')

搜索到多少个指定字符串:str.count('字符串')

上面所有方法都可用index代替,不同的是使用index查找不到会抛异常,而find返回-1
字符串替换相关
替换old为new:str.replace('old','new')

替换指定次数的old为new:str.replace('old','new',maxReplaceTimes)

字符串去空格及去指定字符
去两边空格:str.strip()

去左空格:str.lstrip()

去右空格:str.rstrip()

去两边字符串:str.strip('d'),相应的也有lstrip,rstrip

按指定字符分割字符串为数组:str.split(' ')


字符串判断相关
是否以start开头:str.startswith('start')

是否以end结尾:str.endswith('end')

是否全为字母或数字:str.isalnum()

是否全字母:str.isalpha()

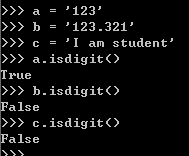
是否全数字:str.isdigit()
是否全小写:str.islower()

是否全大写:str.isupper()









实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
for letter in 'Python': # 第一个实例
print '当前字母 :', letter
fruits = ['banana', 'apple', 'mango']
for fruit in fruits: # 第二个实例
print '当前字母 :', fruit
print "Good bye!"
以上实例输出结果:
当前字母 : P 当前字母 : y 当前字母 : t 当前字母 : h 当前字母 : o 当前字母 : n 当前字母 : banana 当前字母 : apple 当前字母 : mango Good bye!
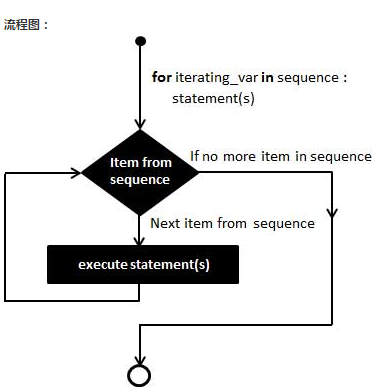
通过序列索引迭代
另外一种执行循环的遍历方式是通过索引,如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
fruits = ['banana', 'apple', 'mango']
for index in range(len(fruits)):
print '当前水果 :', fruits[index]
print "Good bye!"
以上实例输出结果:
当前水果 : banana
当前水果 : apple
当前水果 : mango
Good bye!
以上实例我们使用了内置函数 len() 和 range(),函数 len() 返回列表的长度,即元素的个数。 range返回一个序列的数。
循环使用 else 语句
在 python 中,for … else 表示这样的意思,for 中的语句和普通的没有区别,else 中的语句会在循环正常执行完(即 for 不是通过 break 跳出而中断的)的情况下执行,while … else 也是一样。
如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
for num in range(10,20): # 迭代 10 到 20 之间的数字
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
print '%d 等于 %d * %d' % (num,i,j)
break # 跳出当前循环
else: # 循环的 else 部分
print num, '是一个质数'
以上实例输出结果:
10 等于 2 * 5
11 是一个质数
12 等于 2 * 6
13 是一个质数
14 等于 2 * 7
15 等于 3 * 5
16 等于 2 * 8
17 是一个质数
18 等于 2 * 9
19 是一个质数