1.4神经网络实现鸢尾花分类
import tensorflow as tf from sklearn import datasets import pandas as pd import numpy as np import matplotlib.pyplot as plt # 数据的读入 x_data = datasets.load_iris().data # 读入特征 y_data = datasets.load_iris().target # 读入输出 print(x_data.shape)
(150, 4)
# 数据集乱序:为了公正,打乱数据,但特征标签一一对应 np.random.seed(116) # 设置相同的随机种子 np.random.shuffle(x_data) # 进行重新洗牌 np.random.seed(116) np.random.shuffle(y_data) tf.random.set_seed(116) print(x_data.shape)
(150, 4)
# 将数据分为训练集和测试集 x_train = x_data[:-30] # 取前120个数据作为训练集 y_train = y_data[:-30] x_test = x_data[-30:] # 取后30个数据作为测试集 y_test = y_data[-30:] print(x_data.shape)
(150, 4)
# 对数据类型进行转换,避免与参数矩阵相乘时候报错,y不参与计算不要转换 x_train = tf.cast(x_train,tf.float32) x_test = tf.cast(x_test,tf.float32) # 配对:配成(输入特征和标签对),每次喂入一小块(batch) train_db = tf.data.Dataset.from_tensor_slices((x_train,y_train)).batch(32) test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test)).batch(32) print(train_db)
<BatchDataset shapes: ((None, 4), (None,)), types: (tf.float32, tf.int32)>
# 定义神经网络中所有的可训练参数,数据最终非为3类,且特征数为4,所以w为4X3 w1 = tf.Variable(tf.random.truncated_normal([4,3],stddev = 0.1,seed = 1)) b1 = tf.Variable(tf.random.truncated_normal([3],stddev = 0.1,seed = 1)) print(w1,' ',b1) lr = 0.1 # learning rate 定义学习率 train_loss_results = [] # 将训练的损失值进行存储,后续进行画图 test_acc = [] # 将每一轮的准确率保存,进行画图 epoch = 500 # 循环500次 loss_all = 0 # 每一轮分为4个step,loss_all记录四个step生成4个loss
<tf.Variable 'Variable:0' shape=(4, 3) dtype=float32, numpy=
array([[ 0.08249953, -0.0683137 , 0.19668601],
[-0.05480815, 0.04570521, 0.1357149 ],
[ 0.07750896, -0.16734955, -0.10294553],
[ 0.15784004, -0.13311003, 0.06045312]], dtype=float32)>
<tf.Variable 'Variable:0' shape=(3,) dtype=float32, numpy=array([-0.09194934, -0.12376948, -0.05381497], dtype=float32)>
# 训练部分 # 嵌套循环迭代,with结构更新参数,显示当前loss for epoch in range(epoch): # 数据集级别迭代,每次更新数据 # 训练部分 for step, (x_train, y_train) in enumerate(train_db): # batch级别迭代 with tf.GradientTape() as tape: # 记录梯度信息 # 前向传播过程计算y,没个数据是1X4,w是4X3,输出为1X3的数据 y = tf.matmul(x_train, w1) + b1 y = tf.nn.softmax(y) # 是输出符合概率分布,与独热编码作用同级,可求得loss值 y_ = tf.one_hot(y_train, depth=3) # 将标签值转化为独热编码形式,方便求loss # 计算总的loss # 原始数据y是010或者001,100格式,用y_-y可求得到误差,但每一组有三个输出y,可平方后求平均 loss = tf.reduce_mean(tf.square(y_ - y)) # 采用均方误差损失函数 loss_all += loss.numpy() # 将每个steploss累加,为后续求平均 # 计算loss各个参数的梯度 grads = tape.gradient(loss, [w1,b1]) # 对w1,b1求导 # 实现梯度更新 w1 = w1 - ir *w1_grad b = b - Ir * b_grad w1.assign_sub(lr * grads[0]) # 参数w1自更新 b1.assign_sub(lr * grads[1]) # 参数b1自更新 # 每组 epoch,打印loss值 print("Epoch {},loss {}".format(epoch, loss_all / 4)) train_loss_results.append(loss_all / 4) loss_all = 0 # 将loss_all归为0,为下次计算做准备 # 测试部分 # total_correct为预测对的个数,total_number为测试的总样本数,将这两个变量初始化为0 total_correct, total_number = 0, 0 for x_test, y_test in test_db: # 使用更新后的参数进行测试 y = tf.matmul(x_test, w1) + b1 y = tf.nn.softmax(y) pred = tf.argmax(y, axis=1) # 返回y中最大数据的索引,即预测分类值 # 将pred数据类型为整数型转换为浮点类型方便计算 pred = tf.cast(pred, dtype=y_test.dtype) # 分类正确,则correct=1,反之为0,将bool类型转化为整型 correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32) # 将每个batch的correct加起来 correct = tf.reduce_sum(correct) # 将所有batch中correct加起来 total_correct += int(correct) # total_number为总的测试集样本数 total_number += x_test.shape[0] # 准确率为total_correct/total_number acc = total_correct / total_number test_acc.append(acc) print("Test_acc:", acc) print("------------------------")
Epoch 0,loss 0.2821310982108116 Test_acc: 0.16666666666666666 ------------------------ Epoch 1,loss 0.25459614396095276 Test_acc: 0.16666666666666666 ------------------------ Epoch 2,loss 0.22570250555872917 Test_acc: 0.16666666666666666 ------------------------ Epoch 3,loss 0.21028399839997292 Test_acc: 0.16666666666666666 ------------------------ Epoch 4,loss 0.19942265003919601 Test_acc: 0.16666666666666666 ------------------------ Epoch 5,loss 0.18873637542128563 Test_acc: 0.5
.......
.......
Epoch 494,loss 0.032431216444820166 Test_acc: 1.0 ------------------------ Epoch 495,loss 0.032404834404587746 Test_acc: 1.0 ------------------------ Epoch 496,loss 0.03237855713814497 Test_acc: 1.0 ------------------------ Epoch 497,loss 0.03235237207263708 Test_acc: 1.0 ------------------------ Epoch 498,loss 0.03232626663520932 Test_acc: 1.0 ------------------------ Epoch 499,loss 0.032300274819135666 Test_acc: 1.0
# 绘制Loss曲线 plt.title('Loss fuction curve') # 标题 plt.xlabel("Epoch") # x轴变量名称 plt.ylabel('Loss') # y轴变 量名称 plt.plot(train_loss_results,label='$Loss$') # 逐点画出曲线,并且链接 plt.legend() # 画出曲线图标 plt.show() # 画出图像 # 绘制Acc曲线 plt.title('Acc curve') # 标题 plt.xlabel("Epoch") # x轴变量名称 plt.ylabel('Acc') # y轴变量名称 plt.plot(test_acc,label='$Accuracy$') # 逐点画出曲线,并且链接 plt.legend() # 画出曲线图标 plt.show() # 画出图
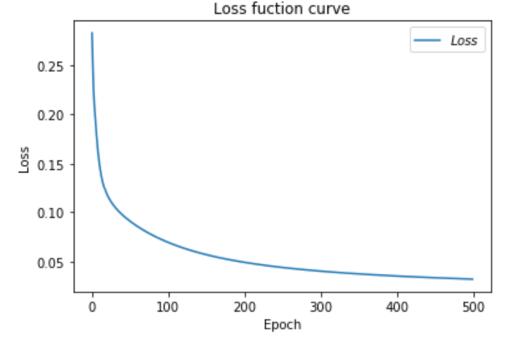
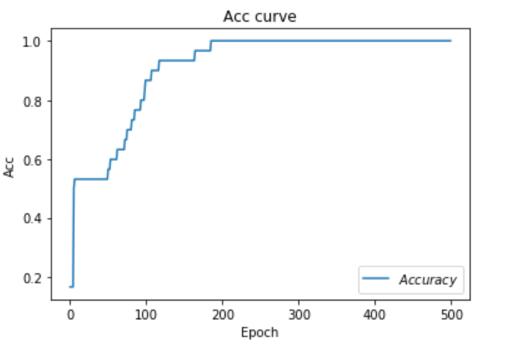
本节介绍了一个简单得神经网络从建立,到训练以及测试得整个过程,希望小伙伴们都能掌握。