3.machinelearning的好伙伴plt
文件在下面提取:
链接:https://pan.baidu.com/s/1W3WzNMp_n4B39pcQhwP3SA
提取码:7b7r
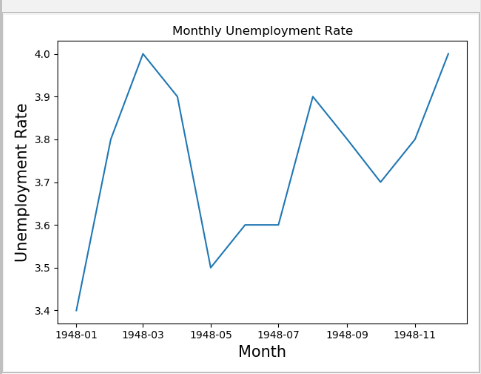
折线图
import pandas as pd import matplotlib.pyplot as plt unrate = pd.read_csv('UNRATE.csv') unrate['DATE'] = pd.to_datetime(unrate['DATE']) print(unrate.head()) first_twelve = unrate[0:12] #第一个参数是x轴的参数,第二个数值为y轴参数 plt.plot(first_twelve["DATE"],first_twelve['VALUE']) plt.xticks(rotation = 0) # 对x轴的数值角度进行旋转 # 为x轴和y轴加上标签,设置字体大小 plt.xlabel('Month',fontsize = 15) plt.ylabel('Unemployment Rate',fontsize = 15) # 对图像设置题目 plt.title('Monthly Unemployment Rate') plt.show()
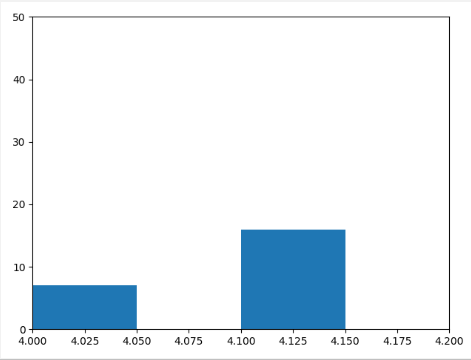
直方图
import matplotlib.pyplot as plt import numpy as np # 直方图 reviews = pd.read_csv('fandango_scores.csv') cols = ["FILM","RT_user_norm","Metacritic_user_nom","IMDB_norm","Fandango_Ratingvalue","Fandango_Stars"] nom_reviews = reviews[cols] # 对每个数值进行个数的统计 fandango_distribution = nom_reviews['Fandango_Ratingvalue'].value_counts() imdb_distribution = nom_reviews['IMDB_norm'].value_counts() # 按照索引大小排序 fandango_distribution = fandango_distribution.sort_index() imdb_distribution = imdb_distribution.sort_index() fig, ax = plt.subplots() # 绘制直方图 # ax.hist(nom_reviews['Fandango_Ratingvalue'],bins=20) # 指定bins的个数 ax.hist(nom_reviews['Fandango_Ratingvalue'],range=(4,5),bins=20) # 只统计4-5之间的 ax.set_ylim(0,50) # 设置y轴区间 ax.set_xlim(4.0,4.2) # 设置x轴区间 plt.show()
盒图
import pandas as pd import matplotlib.pyplot as plt import numpy as np # 直方图 reviews = pd.read_csv('fandango_scores.csv') cols = ["FILM","RT_user_norm","Metacritic_user_nom","IMDB_norm","Fandango_Ratingvalue","Fandango_Stars"] nom_reviews = reviews[cols] # 对每个数值进行个数的统计 fandango_distribution = nom_reviews['Fandango_Ratingvalue'].value_counts() imdb_distribution = nom_reviews['IMDB_norm'].value_counts() # 按照索引大小排序 fandango_distribution = fandango_distribution.sort_index() imdb_distribution = imdb_distribution.sort_index() print(fandango_distribution) print(imdb_distribution) fig, ax = plt.subplots() # 绘制盒图 ax.boxplot(nom_reviews['RT_user_norm']) ax.set_xticklabels('Rotten Tomatoes') ax.set_ylim(0,5) plt.show()

柱状图
import pandas as pd import matplotlib.pyplot as plt import numpy """ *********当对数据进行切片才能直接用date[]的形式,在定位莫一行只能用loc或者date[0:1]形式 """ """ 用ax画图,fig控制实际的参数 """ reviews = pd.read_csv('fandango_scores.csv') cols = ["FILM","RT_user_norm","Metacritic_user_nom","IMDB_norm","Fandango_Ratingvalue","Fandango_Stars"] nom_reviews = reviews[cols] print(nom_reviews[0:1]) # 打印第一行数据 num_cols = ["RT_user_norm","Metacritic_user_nom","IMDB_norm","Fandango_Ratingvalue","Fandango_Stars"] # 得到柱状图的数值 bar_values = nom_reviews.loc[0][num_cols] print(bar_values) # 得到柱状图的x轴坐标位置 ticks_position = range(1,6) # 定义坐标轴上每个位置 bar_position = numpy.arange(5) + 1 # 画图 fig ,ax = plt.subplots() # 用ax画bar型图 # 竖直柱状图 ax.bar(bar_position,bar_values,0.5) # 第三个参数定义柱的宽度 ax.set_xticks(ticks_position) # 设置坐标轴有多少位置 ax.set_xticklabels(num_cols,rotation = 50) # 设定坐标轴标签 ax.set_xlabel('Name') ax.set_ylabel('Values') ax.set_title('first col values')

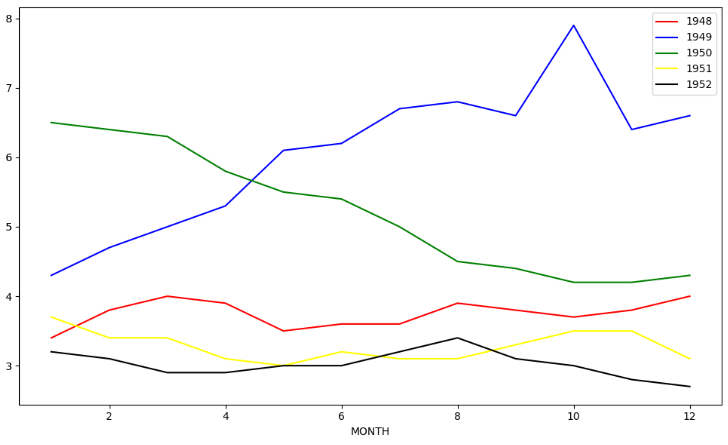
子图构建
import matplotlib.pyplot as plt import pandas as pd import numpy as np # 引入数据 unrate = pd.read_csv("UNRATE.csv") unrate['DATE'] = pd.to_datetime(unrate['DATE']) # 创建子图布局 fig = plt.figure(figsize=(6,6)) # 创建图形,指定子图大小 ax1 = fig.add_subplot(4,3,1) # 指定图像在四行三列图像的1号位置 ax2 = fig.add_subplot(4,3,2) ax3 = fig.add_subplot(4,3,6) ax1.plot(np.random.randint(1,5,5),np.arange(5)) ax2.plot(np.random.randint(1,5,5),np.arange(5)) ax3.plot(np.random.randint(1,5,5),np.arange(5)) plt.show() # 将多条线条画在一个图上 # 画出多个线并对每个线段进行标识 unrate["MONTH"] = unrate["DATE"].dt.month # 得到每个月份对应的数据 unrate["MONTH"] = unrate["DATE"].dt.month fig = plt.figure(figsize=(10,6)) color = ['red','blue','green','yellow','black'] for i in range(5): start = i*12 end = (i+1)*12 label = str(1948+i) # 添加标签 plt.plot(unrate[start:end]["MONTH"],unrate[start:end]["VALUE"],c = color[i],label=label) # 但是不能显示 plt.legend(loc='best') # lengend解释说明,loc = 'best',表示框的显示位置 plt.xlabel("MONTH") plt.ylabel("RATE") plt.show()
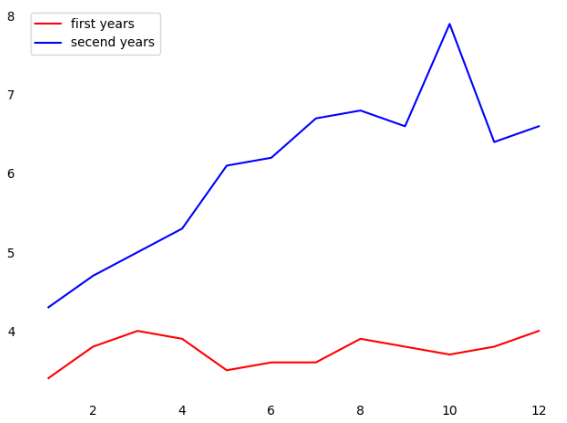
图像细节设置
import pandas as pd import matplotlib.pyplot as plt unrate = pd.read_csv("UNRATE.csv") unrate["DATE"] = pd.to_datetime(unrate["DATE"]) unrate["MONTH"] = unrate['DATE'].dt.month fig ,ax = plt.subplots() ax.plot(unrate[0:12]['MONTH'],unrate[0:12]['VALUE'],c='red',label='first years') ax.plot(unrate[12:24]['MONTH'],unrate[12:24]['VALUE'],c='blue',label='secend years') # 去除边界 for key,spine in ax.spines.items(): spine.set_visible(False) # 去除坐标轴尺度 ax.tick_params(bottom = [],top = [], right = [], left = []) ax.legend(loc = 'best') plt.show()