当代苦逼大学生,人在家中坐,课从天上来.没办法,想偷懒,于是就对目前在上的网课平台进行了分析
嘿嘿 先来张效果图:
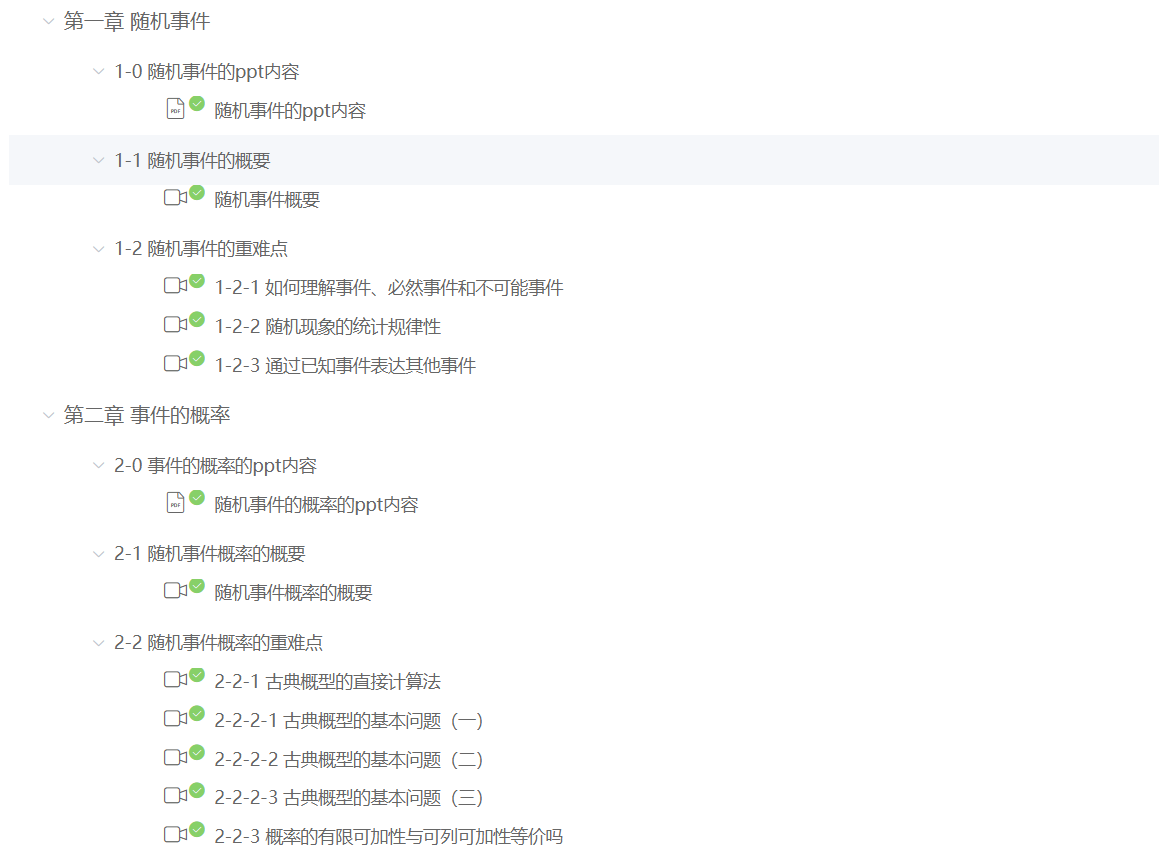
好勒,废话不多说,上主题
其实我们在看网课的时候,本地的网页会通过ajax请求定时的发送当前所观看的视频秒数到服务器上,并记载,所以通过拉取本地的进度条是达不到秒过的效果的
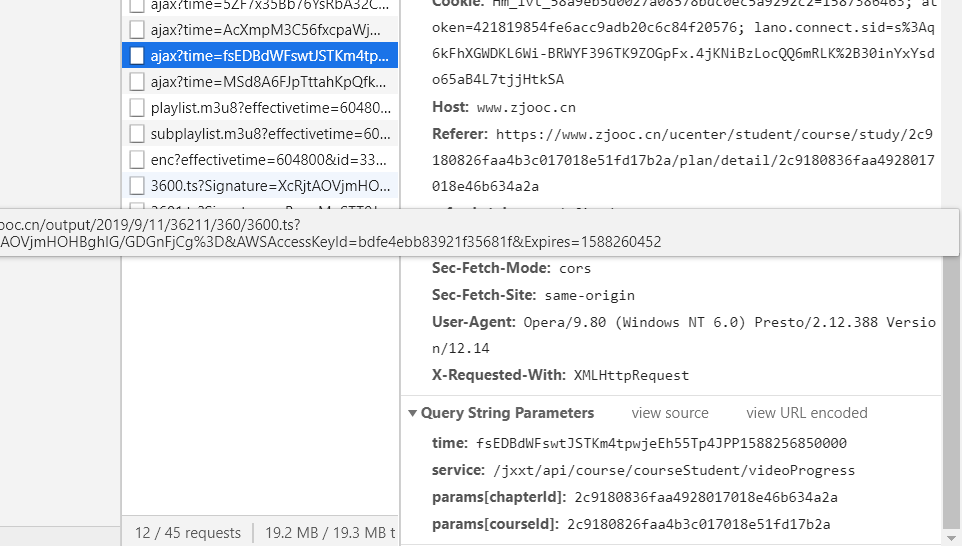
额,因为已经刷好了,不知道为什么就没发送了,不过这张图也能表达意思,通过上面的参数可以发现,有courseId,chapterId,一个固定的server,正确的发送参数还应该有playtime,percent,最后一个是变化的time,
time后面的值看起来像一个时间
好了,既然知道发送ajax请求需要的是这些参数,那我们就来找找这些参数从哪里获得的,service好说,固定的参数,我们不用管它,courseId和chapterId顾名思义,
像这种有代表性的参数,不是在查看该课程的首页出现,就是在观看具体某一章节出现,playtime是当前播放了多少时间,percent是根据当前播放的时间除以总时长的百分比,播放的单位是s,最后一个加密的time就显得尤为重要了,我们要找到这个time是怎么实现的,很明显
是通过js来生成的
因为提交的域名是https://www.zjooc.cn/ajax 后面加的就是上面说的4个参数,且是get的请求
通过对url的全局搜索
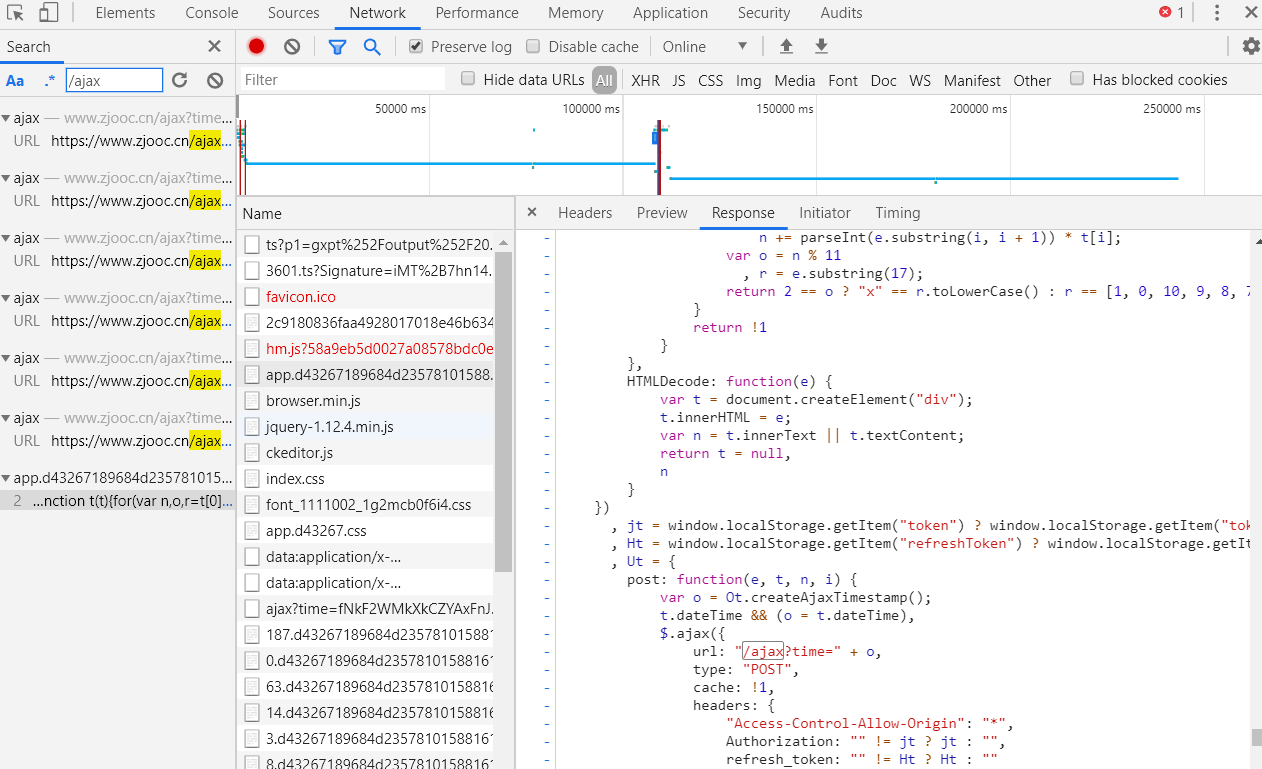
找到了对应time参数的js文件,可以看出time的关键点是一个叫做createAjaxTimestamp的函数调用,通过搜索,成功找到对应的加密函数

作者的js水平有限,就用python的来模拟js环境来执行对应的函数
通过这里,已经能实现单个视频
那么如何实现批量化秒过呢,既然一个章节的视频对应一个chapterId,那肯定可以通过对应的方法拿到所有的chapterId
通过在课程的首页进行刷新,捕获到一个ajax的数据包,对应的请求和响应数据如下
-
请求数据

-
响应数据

请求的参数也比较单一,courseId是根据不同的课程变化的,还有一个time的参数就是上文中写到过的
这里的响应体就非常有价值了,里面对应了每个视频的chapterId,名字,还有最重要的duration,在上面的介绍中肯定有小伙伴有疑问,我可以任意编造playtime,但是时长我不知道呀,怎么编写对应的percent
嘿嘿,这时duration数据就非常重要啦,后文中我们可以通过duration来填写playtime达到秒过的效果
因为里面的数据太多了,这里我就通过画图来描述一级菜单,二级菜单,三级菜单的结构图
先给一张实物图

额,手画的草图
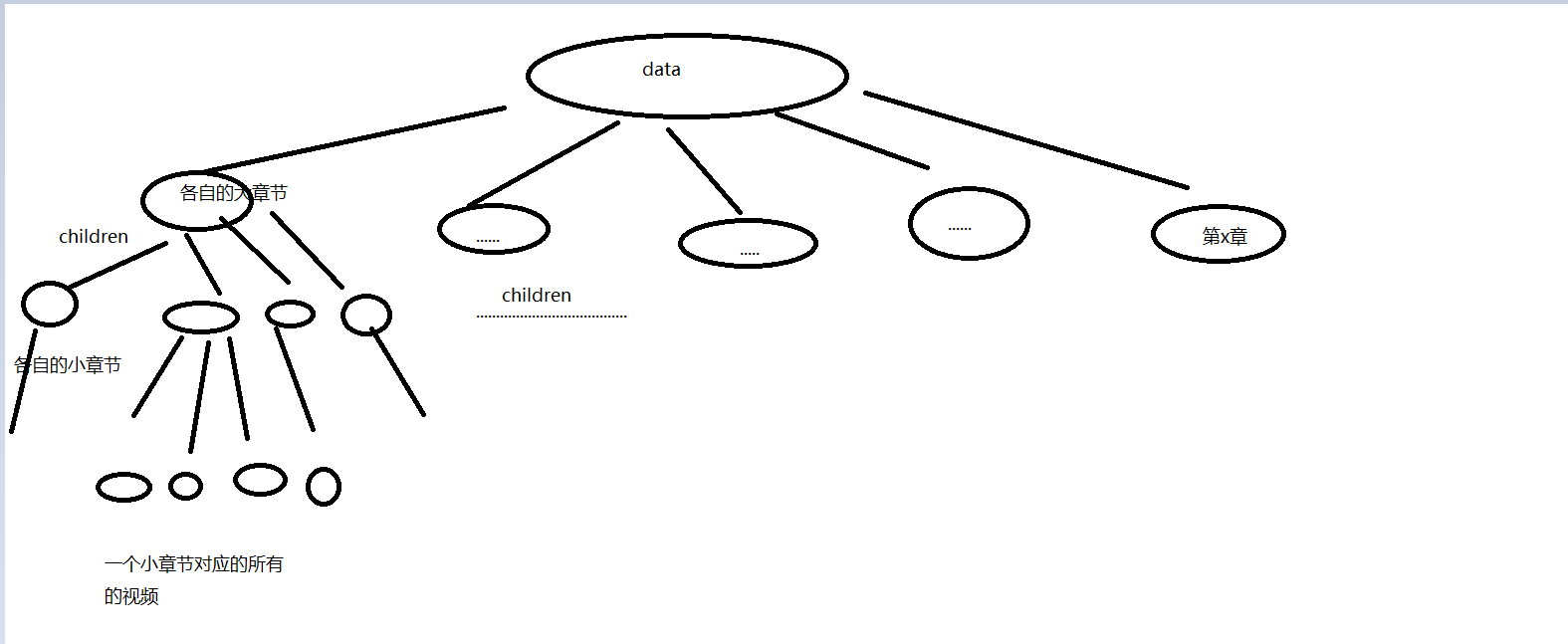
响应体的数据大致就是这样的菜单结构,再通过实现对应的逻辑,就可以拿到每一个视频的chapterId和duration
这里就献上本人low逼的代码吧
# -*- coding: utf-8 -*-
# @Author : __will__
import time
import requests
import execjs
class Zjooc(object):
node = execjs.get()
url = 'https://www.zjooc.cn/ajax'
get_video_playing_server = '/learningmonitor/api/learning/monitor/videoPlaying'
get_pdf_finished_server = '/learningmonitor/api/learning/monitor/finishTextChapter'
get_student_course_server = '/jxxt/api/course/courseStudent/getStudentCourseChapters'
def __init__(self, course_id,cookie):
self.headers = {
'User-Agent': 'Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14',
'Cookie': cookie
}
self.course_id = course_id
def get_student_course_info(self):
ctx = self.node.compile(open('zjooc.js').read())
ajax_time = ctx.eval('createTimesatamp(32)')
ts = ajax_time + str(int(time.time()) * 1000)
student_params = {
'time': ts,
'service': self.get_student_course_server,
'params[pageNo]': '1',
'params[courseId]': self.course_id,
'params[urlNeed]': '0'
}
course_info = requests.get(self.url,params=student_params,headers=self.headers).json()
return course_info
def parse_course_info(self):
data = self.get_student_course_info()
single_course_list = []
course_list = data['data']
# 获取每个章节
for item in course_list:
# 获取每个小章节的事件节点
chapter_node = item['children']
for i in chapter_node:
children_node = i['children']
for child in children_node:
course_dict = {}
course_dict['id'] = child['id']
course_dict['name'] = child['name']
course_dict['resourceType'] = child['resourceType']
if child['resourceType'] == 1:
course_dict['vedioTimeLength'] = child['vedioTimeLength']
single_course_list.append(course_dict)
return single_course_list
def run(self):
context = self.node.compile(open('zjooc.js').read())
single_course_list = self.parse_course_info()
for item in single_course_list:
ajax_time = context.eval('createTimesatamp(32)')
ts = ajax_time + str(int(time.time())+ 600) + '000'
if item['resourceType'] == 1:
video_params = {
'time': ts,
'service': self.get_video_playing_server,
'params[chapterId]': item['id'],
'params[courseId]': self.course_id,
'params[playTime]': item['vedioTimeLength'],
'params[percent]': '100'
}
result = requests.get(self.url,params=video_params,headers=self.headers).json()
if result['resultCode'] == 0:
print(item['name']+'的视频''------秒过成功')
else:
print(item['name']+'的视频''------秒过失败')
else:
pdf_params = {
'time': ts,
'service': self.get_pdf_finished_server,
'params[chapterId]': item['id'],
'params[courseId]': self.course_id,
}
result = requests.get(self.url, params=pdf_params, headers=self.headers).json()
if result['resultCode'] == 0:
print(item['name'] +'的pdf' '------秒过成功')
else:
print(item['name'] +'的pdf' '------秒过失败')