跳表
跳表(skiplist)是一种有序的数据结构,是在有序链表的基础上发展起来的。
在 Redis 中跳表是有序集合(sort set)的底层实现之一。
说到 Redis 中的有序集合,是不是和 Java 中的 TreeMap 很像?都是有序集合。
那么:
- 为什么会出现跳表这种数据结构呢?
- 跳表的原理是什么?Redis又是怎么实现的?
- 和同类中(二叉平衡树)相比,有什么优缺点呢?
为什么会出现跳表?跳表解决了什么样的问题?
跳表可以说是平衡树的一种替代品。它也是为了解决元素随机插入后快速定位的的问题。到这里,你可能会说 hash 表解决的不是很好吗?插入和查找都是 O(1) 的时间复杂度。是的,hash表是很好的解决了查找的问题,但若想要有序呢?这个时候 hash 表就不行了,二叉查找树可以解决这个问题。
但是由于二叉查找树在按大小顺序进行插入的时候,就会退化为链表。所以又出现了平衡二叉树,而根据算法不同,又分为AVL树、B-Tree、B+Tree、红黑树等。看到这里,是不是头都大了(天呐,这么多算法,这么复杂的实现)。
而跳表的出现就是为了解决平衡二叉树复杂的问题。所以它可以说是平衡树的一种替代品。它以一种较为简单的方式实现了平衡二叉树的功能。
跳表的原理是什么?Redis又是怎么实现的?
跳表的原理网上一搜一大堆,这里就不重复了,这里给出看起来不错的两篇文章:
http://copyfuture.com/blogs-details/6097031f2015d499a2321e23ea3f1324
https://lotabout.me/2018/skip-list/
Redis 中跳表由 redis.h/zskiplistNode(跳表节点)和 redis.h/zskiplist(跳表节点的相关信息,比如节点的数量、表头、表尾指针)两个结构定义。他们的具体结构如下:
/*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
/*
* 跳跃表
*/
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数(表头节点不计)
int level;
} zskiplist;
/*
* 有序集合
*/
typedef struct zset {
// 字典,键为成员,值为分值
// 用于支持 O(1) 复杂度的按成员取分值操作
dict *dict;
// 跳跃表,按分值排序成员
// 用于支持平均复杂度为 O(log N) 的按分值定位成员操作
// 以及范围操作
zskiplist *zsl;
} zset;
一个完整跳表的示意图如下(出自《Redis设计与实现第二版》第五章:跳跃表):
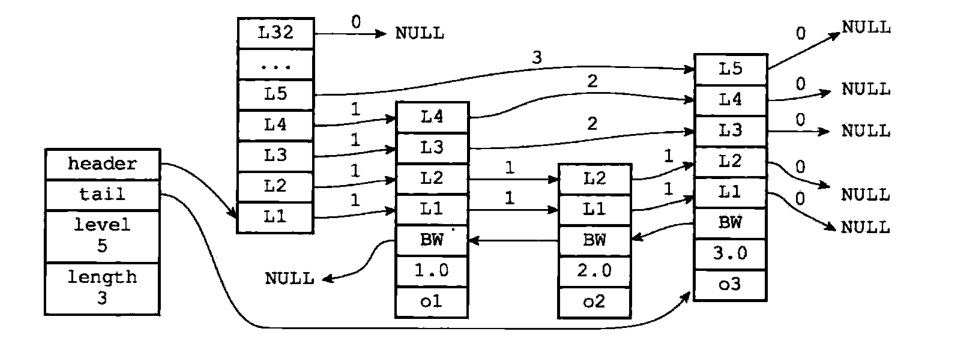
位于图片最左边的是 zskiplist 结构,该结构包含以下属性:
- header :指向跳表的表头节点。
- tail :指向跳表的表尾节点。
- level :记录目前跳表内,层数最大的那个节点的层数(表头节点的层数不计算在内)。
- length :跳表的长度,即跳表目前包含节点的数量。
位于 zskiplist 结构右方的是四个 zskiplistNode 结构,该结构包含以下属性:
- level :层,节点中用 L1、L2、L3 等字样标记节点的各个层,L1 代表第一层,L2 代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则表示前进指针所指向节点和当前节点的距离,跨度越大,相距越远。在上面的图片中,连线上带有数字的箭头就代表前进指针,数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。
- backward :后退指针,节点中用 Bw 字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
- score :各个节点中的 1.0、2.0、3.0 是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。
- obj :成员对象,各个节点中的 o1、o2、o3 是节点所保存的成员对象。
注:
- 表头节点不存储数据,所以图中省略了表头节点的部分属性。
- 由于跳表中查找元素的时间复杂度是 O(logn) ,所以有序集合(zset)中又定义了一个存储键值对的字典,所以有序集合中根据 key 查找分数的时间复杂度为 O(1)。
跳表和同类中(二叉平衡树)相比,有什么优缺点呢?
这里我就直接引用网上的资料了,如下(出自:http://copyfuture.com/blogs-details/6097031f2015d499a2321e23ea3f1324):

上期思考问题
上篇思考问题: Java 中 HashMap 关于扩容和收缩的3个问题是怎么解决的呢?
(1)触发条件是什么?是手动触发还是自动触发。
(2)扩容或者收缩的规则是什么?具体过程是怎样的?
(3)当哈希表在扩容时,是否允许别的线程来操作这个哈希表?
首先,Java 中的 HashMap 没有收缩,只有扩容。
-
扩容的触发条件是:put时先添加元素,添加完元素之后,看当前size是否大于hash表总容量*扩容因子。若是,则扩容。 如下:
/** * The next size value at which to resize (capacity * load factor). * * @serial */ int threshold; final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { ... ++modCount; if (++size > threshold) resize(); // 重新调整大小。 afterNodeInsertion(evict); return null; } -
扩容的规则是:每次扩容二倍,如果超过最大值(1 << 30)则不扩容。具体代码如下:
/** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. */ static final int MAXIMUM_CAPACITY = 1 << 30; final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } ... } -
Java中的 HashMap 扩容是一次性的,是线程不安全的,不允许别的线程来操作 hash 表。所以 Java 有 Hashtable、ConcurrentHashMap 这些线程安全的 Hash 表。
本期思考问题
暂无
参考资料:
https://juejin.im/post/57fa935b0e3dd90057c50fbc
http://copyfuture.com/blogs-details/6097031f2015d499a2321e23ea3f1324
https://lotabout.me/2018/skip-list/
《Redis设计与实现(第二版)》