Raft协议
Raft协议基于日志实现了一致性
实现备份的是机制:复制状态机Replicated State Machine,如果两个相同的、确定性的状态机从同一状态开始,以相同顺序输入相同的日志,则两个状态机最终也会保持一致
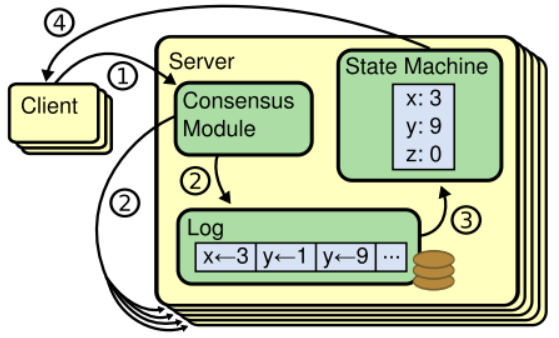
Raft了实现Consensus Module
Consensus Module作为一致性模块对外服务,负责接收客户端的消息,响应请求,并追加到本地日志,一致性模块保证每个机器上的log的一致性
请求到来时,带上(term,commitindex)和append log 去要求Follower追加消息,Follower会先判断(term,index)是否和当前最大的消息相同,如果相同就会追加,否则会拒绝
一致性模块负责复制消息到其他服务器节点,本地日志commit成功后立即应用到状态机
CNew用于服务器增加或者减少节点的情况
Leader:处理与客户端交互,处理消息
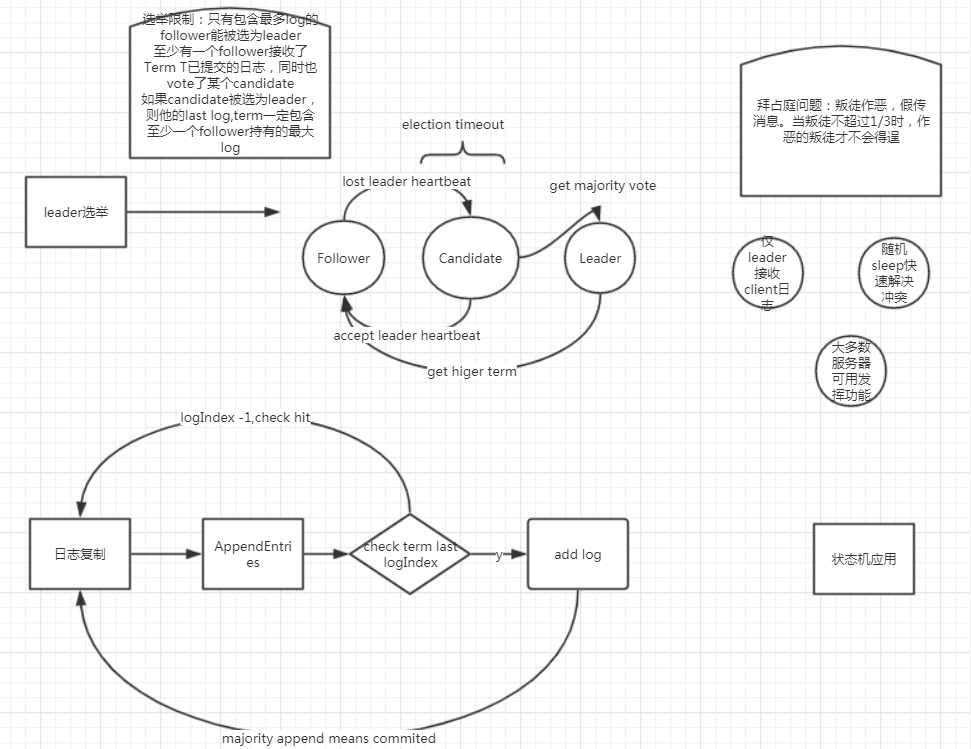
Follower:选民,转发请求到leader
Candidate:候选人,可以参选成为leader,不是所有Follower都能成为Candidate,只有数据较完整的才可以。如果Candidate发现自己的term落后了就会退回到Follower
RequestVote:选举期间的RPC消息
AppendEntries:leader选出后向Follow复制日志的RPC消息,心跳也是AppendEntries,不过日志内容为空
raft协议原理
- Election Safty:每个任期只有一个leader
- Leader Append-Only:leader仅新增日志,不能重写或删除日志条目
- Log Match:如果两个日志的term和index相同,则两个状态机的完全相同
- Leader Completeness:如果一条日志被Commit过,那么大于该日期条目的term的所有节点,都应该有该条目
- State Machine Safty:如果某个server将日志交由状态机处理了,那么所有server交由状态机执行的日志条目数量完全相同
Election Safty
- 竞选leader时,Candidate获取过半的票数,就能成为leader
如果出现大家都投票给自己或两台机器各获得一般的票数,则随机Sleep重新选举 - 先到先得
- Follower遵循规则:选举term比自己大 -> index 比自己大,否则不会选举该Candidate
- 随机超时,更快选出leader
- 如果给candidate投票了,需要持久化记录投给谁了;否则如果follower重启,可能导致前后投票不相同
Log Match
leader向follower复制日志时,会带上当前最新的(该日志前)term和index,follower接收到请求后,会先比对自身最新的日志的term和index,匹配时才会追加,否则拒绝,这时leader会往前找term 和index,尝试和follower匹配成功,然后从该位置开始复制日志到follower
Leader completeness
不能提交之前任务内的日志作为Commit 点
选主
如果一个Follower在一定时间没有收到Leader的心跳,则开始重新选主
Follower把自己的状态变更为Candidate,并递增本地term,并持久化,向其他机器拉票,并给自己投票,开始等待,直到
- candidate赢得选主,获得多数派的选票
- 其他机器成为leader,心跳发现term大于等于本机term,自动变为Follower
- 超时未能选主成功
- 确保包含所有commit日志的主机才能成为candidate
选举时candidate至少要和多数派主机通信,当发现candidate比本机的term,logindex还小时,follower就会拒绝投票
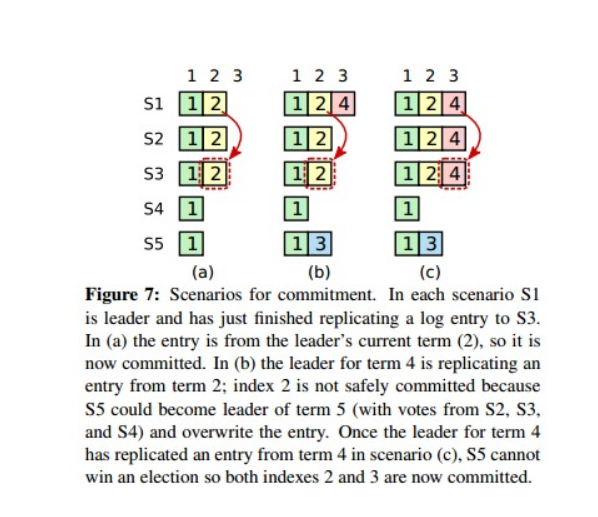
如何判断commit与否
leader发现log已经被多数派的主机写盘了,就认为commited
CNew,集群拓扑变化
将Cnew发送出去,如果Follower发现自己已经不在拓扑结构中,则退出
- 生成logEntry Cold U Cnew
- 推送给Follower
- 过半则Commit
- 生成CNew Log Entry,推送到所有Follower
- Follower更新Cnew配置,了解自己在集群中的位置,如果新配置中已无当前节点,则自动退出
- Leader收到多数派确认后,回复客户端执行命令成功
No op Entry
leader在选举刚结束后,可能有一些Entry是已经提交的,有一些是还未提交的,因此需要提交一个No op Entry来确保和Follower达到一致了,同时,也为了防止客户端来了新请求后不能及时到达
疑问
到底是如果commit的,Raft是如果保证状态机一致性的
情况1:
client - > leader -> Log AppendEntries - > 多数派确认 ->已经commited -> 返回client:成功
由于已经到多数机器上,即使重新选主,也一定会带有最新的log
但是这种情况呢
情况2:
client - > leader -> Log AppendEntries - > 未获取多数派确认 ->不算作Commited -> 返回client:失败重试
返回给client失败了,此时若leader断开网络,可能出现部分确认的实例被选中为leader?岂不是实际成功了
Raft维护的以下属性是否可以解释此问题:
- 如果在不同的日志文件内有2个条目有相同的index和term, 它们保存着相同的命令;
- 如果在不同的日志文件内有2个条目有相同的index和term,那么之前的所有条目都是相同的;
- 只有被多数派follower确认了才会认为Commit了
依据上述特性,出现情况2时,不满足特性3,client会收到执行失败的响应,此时应该做的是不断重试,直到成功,也就是说raft协议允许情况3,也要求client如果想要强一致性,就得不断的重试
raft保证了已提交日志的一致性
follower发现自己已提交的term和logindex 比leader还大怎么办?
leader退化成follower
leader何时告诉follower log已提交了?
在下一个心跳告诉所有follower更新Commited项目
Raft约束日志是连续commit的,leader维护最大已经commit的日志id,并将这个信息附加到AppendEntries告知follower,follower了解到之后即可将本机已有的且已经commit的日志应用到本地的状态机。
参考文章
http://thinkinjava.cn/2019/01/12/2019/2019-01-12-lu-raft-kv/
https://raft.github.io/
https://blog.csdn.net/weixin_39843367/article/details/82498536
https://blog.csdn.net/baijiwei/article/details/78760308
https://www.jdon.com/artichect/raft.html
http://ifeve.com/解读raft(二-选举和日志复制)/