3.0 综述
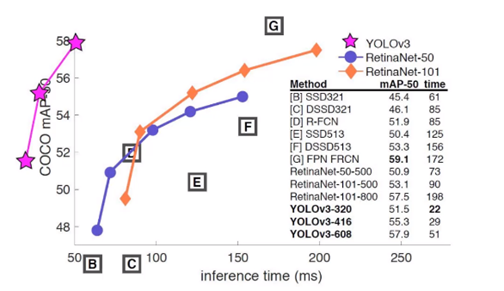
V3不像V2那样众多细节的改变,V3注重于整体网络核心架构升级。如下图,比较浮夸;x轴是单帧前向推理速度,y轴是主流网络在COCO数据集上mAP
值。下图浮夸之处在于:将V3曲线划到了第二象限!V3广泛用于实时目标检测、实时跟踪项目中。
创新点:
- 网络结构大改,使其更加是适应于小目标检测;
- 特征提取、融合更加充分细致,融入多持续特征图来预测不同规格物体
- 先验框更加丰富了,3中scale,每种3个规格,一共9种(借鉴Faster RCNN)
- Softmax改进,预测单目标-多标签任务(多分类改为多个二分类)
3.1 升级版Muti-Scale与特征融合
在V2中的2.7、2.8节讲述了特征的融合、和训练过程动态改变分辨率,一定程度上使得V2网络模型能够检测到小目标,V2中的最终特征图、中间特征图的堆叠过于生硬,反而导致一些信息会被淹没。
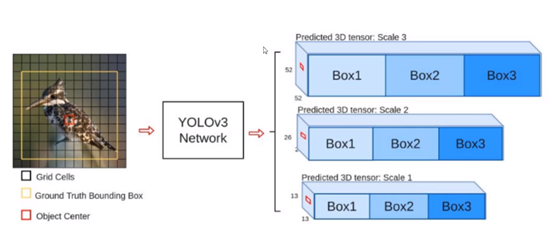
V3中,为了检测不同大小物体,设计了3个scale。如下图,图中三个特征图分别为:52×52、26×26、13×13,感受野依次变大,他们分别来自网络中靠前、中间、靠后的特征图,依次识别小目标、中等规格目标、大目标,而且是分开处理,不像V2中那样直接堆叠在一起。每种特征图都有3个Box,依次对应3中不同比例的先验框(显然52×52对应的目标小,候选框也小),这里的9种候选框是借鉴Faster R-CNN的。
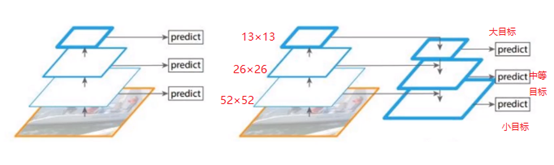
如下图,左图是对不同的特征图分别利用进行预测,右图(V3做法),对不同特征图融合后进行预测。例如:26×26的特征图融合13×13特征图的信息,(注:13×13可以通过上采样、插值得到26×26的特征图)。
3.2 残差链接
深度残差网络自2016年起广受欢迎,目标业界主流网络基本基于ResNet改进而来。V3也引入了ResNet的思想,堆叠了更多的层进行特征提取。
ResNet由来:当年的VGG网络堆叠了到了19层已经有不错效果,但是随着网络加深,过拟合风险也加大,计算量也变大,卷积层再加多就没有意义了。如下图,VGG-56效果还不如VGG-20。如下图,随着迭代次数加大,训练、测试的loss逐渐下降,VGG-19效果居然比VGG-56要好。
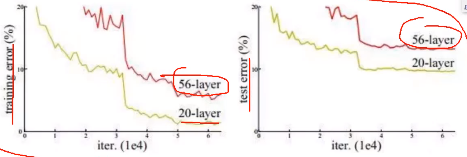
当时业界有人认为DL走到一个瓶颈期。后来何凯明大神发明了残差连接算法,有效解决了以上问题。如上图,VGG-56 相对于VGG-20多出了36层,这36层中,有的层可以为整体网络提升性能,有的则是降低性能;那怎么从这36层中剔除“害群之马”呢?如下图,ResNet大概是这样做的:例如从20层往下走有两条路,一是经过21、22层,二是直接“拷贝”过去,接着验证两种方式的loss,哪一条路的loss小就保留哪一条路。以上做法可以有效避免“网络加深导致过拟合”问题。

3.3 整体网络架构模型分析
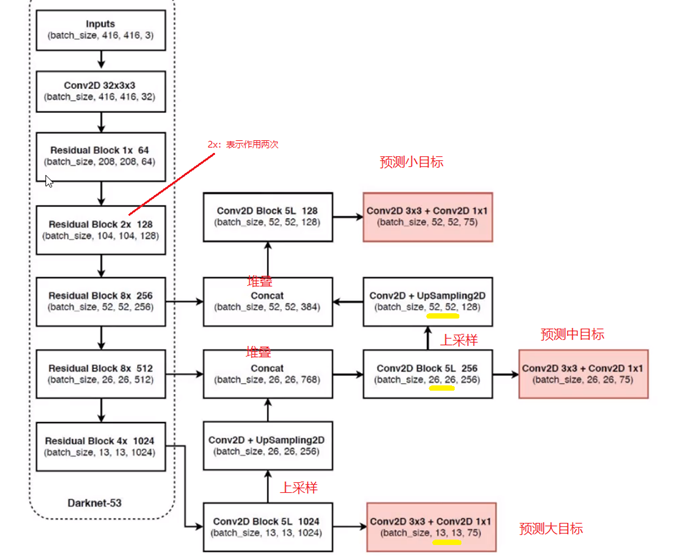
如下图,是V3的网络架构图,称为DarkNet-53(V2中称为DarkNet-19),其实和ResNet差不多。
- 没有池化(特征图会压缩,需要下采样的地方,用卷积代替,例如:将特征图缩小一半,可通过将卷积stride设为2来实现)。也没有全连接层(FC层参数多,训练慢,不易收敛),全部卷积。
- 3种scale,更多先验框,前面说过。
- 当下主流算法全部融入。
下面这样图就是DarkNet-53,有关于Scale方便的特征图融合,可以结合3.1节两张图看下,没啥好说。
3.4 先验框的改进
V1、2、3的网格分别为:7×7、13×13、(13×13、26×26、52×52),如下图,是对3个最终层特征图参数的解析。

V1中B=2,V2中B=5(KMeans得出),V3中B=9,这个9并非针对一张图中的一个cell。如下图,13*13感受野大,所以先验框大。V3中9个先验框宽高分别为:


实测图片(可以看到不同感受野得到先验框大小不同):

3.5 SoftMax多标签改进
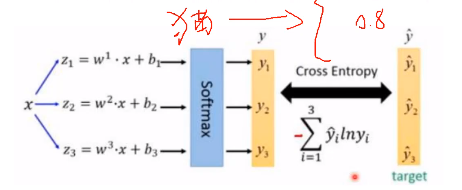
V2中SoftMax的作用是:预测一个目标例如是猫,后续计算交叉熵就只会计算是猫的概率,其他类别就不管了。
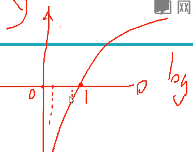
 交叉熵曲线(loss-概率曲线图):
交叉熵曲线(loss-概率曲线图):
例如:一只猫的label有:动物、波斯猫、猫科动物,哺乳动物等,V2的处理方式不能解决这个问题。V3版本中,使用多个logistic激活函数来预测一个物体的多标签概率,这样就能预测每个类别是与不是。例如:预测上述猫属于上述类别(动物、波斯猫、猫科动物,哺乳动物)为:0.9、0.8、0.5、0.55;接着,V3的做法是取一个概率阈值,例如“0.7”,认为大于0.7的都是该类别,于是输出为“1 1 0 0”。
reference: