Latent Dirichlet allocation
In statistics, latent Dirichlet allocation (LDA) is a generative model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar. For example, if observations are words collected into documents, it posits that each document is a mixture of a small number of topics and that each word's creation is attributable to one of the document's topics. LDA is an example of a topic model and was first presented as a graphical model for topic discovery by David Blei, Andrew Ng, and Michael Jordan in 2002.[1]
Contents[hide] |
[edit]Topics in LDA
In LDA, each document may be viewed as a mixture of various topics. This is similar to probabilistic latent semantic analysis (pLSA), except that in LDA the topic distribution is assumed to have a Dirichlet prior. In practice, this results in more reasonable mixtures of topics in a document. It has been noted, however, that the pLSA model is equivalent to the LDA model under a uniform Dirichlet prior distribution.[2]
For example, an LDA model might have topics that can be classified as CAT and DOG. However, the classification is arbitrary because the topic that encompasses these words cannot be named. Furthermore, a topic has probabilities of generating various words, such as milk, meow, and kitten, which can be classified and interpreted by the viewer as "CAT". Naturally, cat itself will have high probability given this topic. The DOG topic likewise has probabilities of generating each word: puppy, bark, and bone might have high probability. Words without special relevance, such as the (see function word), will have roughly even probability between classes (or can be placed into a separate category).
A document is given the topics. This is a standard bag of words model assumption, and makes the individual words exchangeable.
[edit]Model

With plate notation, the dependencies among the many variables can be captured concisely. The boxes are “plates” representing replicates. The outer plate represents documents, while the inner plate represents the repeated choice of topics and words within a document. M denotes the number of documents, N the number of words in a document. Thus:
- α is the parameter of the Dirichlet prior on the per-document topic distributions.
- β is the parameter of the Dirichlet prior on the per-topic word distribution.
- θi is the topic distribution for document i,
- φk is the word distribution for topic k,
- zij is the topic for the jth word in document i, and
- wij is the specific word.

The wij are the only observable variables, and the other variables are latent variables. Mostly, the basic LDA model will be extended to a smoothed version to gain better result. The plate notation is shown in the right, where K denotes the number of topics considered in the model and:
- ϕ is a K*V (V is the dimension of the vocabulary) Markov matrix each row of which denotes the word distribution of a topic.
The generative process behind is that documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words. LDA assumes the following generative process for each document i in a corpus D :
1. Choose  , where
, where 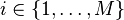
2. Choose  , where
, where 
3. For each of the words wij, where 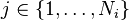
- (a) Choose a topic
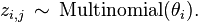
- (b) Choose a word
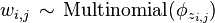 .
.
(Note that the Multinomial distribution here refers to the Multinomial with only one trial. It is formally equivalent to the categorical distribution.)
The lengths Ni are treated as independent of all the other data generating variables (q and z). The subscript is often dropped, as in the plate diagrams shown here.
[edit]Inference
Learning the various distributions (the set of topics, their associated word probabilities, the topic of each word, and the particular topic mixture of each document) is a problem of Bayesian inference. The original paper used a variational Bayes approximation of the posterior distribution[1]; alternative inference techniques use Gibbs sampling[3] and expectation propagation[4].
Following is the derivation of the equations for collapsed Gibbs sampling, which means φs and θs will be integrated out. For simplicity, in this derivation the documents are all assumed to have the same length N. The derivation is equally valid if the document lengths vary.
According to the model, the total probability of the model is:

where the bold-font variables denote the vector version of the variables. First of all,  and
and 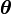 need to be integrated out.
need to be integrated out.
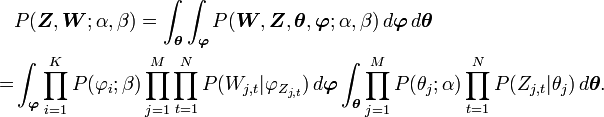
Note that all the θs are independent to each other and the same to all the φs. So we can treat each θ and each φ separately. We now focus only on the θ part.

We can further focus on only one θ as the following:
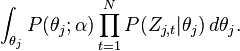
Actually, it is the hidden part of the model for the jth document. Now we replace the probabilities in the above equation by the true distribution expression to write out the explicit equation.

Let 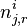 be the number of word tokens in the jth document with the same word symbol (the rth word in the vocabulary) assigned to the ith topic. So, is three dimensional. If any of the three dimensions is not limited to a specific value, we use a parenthesized point
be the number of word tokens in the jth document with the same word symbol (the rth word in the vocabulary) assigned to the ith topic. So, is three dimensional. If any of the three dimensions is not limited to a specific value, we use a parenthesized point 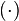 to denote. For example,
to denote. For example, 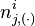 denotes the number of word tokens in the jthdocument assigned to the ith topic. Thus, the right most part of the above equation can be rewritten as:
denotes the number of word tokens in the jthdocument assigned to the ith topic. Thus, the right most part of the above equation can be rewritten as:
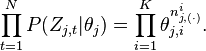
So the θj integration formula can be changed to:

Clearly, the equation inside the integration has the same form as the Dirichlet distribution. According to the Dirichlet distribution,

Thus,

Now we turn our attentions to the part. Actually, the derivation of the part is very similar to the part. Here we only list the steps of the derivation:

For clarity, here we write down the final equation with both 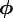 and integrated out:
and integrated out:

The goal of Gibbs Sampling here is to approximate the distribution of  . Since
. Since  is invariable for any of Z, Gibbs Sampling equations can be derived from
is invariable for any of Z, Gibbs Sampling equations can be derived from  directly. The key point is to derive the following conditional probability:
directly. The key point is to derive the following conditional probability:
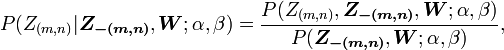
where Z(m,n) denotes the Z hidden variable of the nth word token in the mth document. And further we assume that the word symbol of it is the vth word in the vocabulary.  denotes all the Zs but Z(m,n). Note that Gibbs Sampling needs only to sample a value for Z(m,n), according to the above probability, we do not need the exact value of
denotes all the Zs but Z(m,n). Note that Gibbs Sampling needs only to sample a value for Z(m,n), according to the above probability, we do not need the exact value of but the ratios among the probabilities that Z(m,n) can take value. So, the above equation can be simplified as:
but the ratios among the probabilities that Z(m,n) can take value. So, the above equation can be simplified as:

Finally, let  be the same meaning as but with the Z(m,n) excluded. The above equation can be further simplified by treating terms not dependent on k as constants:
be the same meaning as but with the Z(m,n) excluded. The above equation can be further simplified by treating terms not dependent on k as constants:

[edit]Applications, extensions and similar techniques
Topic modeling is a classic problem in information retrieval. Related models and techniques are, among others, latent semantic indexing, independent component analysis,probabilistic latent semantic indexing, non-negative matrix factorization, Gamma-Poisson.
The LDA model is highly modular and can therefore be easily extended, the main field of interest being the modeling of relations between topics. This is achieved e.g. by using another distribution on the simplex instead of the Dirichlet. The Correlated Topic Model[5] follows this approach, inducing a correlation structure between topics by using the logistic normal distribution instead of the Dirichlet. Another extension is the hierarchical LDA (hLDA)[6], where topics are joined together in a hierarchy by using the nestedChinese restaurant process.
As noted earlier, PLSA is similar to LDA. The LDA model is essentially the Bayesian version of PLSA model. Bayesian formulation tends to perform better on small datasets because Bayesian methods can avoid overfitting the data. In a very large dataset, the results are probably the same. One difference is that PLSA uses a variable d to represent a document in the training set. So in PLSA, when presented with a document the model hasn't seen before, we fix 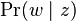 --the probability of words under topics—to be that learned from the training set and use the same EM algorithm to infer
--the probability of words under topics—to be that learned from the training set and use the same EM algorithm to infer 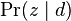 --the topic distribution under d. Blei argues that this step is cheating because you are essentially refitting the model to the new data.
--the topic distribution under d. Blei argues that this step is cheating because you are essentially refitting the model to the new data.
[edit]See also
[edit]Notes
- ^ a b Blei, David M.; Ng, Andrew Y.; Jordan, Michael I (January 2003). Lafferty, John. ed. "Latent Dirichlet allocation". Journal of Machine Learning Research 3 (4–5): pp. 993–1022.doi:10.1162/jmlr.2003.3.4-5.993.
- ^ Girolami, Mark; Kaban, A. (2003). "On an Equivalence between PLSI and LDA". Proceedings of SIGIR 2003. New York: Association for Computing Machinery. ISBN 1-58113-646-3.
- ^ Griffiths, Thomas L.; Steyvers, Mark (April 6 2004). "Finding scientific topics". Proceedings of the National Academy of Sciences 101 (Suppl. 1): 5228–5235. doi:10.1073/pnas.0307752101.PMC 387300. PMID 14872004.
- ^ Minka, Thomas; Lafferty, John (2002). "Expectation-propagation for the generative aspect model". Proceedings of the 18th Conference on Uncertainty in Artificial Intelligence. San Francisco, CA: Morgan Kaufmann. ISBN 1-55860-897-4.
- ^ Blei, David M.; Lafferty, John D. (2006). "Correlated topic models". Advances in Neural Information Processing Systems 18.
- ^ Blei, David M.; Jordan, Michael I.; Griffiths, Thomas L.; Tenenbaum; Joshua B (2004). "Hierarchical Topic Models and the Nested Chinese Restaurant Process". Advances in Neural Information Processing Systems 16: Proceedings of the 2003 Conference. MIT Press. ISBN 0-262-20152-6.
[edit]External links
- D. Mimno's LDA Bibliography An exhaustive list of LDA-related resources (incl. papers and some implementations)
- Gensim Python+NumPy implementation of LDA for input larger than the available RAM.
- topicmodels and lda are two R packages for LDA analysis.
- LDA and Topic Modelling Video Lecture by David Blei
- “Text Mining with R" including LDA methods, video of Rob Zinkov's presentation to the October 2011 meeting of the Los Angeles R users group
- MALLET Open source Java-based package from the University of Massachusetts-Amherst for topic modeling with LDA, also has an independently developed GUI, the Topic Modeling Tool
- LDA in Mahout implementation of LDA using MapReduce on the Hadoop platform
- The LDA Buffet is Now Open; or, Latent Dirichlet Allocation for English Majors A non-technical introduction to LDA by Matthew Jocker
转自:http://en.wikipedia.org/wiki/Latent_Dirichlet_allocation