在2017年5月芝加哥举办的世界顶级数据库会议SIGMOD/PODS上,作为全球最大的公有云服务提供商,Amazon首次系统的总结了新一代云端关系数据库Aurora的设计实现。Aurora是Amazon在2014 AWS re:Invent大会上推出的一款全新关系数据库,提供商业级的服务可用性和数据可靠性,相比MySQL有5倍的性能提升,并基于RDS 提供自动化运维和管理;

经过2年时间发展,Aurora已经成长为AWS 客户增长最快的云服务之一,包括全球知名的在线游戏网站Expedia、社交游戏公司
Zynga都在使用Aurora。Aurora的推出一时引起了国内数据库研究人员的热烈讨论,大家关注的一个焦点就是Aurora是否是基于MySQL推出的一个新的存储引擎?下面我们就根据会议发布的论文,一起走进Aurora。
为什么要有Aurora?
在理解Aurora设计的初衷之前,我们首先来了解一下AWS RDS MySQL的高可用部署架构设计。与我们之前的猜测是一致的, AWS RDS是基于EC2、EBS这样的云基础设施构建的,数据库实例部署在EC2内,数据盘由一组通过镜像实现的两副本EBS提供。
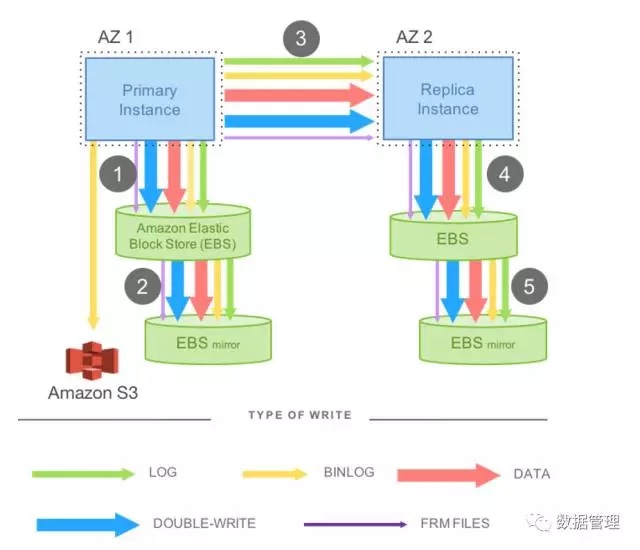
为了实现跨数据中心的高可用,Primary和Replica分别部署在两个可用域内,数据同步采用类似DRBD的方式在操作系统内核通过块设备级别的同步复制实现,所以AWS RDS的Replica平时是不能被读取的,只能用于跨可用域的故障恢复。Replica与Primary是完全对称的,通过内核复制到replica的数据同样存放在一组镜像实现的两副本EBS中。从图中可以看到,这样的一个部署架构,数据库发起的一次写IO需要同步复制5次,其中3次还是串行的,网络延迟对数据库的性能影响非常严重。
MySQL的InnoDB存储引擎遵从WAL协议,所有对数据页的更新都必须首先记录事务日志。此外,MySQL在事务提交时,还会生 成binlog;为了保证被修改的数据页在刷新到硬盘的过程中保证原子性,Innodb设计了double-write的机制,每个数据页会在硬盘上写两遍。此外,MySQL还有元数据文件(frm)。在AWS RDS的高可用架构中,所有的这些日志文件、数据文件都要经过网络的传输5次,对网络带宽也是巨大的考验。
这样的一个架构由于不涉及具体数据库内核的改动,满足了AWS发展初期可以快速支持多种类型的关系数据库的需求,但是显然随着规模的增长,这样的架构的缺陷也越来越明显。当我们还在考虑如何优化我们的网络性能和IO路径时,AWS的注意力已经转移到如何来减少数据在网络上的传输,这就有了后来Aurora的架构。
Aurora的系统架构
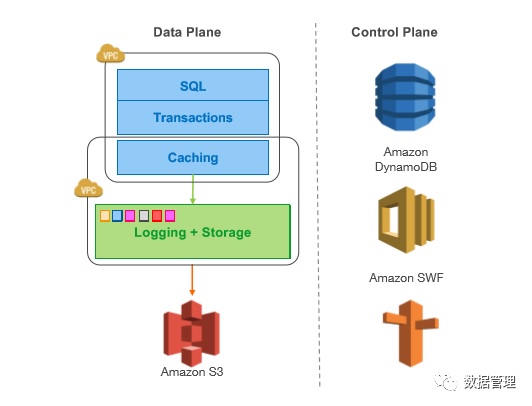
Aurora与传统关系数据库相比,最大的一个架构上的创新就是将数据和日志的管理交由底层的存储系统来完成,数据库实例只负责向存储系统中写入redo log。由于底层存储节点挂载的是本地硬盘,日志的持久化和数据页的更新并不需要跨网络完成,所以只有redo log需要通过网络传输。由于MySQL的redo log中包含了对某个数据页的某行记录的更新,通过redo log以及先前的数据页可以构造出更新后的完整页面,所以Aurora选择通过redo log建立起数据库实例和底层存储系统之间的关系。
在Aurora中,数据库实例负责处理SQL查询,事务管理,缓冲池管理,锁管理,权限管理,undo管理,对用户而言,Aurora与MySQL 5.6完全兼容。底层的存储系统负责redo log持久化,数据页的更新和垃圾日志记录的回收,同时底层存储系统会对数据进行定期备份,上传到S3中。底层存储系统的元数据存储在Amazon DynamoDB中,基于Amazon SWF提供的工作流实现对Aurora 的自动化管理。
存储系统的设计
Amazon为Aurora实现了一个高可用、高可靠、可扩展、多租户共享的存储系统。
多副本
为了实现数据的可靠性,Aurora在多个可用域内部署了多个数据副本,基于Quorum原则确保多个副本数据的最终一致性。
Quorum原则要求V个数据副本,一次读操作必须要读取Vr个数据副本,一次写操作必须要同时写入Vw个数据副本,Vw和Vr需要满足:Vw + Vr > V,且 Vw > V/2。Quorum原则可以确保一份数据不能被同时读写,同时也确保了两个写操作必须串行化,后一个写操作可以基于前一个的结果进行更新。
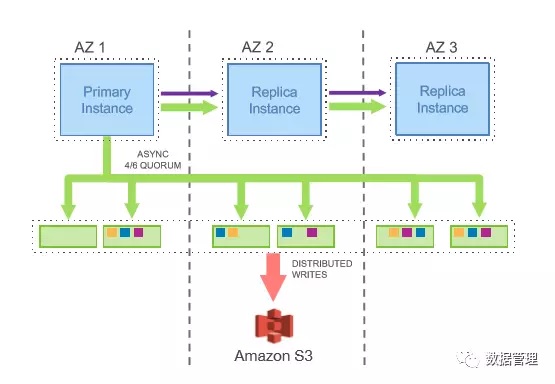
一般最小的Quorum要求最少3个数据副本,Vr = 2 ,Vw =2,在云环境中,就是3个可用域,每个可用域一个数据副本,一个可用域不可用,不影响数据的读写。但是在真实的场景中,一个可用域不可用的同时,另外一个可用域很有可能也出现故障,为了解决上述问题,Aurora采用了6副本数据,每个可用域2个数据副本,一次写操作需要4个数据副本,一次读操作需要3个数据副本。这 样的设计可以实现:
1. 在一个可用域内两个数据副本同时失效,同时另外一个可用域内的一个数据副本失效,不影响整个系统的读;
2. 任意两个数据副本同时失效,不影响系统的写;
分段存储系统设计
任何一个高可用系统设计的前提假设都是在一段时间内,连续两次发生故障的概率足够的低。对于Aurora基于Quorum的多副本设计而言,如果一个AZ的副本失效,在修复过程中,同时再有一个副本失效,则整个系统将不可写;如果在AZ+1的副本失效的同时,又有一个副本再失效,则系统将不可读。我们没有办法去阻止连续故障的发生,但是我们可以通过缩短前一次故障的修复时间,从而降低连续两次故障出现的概率,这就是分段存储设计的思想来源。
Aurora将一个数据库实例的数据卷划分为10G固定大小的存储单元,这样可以确保每个单元数据可以快速的恢复。每个存储单元有6个副本,每个可用域内2个副本,6个副本组成了一个PG(Protection Groups)。物理上,由一组挂载本地SSD的EC2云主机充当存储节点,每个存储节点上分布了很多存储单元。一组PG构成了一个Aurora实例的数据卷,通过分配更多的PG,可以线性扩展数据卷的容量,最大支持64TB。

Segment是存储系统故障恢复的最小单元,之所以选择10G大小,如果太小,可能造成元数据过于庞大,如果太大,又可能造成单个Segment的修复时间过长,经过Aurora测试,10G大小的Segment数据恢复时间在10Gbps的网络传输速度下,只需要10秒时间,这样就确保了存储系统可以在较短的时间内完成故障修复。Segment的元数据由一个DynamoDB来负责存储。
基于Segment和Quorum的设计,Aurora可以通过人工标记一些Segment下线,来完成数据迁移,对于热点均衡、存储节点操作系统升级更新都非常有帮助。
以日志核心的数据库
事务日志的写入
在MySQL数据库InnoDB存储引擎中,所有数据记录都存储在16K大小的数据页中,所有对行记录的修改操作,都首先必须对数据页进行加锁,然后在内存中完成对数据页行记录修改操作,同时生成redo log和undo log,在事务提交时,确保修改操作对应的redo log持久化到硬盘中,最终被更新的数据页通过异步方式刷新到硬盘中。redo log确保了数据页更新的持久化,每个redo logrecord都有一个唯一标识,LSN(log sequence number),标识该记录在redo log文件中的相对位置。为了确保一个更新操作对多个数据页,或者一个数据页内部多条记录的修改原子性,一个事务会被切分成多个Mini-transaction(MTR),MTR是MySQL内部最小执行单元,在Aurora中,MTR的最后一个redo log record对应的LSN,称为CPL(Consistency Point LSN),是redo log中一致点。
在每个MTR提交时,会将MTR生成的redo log 刷新到公共的log buffer中,在MySQL内部,一般log buffer空间满,或者wait 超时,再或者事务提交时,log buffer中的redo log会被刷新到硬盘中。在Aurora中,每个PG都保存了一部分数据页,每个redo logrecord在被刷新到硬盘之前,会按照redo log record更新的数据页所在的PG,划分成多个batch,然后将batch发送到PG涉及的6 个存储节点,只有等到6个节点中的4个的ACK,这个batch内的redo log record才算写入成功。最新写入成功的MTR的最后一个记录对应的LSN,我们成为VDL( Volume Durable LSN ),这个点之前的MTR对数据页的修改,都相当于已经持久化到存储系统中。
存储节点对事务日志的处理
每个存储节点在接收到redo log record batch之后,首先会将其加入到一个内存队列中,然后将redo log record持久化到硬盘后,返回ACK 给写入实例(Primary)。接下来,由于每个存储节点可能保存的batch不完整(由于Quorum 4/6机制),所以需要通过与同一个PG下的其他存储节点进行询问,索要缺失的batch。
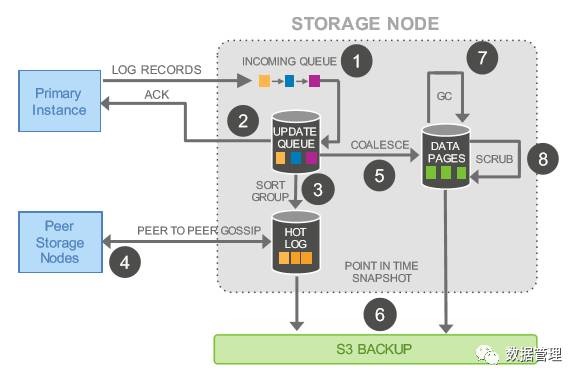
Aurora中存储节点对数据的管理采用了log-structured storage方式,每个PG的redo log record首先按照page进行归类,同一个page的redo log record在写入时,直接append在该页面之后,页面中的已有记录会有一个连接指针,指向最新的记录版本。
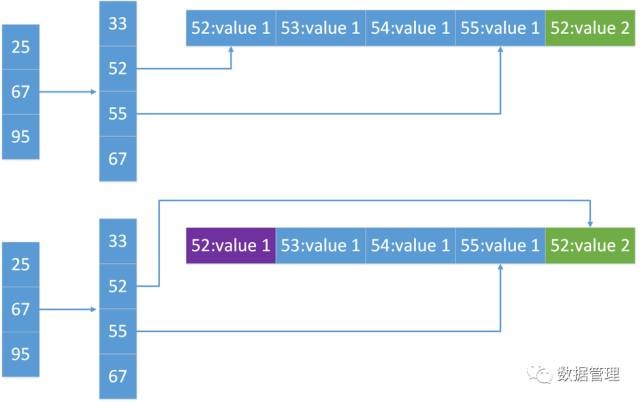
除此之外,每个PG内的每个segment上的redo log record都包含一个指针,指向他的前一个log record,通过这个指针,我们很容易判断每个Segment上的log record完整性,如果缺失,则可已通过与其他的存储节点进行询问,补齐缺失redo log record。
数据页的合并和旧版本记录的回收
类似HBase、Cassandra采用LSM Tree的NoSQL系统,Aurora也需要有一个垃圾回收和数据页合并的过程。在MySQL中,脏页的刷新是通过Check point的机制来完成的,redo log的空间是有限的,必须要将redo log涉及的数据页持久化到硬盘中,redo log 空间才能释放,新的redo log 才能写入,所以MySQL的脏页刷新与客户端的事务提交是密切相关的,如果脏页刷新过慢,可能导致系统必须等待脏页刷新,事务无法提交。另外,Check point机制也决定了脏页是否刷新是根据整个redo log大小来决定的,即使一个页面只是偶尔一次更新,整个数据页在check point推进过程中,都必须重新写入,同时为了确保一个数据页的完整性, MySQL还有double write机制,页面被写两次,代价非常昂贵,显然是不合理的。
Aurora的设计更加巧妙,因为数据是有热点的,不同的数据页的更新频率是不一样的,根据每个Page待更新的redo log record数量,来决定page是否进行合并。
纵观Aurora的设计,一个核心的设计原则就是将数据页看成是日志的一个缓存,通过牺牲一定的读,换取了很好的写性能,这是所有基于log-structured system 共性。
对数据库的操作
写操作
在Aurora中,同时会存在很多写事务,这些事务会产生大量的redo log record,因为所有的事务在提交时,都必须确保该事务产生的redo log已经写入到底层至少4个存储节点中,考虑到网络和存储节点的IO性能,Aurora中会对写事务进行限制,如果当前分配的LSN大于VDL加上LAL(LSN Allocation limit),则不再分配新的LSN。
提交事务
在MySQL中,虽然在事务执行过程中,各个事务是并发执行的,但是在提交时,都是串行的,虽然MySQL 5.6推出了Group Commit,可以批量提交,但是在前一个group提交过程中,其他线程也不得不sleep等待唤醒,这样无疑造成了资源浪费。
在Aurora中,事务的提交完全是异步的,每个事务执行完成以后,提交的过程只是将该事务加入到一个内部维护的列表中,然后该线程就被释放了。当VDL大于该列表中等待提交事务commit对应的lsn时,则由一个线程,向各个客户端发送事务提交确认。
读操作
在MySQL中,所有的读请求都是首先读buffer cache的,只有当buffer cache未命中的情况下,才会读取硬盘。Buffer cache的空间是有限的,在MySQL中,通过LRU的机制,会将一些长时间没有被访问的数据页占用的buffer空间释放。如果这些页面中包含脏页,则必须要等到脏页刷新到硬盘以后才能释放。这样就确保了下次读取该数据,一定能够读取到最新的版本。
在Aurora中,并不存在脏页刷新的过程,所有数据页的合并都是由底层存储节点来完成的。所以与MySQL实例脏页刷新向上看不同,Aurora需要向下看,通过将Page LSN大于VDL的数据页释放,可以确保,所有Buffer中Page涉及的更新都已经持久化到硬盘中,同时在cache未命中的情况下,可以读取到截止到当前VDL的最新版本的数据页。
所以在Aurora中,Buffer Cache更像是一个纯粹的Cache。
在Aurora日常读取中,并不需要达到3/6的Quorum,因为有VDL的存在,我们可以根据读请求发起时的VDL建立一个readpoint,找到包含小于VDL的所有完整log record的存储节点,直接进行读取。通过同一个PG内部的Segment之间的相互询问,可以建立一个PG的最小的read point,该read point以下的log record实际上才可以被回收合并。
只读节点
在Aurora中,最多可以为一个writer实例创建15个只读实例,这15个只读实例挂载的是相同的存储卷,只读实例不会额外增加存储的开销。为了减少延迟,Writer实例会将写入到存储系统的redo log日志同样发送给只读实例,只读实例接收到redo log日志后,如果要更新的数据页命中了buffer cache,直接在buffer cache中进行更新,但是需要注意的是,如果是同一个mini-transaction的redo log record,必须确保mini-transaction的原子性。如果buffer cache没有命中,则该记录被丢弃。另外,如果被执行的log record的lsn大于当前的VDL,也不会被执行,直接丢弃。
这样的设计确保Aurora只读实例相较于Writer实例延迟不超过20ms。
故障恢复
MySQL基于Check point的机制,周期性的建立redo log与数据页的一致点。一旦数据库重启,从记录的Check point开始,根据redo log,对相应的数据页进行更新,对于已经提交的事务则确保事务更新持久化到硬盘的数据页中,对于未提交事务,利用数据页对应的roll pointer指针找到对应的undo log,进行回滚。MySQL 一般5分钟一个check point,在故障恢复过程中,由一个线程负责redo log的回放,整个过程数据库实例完全是停服的。
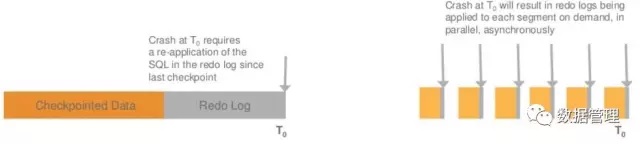
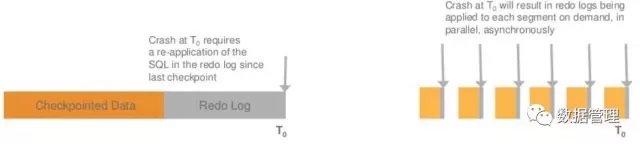
与MySQL 相同的是Aurora 在故障恢复过程时,首先也必须要找到一个一致性点,但是与MySQL不同的时,这个一致不要求所有的数据页是一致的,Aurora只要求找到VDL,确保日志的一致性。
基于read quorum机制,Aurora可以确保对于每一个PG,读到满足writer quorum的redo log record,从而建立VDL。对于每个存储节点,大于VDL的redo log记录将被删除。另外,虽然论文中并没有提,但是由于Aurora的Cache是独立于数据库进程的,所以当仅是数据库实例重启时,Cache内Page LSN大于VDL的数据页同样也需要被清理掉,因为这部分数据页对应的redo log并没有持久化到存储系统中。
建立VDL后,数据库即可以开始进行正常的读写访问。对于没有被提交的事务,由于undo写入的同时也会写redo,并且存在在同一个MTR中,所以undo也是完整的,根据undo可以完成对事务的回滚。但是与MySQL不同的是未提交事务的回滚是后台异步在存储节点完成的。同时,Aurora的redo log的更新是根据page待修改记录的多少来按需进行合并的,并且由于底层存储系统redo log和数据页分散在多个存储节点的segment上,所以可以并行进行数据页的合并。
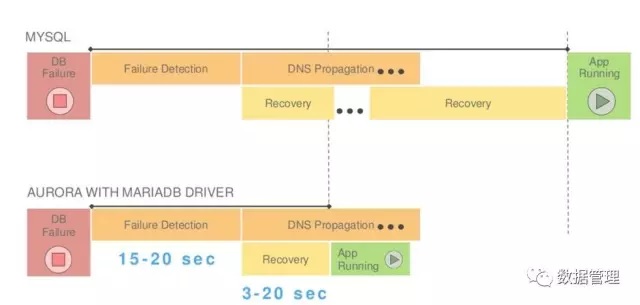
经过AWS 官方的测试,Aurora在10W 写QPS的压力下,故障恢复只需要10秒。另外值得一提的是,与MySQL Buffer Cache是进程内分配的内存空间不同,Aurora的Buffer Cache是独立于数据库进程的,这样做的一个好处就是数据库宕机以后,不会丢失热点,当然这也仅限于数据库实例宕机,如果是系统宕机,就没用了。
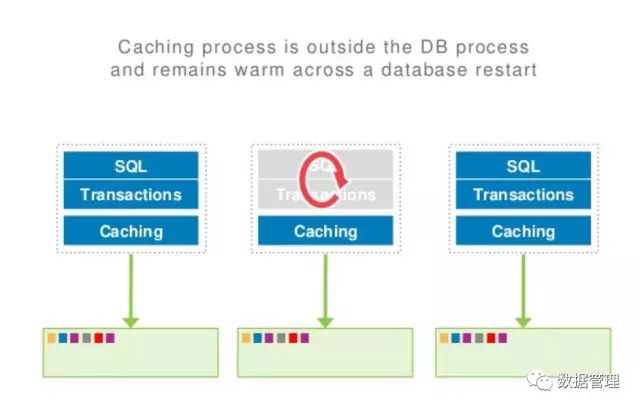
性 能
测试对象为Aurora,MySQL 5.6,MySQL5.7,分别在5种规格下(最大规格为32 vcpus,244G内存,最小的规格为2 vcpu,15G 内存,每种规格为前一个规格的一半vcpu和内存)的sysbench 纯读和纯写的压测。测试数据量为1G,所以是全内存的测试。
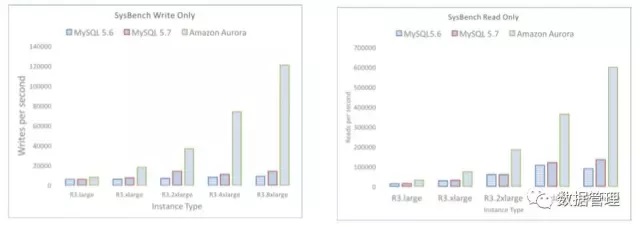
性能对比还是很明显的,得益于大幅减少的跨网络IO以及基于log-structured storage的数据结构,Aurora在r3.8xlarge规格下写可以达到每秒12W。由于Aurora可以创建多个只读实例,所以Aurora在r3.8xlarge规格下读可以达到60W(文章中并没有提及是否 使用了Aurora,但是在全内存场景下,笔者猜测,应该是基于多个replica达到的)
更多高级特性
在线修改表结构
Aurora的Online DDL相较于MySQL在实现上也非常有特色,Aurora目前仅支持在线加列(列允许为空),MySQL 5.6开始,加列操作也支持在线,但是体验较差,我们首先来看一下MySQL 5.6的在线加列过程:
MySQL 5.6 的在线加列分为3个过程:
Prepare: 持有MDL(MetaDataLock)排它锁,创建新的frm文件,更新内存数据字典,生成临时idb文件(记录增量),释放排它锁;
Execute:逐行遍历每一条记录,按照新的表结构构造记录,所有的更新操作都被记录在idb文件中;
Commit: 重新持有排它锁,将临时idb文件中的更新回放到表中,如果更新频率非常高,这个时间可能会比较长,最后临时文件被删除,rename新表。
这样一个流程实际让我们想到了利用Percona的Xtrabackup对数据库在线备份和恢复的过程,允许拷贝期间数据的短暂不一致,然后利用拷贝数据期间的row_log日志最终确保所有数据的一致性。
这样的设计满足了在线修改表结构的需求,但是由于存在全表拷贝,耗时往往非常长,同时最后阶段的加锁时间也不确定,在DBA 使用过程中,往往提心吊胆。
Aurora的设计则显得更为巧妙,很容易让人联想到LVM的Copy-on-write在线snapshot设计,修改过程仅仅只是修改原数据,并不涉及具体的数据拷贝,数据的拷贝是在该数据被修改时才完成的。

在Aurora中执行一条在线加列的DDL操作非常快,这是因为处理该请求系统只是在一个Schema Version Table的系统表中增加一行记录。接下来的DML,Aurora采用了modify-on-write的策略,以Page为单位,如果一个page的LSN大于加列DDL的LSN,则说明,该page已经被修改了schema,所以在DML发生前,就需要将该数据页按照新的schema格式进行存储。对于读操作,如果这个数据页还没被修改过,则直接在内存里面加一个空列进行返回给客户端。
由于Aurora的Online DDL只是增加一条数据库记录,所以速度相比MySQL快了很多个数量级。
地理位置空间索引
Aurora 与MySQL 5.6一致,支持空间数据类型(Point、POLYGON...)和空间关系函数(ST_Contains、ST_Distance...), MySQL 5.7 InnoDB也开始支持空间地理索引,对大数据集下的查询性能有很大的提升。Aurora 也支持空间地理索引,但是与MySQL 5.7 R Tree的实现方式不同,他是通过空间填充曲线对多维数据进行降维,基于B Tree实现的,这个与MongoDB更为类似。
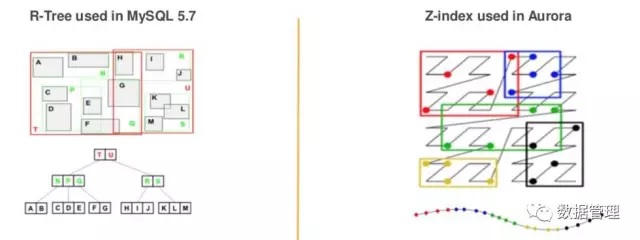
MySQL 5.7的Spatial Index实际是根据最小边界矩形来构建的R Tree。树顶端的两个节点代表的分别是最外层的两个矩形,每一个子树就是该矩形内的所有的节点。然后再根据最小边界矩形规则,构建子节点。当我们要查询某个范围内的所有节点时,可以通过这个范围跟各个矩形是否有重叠来确认查询范围,从最顶端的两个节点代表的矩形开始查找。如果有重叠,就需要查询该子树内的节点。基于R-tree实现的空间地理索引的缺点在于构建成本比较高昂。
Aurora的实现则是将多维数据首先利用一定的算法(时间空间曲线Z-index)进行降维,转换成字符串,然后利用B-Tree方式进行存储。
在线Point-in-time Restore
MySQL 企业版有一个对DBA很有用的功能就是Flash back,可以实现将数据库在线回滚到指定的时间点,对于误操作或者新上线BUG导致的数据修复非常有用,原理上他是基于Row格式的Binlog(会保存修改的前项和后项)进行逆向执行到指定位置实现的。
Aurora提供了两种针对上述场景的修复功能,在线PITR(Point-in-time restore)和离线PITR,前者是在原实例的基础上直接进行数据回滚,恢复期间数据库是可用的,后者是通过备份恢复出一个新的实例,恢复期间新的实例是不可用的。
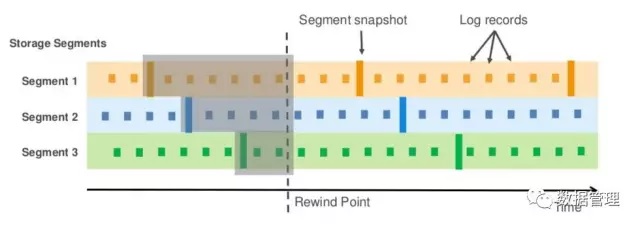
与MySQL 基于binlog的逆向执行不同,Aurora是基于redo log record来实现的。Aurora底层每个存储节点都会定期对存储节点上所有segment进行快照,与LVM类似,只备份元数据,如果某个segment中的某个block数据被重新写,则需要首先将数据拷贝到指定的区域(purchased rewind storage),然后更新该block。
当我们要进行数据恢复时,首先我们找到要恢复的时间点以前最近的所有存储节点上segement快照,然后根据该快照对应的lsn之后的redo log record就可以完成数据的修复。(rewind window 内的redo log record是不会被清理的)
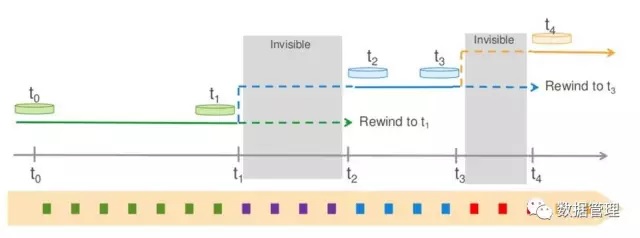
在很多场景下,我们一次是无法精确定位到我们需要的时间点的,这时候,Aurora会根据redo log recod的可见性来快速实现时间点的前进和后退。如图所示,当我们从t2时间点恢复到t1时间点时,我们只需要将t1-t2之间的redo log record不可见即可。当我们希望从t4回滚到t3时,我们只需要将t3-t4和t1-t2之间的redo log record设置不可见即可,当然这必须满足MTR的原子性要求。
总 结
做架构设计的人有一个共识,没有最完美的架构设计,只有最适合的架构设计。Aurora 应该说就是这种理念最完美的诠释。在计算与存储分离的云基础设施之上,通过仅传输redo log,大幅减少跨网络的IO数据传输,将产生大量IO的数据页合并和持久化交由本地存储来解决,大幅减缓了网络延迟对数据库性能的影响。
另外,基于log-structured storage的数据页合并,相比Check point,可以更加高效的合并针对同一个数据页的更新,这些无疑提高了数据库的写入性能。多个replica共享同一个storage volume,多副本并发读取,大幅提高了数据库的读性能。总体来说,
Aurora 对于云端数据库的架构设计具有划时代的意义,充分利用了云基础设施的架构特性,将数据库性能做到极致。
参考文档
1. Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases SIGMOD’17, May 14 – 19, 2017, Chicago, IL, USA.
2. AWS 2016 re:Invent Amazon Aurora Deep Dive
3. AWS Aurora blog: https://aws.amazon.com/tw/blogs/database/category/aurora/?nc1=h_ls
4. Percona live 2016 Amazon Aurora Deep Dive
5. https://dev.mysql.com/
转至https://www.cnblogs.com/163yun/p/9020693.html https://www.cnblogs.com/163yun/p/9020736.html