本次看的是第3章, 数据存储与检索
概览
存储引擎分为2类, OLTP(事务处理)和OLAP(在线分析).
一般用的数据库Oracle, MySQL, SQLServer等属于OLTP, 一般说的Data Warehouse(数据仓库)是OLAP, 一般用来生成报表.
对于小数据来说, 普通的数据库可同时满足事务处理和在线分析的要求, 但是对于大公司, 多个业务海量数据, 就需要抽取-转换-加载(ETL) 和数据库仓库来做专门的分析.
OLTP又分2类, 日志结构学派和就地更新学派.
- 日志结构学派, 更新, 插入, 删除等动作都是Append到文件结尾, 类似添加日志的方式. 关于日志, 参考文章 https://github.com/oldratlee/translations/blob/master/log-what-every-software-engineer-should-know-about-real-time-datas-unifying/README.md.
- 就地更新学派, 更新是覆盖原磁盘位置, 典型代表是B树.
日志结构学派
日志类型, 写入数据时直接附加到结尾, 性能很高; 读取时就比较麻烦, 所以要创建索引来提高读取速度, 同时写入时也要更新索引, 就降低了写入的速度. 以稍微降低写入速度来提高读取速度的trade off.
哈希索引
保留一个内存中的哈希映射,其中每个键都映射到一个数据文件中的字节偏移量,指明了可以找到对应值的位置
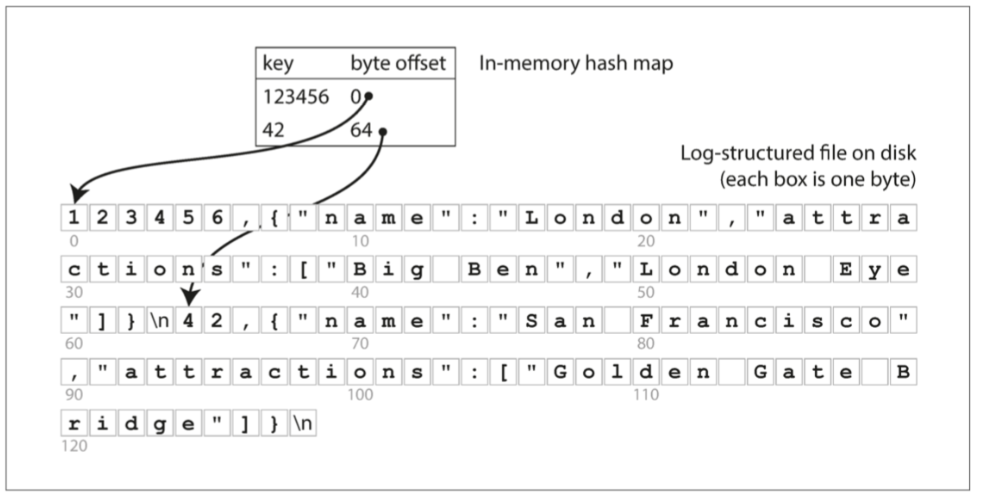
由于是一直新增数据, 有一个问题就是如何避免磁盘用完. 一种好的解决方案是, 将日志分为特定大小的段,当日志增长到特定尺寸时关闭当前段文件,并开始写入一个新的段文件。然后,我们就可以对这些段进行压缩(compaction), 只保留最新的值. 由于压缩后的段可能比较小, 所以可以执行段合并的动作.

SSTables和LSM树
将哈希索引进行优化, 增加了一个要求键值对的序列按键排序. 这块没太看懂, 找了一篇博文参考, SSTables, LSM Tree 与 B-Tree.
就地更新学派
B树
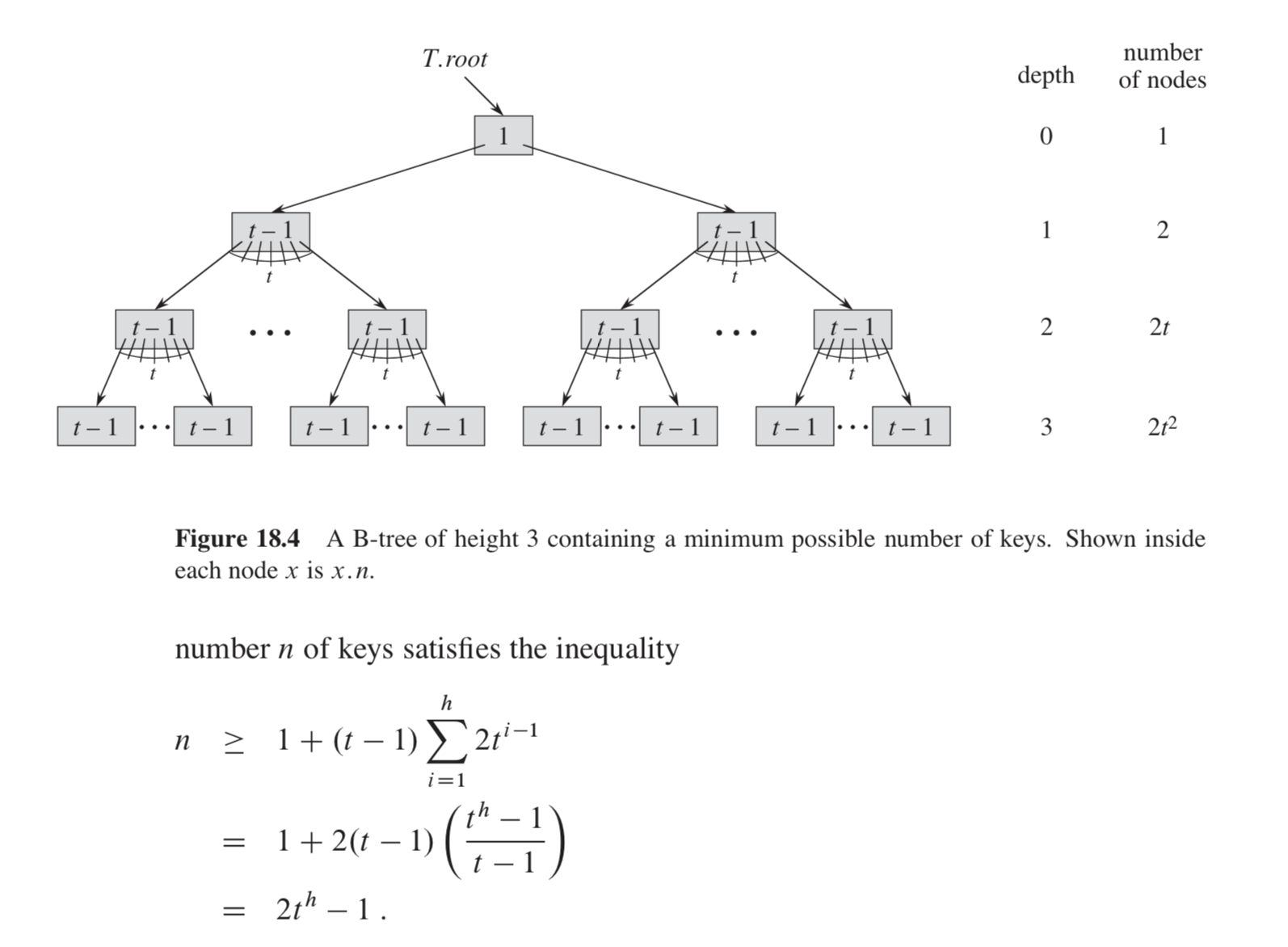
B树是一颗平衡二叉树, 只不过为了减少深度, 将单个节点包含了多个key, 很适合磁盘结构. 因为磁盘读取比内存慢很多, 一次读取多个key可以大大减少磁盘读取次数, 提高读取速度. 一般来说4层结构就足够保存大量的数据, 如果单节点包含500个key, 那么4层至少包含(2*500^4 - 1 = 1.25 * 10^11) 个key.
B树 vs LSM树
- 通常B树读取速度更快, LSM写入速度更快.
- LSM树的查询有时会特别慢, 不像B树的查询相对更加可预测.
- LSM树的压缩没配置好, 且写入吞吐量很大的情况下, 可能会导致压缩跟不上写入, 从而导致空间占用越来越大, 磁盘剩余空间越来越小, 磁盘用完. 因此要做好监控.
- B树的一个优点是每个键只存在于索引中的一个位置,而日志结构化的存储引擎可能在不同的段中有相同键的多个副本。这个方面使得B树在想要提供强大的事务语义的数据库中很有吸引力:在许多关系数据库中,事务隔离是通过在键范围上使用锁来实现的,在B树索引中,这些锁可以直接连接到树.
- 数据库一般都是B树, 或者B+树, 而新的存储结构, 用日志结构的越来越多, 如Kafka.