原文链接:http://blog.csdn.net/ikerpeng/article/details/19235391
用到论文,直接看翻译。
文章:Robust object tracking with on-line multiple instance learning Boris Babenko, Student Member, IEEE, Ming-Hsuan Yang, Senior Member, IEEE and Serge Belongie, Member, IEEE ;PAMI ,2011.
文章开头就说的明了:本文的tracking只给定了第一帧目标的位置,没有其余的信息了(上一篇论文是拿了前10帧的图片来训练的)。本文解决的问题同样是on-line tracking出现的漂移的问题(Slight inaccuracies in the tracker can therefore lead to incorrectly labeled sample)。使用的方法是:MIL。特点是:调节的参数少。(BTW:其中提到了一个叫做bootstrap的概念,通俗的将就是对已有的观测样本反复的有放回抽样,通过多次计算这些放回抽样的结果,获取统计量的分布。)
接下来,文章介绍了跟踪中当前存在的主要挑战: 1、形变所产生的巨烈的表观的变化;2、平面外的旋转;3、场景光照度的变化。 同时,介绍了典型的跟踪系统的三个组成部分:1、appearance model,估计跟踪目标在特定位置的可能性; 2、 motion model ,同跟踪物体随时间改变的位置有关;3、a search strategy for finding,找到当前帧中目标最有可能的位置。本文重点放在第一部分,作者想达到的目标是能够跟踪到部分遮挡的物体而不出现明显的漂移,并且只有较少的参数。
对于appearance model的设计,一般有两种考虑。一种是只model 目标;另一种是将目标和背景都model。而后者其他领域已经取得了成功。参见后者,在on-line tracking中,常用的更新自适应appearance model的方法是:将当前tracker的位置作为正样本(有的时候也扩展非常邻近的位置作为正样本),将这个位置周围的位置作为负样本来更新appearance model。这也使得漂移的产生成为可能。为了解决这个问题,引入了半监督的方法。如Grabner et al.提出的semi-supervised的方法,将tracker得到的目标都认为是无标签的样本,而只有第一帧中的样本是有标签的。然后通过聚类的方法给定这些无标签样本一个伪标签,在继续使用有标签的方法进行跟踪。这个方法没有充分的利用到视频中有用信息,比如说相邻的帧之间的变化非常的小等等。tracker所得到的样本标签的模糊性促使multiple instance learning(MIL)的提出。MIL的基本思想是,在训练的过程中,样本不再是单个的patch块,而是将多个patch块放在一个小的样本集(称作bag)里。整个小的样本集(bag)有一个标签。又规定,若是这个bag里面至少有一个正样本,那么它的标签就是正的,反之就是负的。由这些小的样本集组成整个的training set。这样做的原因是学习的过程对于找到决策的边界有更好的灵活性。
对于tracker得到的或是扩展得到的图像patch块,计算出每个patch块的Harr-like特征,对于每一个图像patch块x,都由Harr-like特征的feature vector表示。对于每一帧待检测的图像,提取一个patch块的集合,这个集合满足: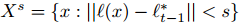
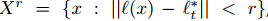
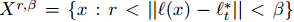
同时也可以考虑引入尺度变换参数,这样的好处是结果可以更加的准确;坏处是增加了参数的空间维度。可根据需求决定。
所以问题的关键是要求得使得概率最高时的那个bag(集合X),即:argmax(L),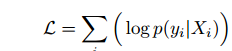
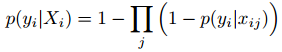
于是,仿造on-line boosting的方法,构造on-line MIL算法。
首先,由第一帧得到的信息,扩展正负样本,形成一组由patch块集合组成的数据集bags(带标签的);
然后,计算各个patch块的harr-like特征向量,用它来表示每一个image patch 块。样本的特征的条件概率分布满足高斯分布,均值和方差分别通过新得到样本更新,再由贝叶斯法则得到它的概率;
然后,构造一组M个弱分类;通过公式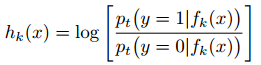
接下来,(用motion model 根据上一帧目标的位置,扩展目标的可能位置;根据公式:
然后,计算上面得到的目标位置集合中样本的似然概率的最大值,并将这个样本作为当前帧目标的位置;概率可以由sigmoid函数表示,又根据NOR model知道
最后,由上面更新的目标的位置,跟新分类器,如此在迭代上述过程。
个人觉得这篇文章的思想非常的新颖。漂移问题是on-line tracking最主要的问题。引起漂移最主要的原因就是,分类器更新时使用的样本本身的准确率存在问题。为了解决这个问题。有的作者采取的方式是放弃掉tracker得到的结果。将这些得到的patch块认为是无标签的,再通过聚类的方式得到一个伪标签,再通过有标签的方式来训练分类器。很显然这样的结果可以很好的解决目标跑出视频的情况。当目标再一次出现的时候可以继续跟踪到。但是,这样浪费掉了很多的有用信息。同时,增加了伪标签的求解过程,速度应该比on-line boosting方法还要慢。而本文作者处理的方式是:既然所得到的样本标签的准确率有问题,那么对得到的样本进行扩展,作为一个事件集。选出里面错误率最低的时间来更新目标的位置,也由此来更新分类器。准确率和速度都会好很多。
问题:
(1)文章中最终的算法(3.4)的数据集是通过tracker的location扩展得到吗?
(2)文章中3.1提到的 用motion model 根据上一帧目标的位置,扩展目标的可能位置,选出最有可能的位置即为目标的位置。既然已经得到了目标的位置,那为什么还要使用分类器啊?(具体是这样操作的,依照公式: