讲授神经网络的思想起源、神经元原理、神经网络的结构和本质、正向传播算法、链式求导及反向传播算法、神经网络怎么用于实际问题等
课程大纲:
神经网络的思想起源
神经元的原理
神经网络结构
正向传播算法
怎么用于实际问题
反向传播算法概述
算法的历史
神经网络训练时的优化目标函数
几个重要的复合函数求导公式
算法的推导
算法的总结
工程实现问题
全连接神经网络:也叫多层感知器模型(HLP)
BP不是神经网络,是训练神经网络的一种方法。像CNN、RNN是一种神经网络结构,而BP是一种训练神经网络的其中一种训练算法,所以不能说BP神经网络。
神经网络的思想起源:
人脑大约800亿个神经元组成,这些神经元由突触与其他神经元相互连接,交换电信号和化学信号,大脑通过神经元之间的协作完成各种功能。神经元之间的连接关系是通过进化、生长发育和后天刺激形成的。
人工神经网络是受动物神经系统的启发,是一仿生的方法,但只是简单的模仿,因为人大脑的神经元的拓扑结构非常复杂,人工神经网络只是进行了很多简化。
人工神经网络是感知器模型(f(x)=wTx+b,找一条线分开两类数据,不能解决异或问题)、logistic回归(输出属于正样本的概率值,h(x)=1/(1+e-(wT+b)),因为1/(1+e-x)的定义域为负无穷到正无穷值域为0到1)的进一步发展。人工神经网络的神经元的变换和逻辑斯蒂回归有点像。

神经元的原理:

原理是加权、激活。输入值:(x1,x2,x3,x4,x5),连接权重:(w1,w2,w3,w4,w5),连接权重绝对值越大表示两个神经元连接越紧密,偏置项:b,输出值:![]() ,向量和矩阵形式:f(wTx+b),f(x)=1/(a+e-x)。
,向量和矩阵形式:f(wTx+b),f(x)=1/(a+e-x)。
在神经网络还没出来之前,是机器学习和感知器模型。
sigmoid函数:f(x)=1/(1+e-x),定义域为负无穷到正无穷、值域为0到1、单调性为递增,导数为f(x)*(1-f(x)),即不需要知道一点的x值,只需知道该点的y(f(x))值就可以知道该点的导数值。
神经网络结构:
多层前馈神经网络:也称为多层感知器模型MLP、全连接神经网络。
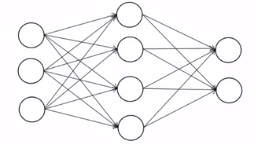
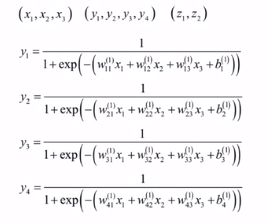

是一个分层结构(输入层,隐含层可以多个,输出层),每一层有多个神经元。
权重矩阵:每一行表示本层一个神经元和前一层所有神经元的连接权重,如果前一层有n个神经元,本层m个神经元,那么该矩阵为m*n的矩阵。w的上标表示对应层的权重矩阵,w的下标表示该对应矩阵的元素值。w(l)表示第l个隐含层和上一层的连接权重,b(l)表示第l个隐含层每个神经元对应的偏置组成的一个偏置向量,u(l)表示第l个隐含层每个神经元的临时输出值组成的一个临时向量。对临时向量u(l)的每一个分量分别用同样的激活函数进行映射产生输出,即u(l)和x(l)是一一映射产生输出值x(l)。神经网络每一层l就是完成x(l-1)到x(l)的映射。下边是映射的图解(核心):

正向传播算法:
神经网络实现的是向量到向量的映射 Rn-->Rm,本质上是一个多层的复合函数,通过调整权重和偏置项实现不同的映射,权重和偏置项的值通过训练得到。
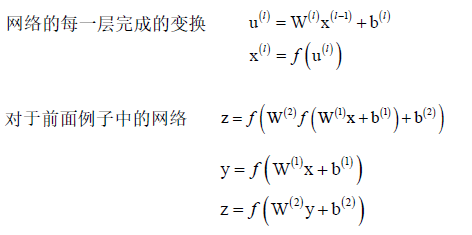
完整的正向传播算法:
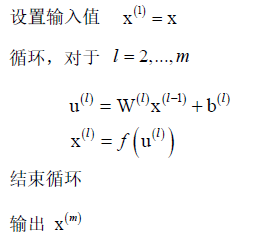

怎么用于实际问题:
分类问题-输入值为特征向量或原始数据,输出值为one-hot编码。(输入层神经元个数为输入向量的维数,输出层神经元个数为分类的类的个数。)
回归问题-输出值为回归函数值
对于分类问题,分类结果为输出层神经元的最大值
对于回归问题,直接是输出层的值

神经网络过程:权重矩阵w和偏置向量b是通过训练算法训练出来的,训练出来以后,利用正向传播算法,根据输入值预测出一个输出值,输出值就是想要的分类结果或回归结果。
输入层的层数:输入特征向量的维数
反向传播算法概述:
反向传播算法简称BP算法,用来训练神经网络,求出权重w和偏置项b。网络结构(层数、每层神经元个数)确定之后,通过算法调节w、b来形成映射。
训练的目标函数是损失函数L,通过反向传播算法和梯度下降法使损失函数L最小化。
求损失函数对每层权重矩阵w的每个元素w(l)ij的偏导数,及对应偏置向量每个元素的偏导数,反向传播算法是解决这样一个核心问题,这种算法源自于微积分中多元函数微分学里边的多元复合函数求导公式的链式法则,与梯度下降法配合完成网络的训练,链式法则计算目标函数对所有参数的导数,然后梯度(导数)算出来之后,再用梯度下降法进行更新,就可以算出目标函数的极小值来了。
反向传播算法1986年诞生(作者David E. Rumelhart, Geoffrey E. Hinton,Hinton是发明深度学习起到关键作用的人),反向传播算法诞生之后,人工神经网络就可以被有效的训练出来了,因此它就有了实用的价值了。
神经网络训练时的优化目标函数:
激活函数作用:使神经网络的复合函数是非线性的,如果去掉激活函数,不管神经网络是多少层,都是线性函数。
神经网络的权重和偏置参数通过训练得到,训练的目标是最小化训练样本的预测误差,以均方误差为例(也叫欧氏距离):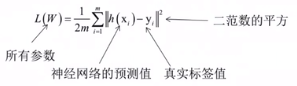
如果对所有参数的梯度值已经计算出来,则可以用梯度下降法更新: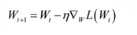
每层都有权重矩阵与偏置向量,如何计算损失函数对它们的导数值呢?![]() ,就是反向传播要做的事情。
,就是反向传播要做的事情。
几个重要的复合函数求导公式:
欧氏距离损失函数的导数:
根据多元复合函数求导的链式法则来推导几个重要的复合函数求导公式,由这几个公式可以清晰的推导出整个反向传播算法核心的公式。
(问题1问题2已知假设:x是n维输入向量,y是m维隐含层向量,W是x->y的m*n的权重矩阵,f是激励函数,即y=Wx核f(y))
问题1:已知y=Wx且f(y),求f对W的导数。
分析:由于W是一个矩阵,f是一个固定的函数,要求f对W矩阵的导数,可以先求f对W每个元素Wij的导数,然后已知f对Wij的导数得出f对W的导数。要求f对Wij的导数,看到是复合函数,则求f对y的导数再乘以y对x的导数。f是函数,y1、y2、y3...是中间变量,所以f对Wij的偏导数等于∑f对yi的偏导数乘以yi对Wij偏导数(i的范围是1到该层神经元个数)。其中yi对Wij偏导数等于xj。

问题2:求f对x的导数。
分析:思路同上,基于复合函数链式求导法则。

问题3:x->y是一一映射(即xi->yi),x和y都是n维向量,y=g(x)和f(y),yi=g(xi),求f对x的导数。

问题4:u=Wx和y=g(u)和f(y),求f对x的导数。
对于u=Wx和f(u)来说,根据问题2结论得f对x的导数为![]() ①。对于y=g(u)和f(y)来说,根据问题3的结论得f对u的导数为
①。对于y=g(u)和f(y)来说,根据问题3的结论得f对u的导数为![]() 。将②中y=g(u)的条件加上和f对u的导数带入①中,即得到此问题4的f对x的导数。
。将②中y=g(u)的条件加上和f对u的导数带入①中,即得到此问题4的f对x的导数。

其实问题4就等同于人工神经网络的变换,u=Wx+b,f(u)是当前隐含层的输出值,f(u)作为一个整体向量作为下一层的输入值。
问题5:y=g(x)和f(y),但是这里yi=gi(x1,x2,x3,...,xn),i=1,...,m,即这里函数g不固定且yi和xi不是一一映射。求f对x的导数。

其中 是雅克比矩阵,y是m维向量,x是n维向量。
是雅克比矩阵,y是m维向量,x是n维向量。
其实问题1-4都是问题5的一个特殊的例子,由问题5的结果可以导出问题1-4的结论。
求导的整体思路:
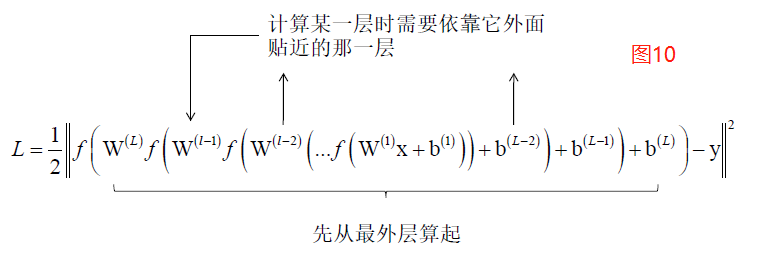
W(L)是第L-1层的神经元到第L层映射的权重矩阵。由上面五个问题的结论就可以导出反向传播算法了。上边是欧氏距离损失函数,需要计算L对W(L)、b(l)、W(L-1)、b(L-1)、...、W(1)、b(1)的偏导数,外面的一层好算,越到里边复合的越深,所以要借助外边的计算里边的,最外层是神经网络靠近后边的层,从外层依次忘里边推就得到最里边一层的偏导数了。
算法的推导:
这里梯度就是导数。

可知重要问题变为只需求L对u的导数即可,L对u的导数(梯度值)分两种情况讨论:
1.对于输出层(这里L为均方误差)来说:(观察图10和问题3可得L对u的导数)

2.对于隐含层来说:
思路:找到u(L+1)和u(L)等式关系,用L对u(L+1)的导数表示L对u(L)的导数,即从外层向里层算。

可知隐含层根据后面一层L对u(L+1)的导数算出L对前面一层u(L) 的梯度值来,L为误差函数,是一个固定的函数,由图10可知。
由以上两种情况可得出L对每层临时变量u的导数(又记为误差项)公式为:
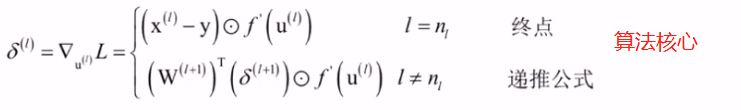
那么,有了误差项公式可以求出每一层的L对u(L)的导数,再有图11的公式可以算出来对应层L对权重矩阵W(L)和偏置项b(L)的导数来,这样就把所有层的参数W、b的梯度值就算出来了,所以算法的核心就是L对临时变量u(L)的导数,命名为误差项,其实不是真正意义上的误差,只是取名为误差项而已,根据后一层误差项计算前一层的误差项,根据误差项计算对W、b的导数,这样目标就完成了。
完整的反向传播算法
上边介绍的是对单个样本的,多个样本的话,把每个样本算出来的梯度值取个均值就是对W、b的导数了。
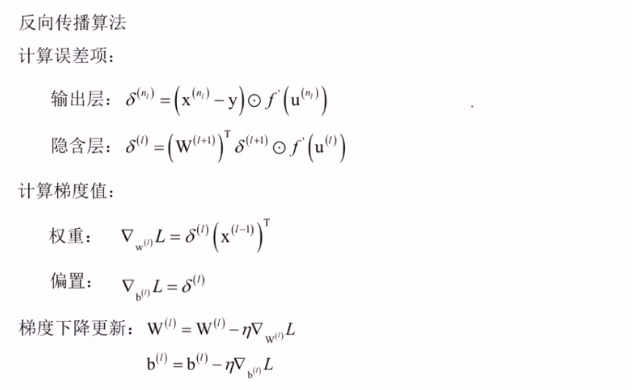
梯度下降法更新W、b的作用是使目标函数L极小化。整个过程分为正向传播和反向传播,反向传播是从输出层开始一层一层往前直到第一层隐含层。
算法的总结:
自己总结:L是x(l)的函数(在输出层可以是均方误差函数,在非输出层x(l)就是L函数的中间变量),x(l)是临时变量u(l)的函数(激活函数),u(l)是x(l-1)的函数(即x(l-1)加权重W和偏置b的变换),即L是自变量为W和b的多元复合函数,最终目标是求得使得L取到最小值的所有层的W和b的值,即得到取值W和b的人工神经网络机构模型,对于求W和b,先求出目标损失函数L对每层临时变量u(l)的偏导数再求L对该层W和b的偏导数,而目标损失函数L对每层临时变量u(l)的偏导数可以由后一层的L对每层临时变量u(l+1)的偏导数得到,即通过后一层对u(l+1)的偏导数算前一层对u(l)的偏导数,这就叫做反向传播算法,通过反向传播算法求出每层的L对W和b偏导数之后,需对所有W和b进行变化来使得L的值变小,这种变化就需要用到刚刚求到的每层的L对W和b偏导数进行更新W和b,每次更新所有W和b一次之后,损失函数值会变小,直到L的值在设定接受的范围内算法停止更新训练神经网络模型完成,即称为梯度下降法。
BP算法论文:

复合函数求导(BP算法)算出来L对W、b的导数之后,再用梯度下降法进行更新。
在用BP算法+梯度下降法训练神经网络时有几种不同的模式:
单样本模式
批量模式
除梯度下降法之外,还可以采用二阶技术,如牛顿法、随机挑度下降法(SGD)。
工程实现问题:
编程语言里边向量和矩阵是按行存储,x在前W在后。
