课程来源:https://coding.imooc.com/class/chapter/344.html#Anchor
本门课程的入门章节,简要介绍了tensorflow是什么,详细介绍了Tensorflow历史版本变迁以及tensorflow的架构和强大特性。并在Tensorflow1.0、pytorch、Tensorflow2.0之间做了对比。最后通过实战讲解了在Google cloud和AWS两个平台上的环境配置。
1-1课程导学
为什么要学Tensorflow?
深度学习迅猛发展;模型框架强大灵活;google+开源社区背书;在公司中应用广泛;2.0发布,机遇在手(相对于1.0,更加强大、灵活、易用、成熟)。
课程目标:
掌握灵活使用tensorflow框架的能力;
掌握相关的机器学习/深度学习的理论知识;
独立开发项目,掌握大厂一线编程经验;
达到初级深度学习算法工程师/研究者的水平。
课程特点:
重实战,请理论,配备多个特点项目(图像分类,房价预测,泰坦尼克生存预测,文本分类,文本生成,机器翻译);
内容丰富全面,自带“干货”(模型训练,tensorboard,模型保存与部署,分布式训练,Tfds/tfhub,tensor2tensor);
多平台云端环境GPU&kaggle数据集(google cloud环境配置,AWS环境配置,kaggle 10 Monkeys数据集,kaggle cifar10数据集,kaggle文本分类数据集,kaggle titanic生存预测数据集);
课程对使用TF1.0的学院也非常友好(原1.0学员可以轻松学习2.0,学习2.0的同学可以轻松读懂1.0代码);
课程长期维护(同步补充TF2.0正式版知识点,定期更新项目源码)。
课程章节:
第一章:tensorflow简介(tensorflow是什么、tensorflow历史、tensorflow vs pytorch。环境配置。);
第二章:tensorflow keras实战(tf框架:keras、回调函数。项目:图像分类、房价预测。知识点:分类问题、回归问题、损失函数;神经网络、激活函数、批归一化、dropout;wide&deep模型、超参数搜索。);
第三章:tensorflow基础API使用(tf框架:基础数据类型,自定义模型与损失函数、自定义求导、tf.function、图结构。项目:图像分类、房价预测。);
第四章:tensorflow dataset使用(tf框架:csv文件读取、tfrecord文件生成与读取、tf.data使用。项目:房价预测。);
第五章:tensorflow estimator使用与1.0(tf框架:estimator使用、特征列使用、tf1.0基本使用。项目:泰坦尼克生存预测。);
第六章:卷积神经网络(tf框架:卷积实现。项目:图像分类、kaggle 10monkeys,kaggle clifar10。理论:卷积、数据增强、迁移学习。);
第七章:循环神经网络(tf框架:LSTM实现。项目:文本分类、分本生成、Kaggle文本分类。原理:序列式问题、循环网络、LSTM、双向LSTM。);
第八章:tensorflow分布式(tf框架:分布式实现。项目:图像分类。);
第九章:tensorflow模型保存与部署(tf框架:模型保存、导出tflite、部署。项目:图像分类。);
第十章:机器翻译与tensor2tensor使用(tf框架:transformer实现、tensor2tensor使用。项目:机器翻译。理论:序列到序列模型、注意力机制、可缩放点积注意力、多头注意力)。
前五章是基础知识,后五章是高阶知识。
做完六个项目(机器翻译,图像分类,文本分类,文本生成,泰坦尼克生存预测,房价预测)应具有的能力:
问题建模的能力;特征工程的能力;搭建模型的能力。
本课程适合的人群:
想转行到深度学习方向的工程师;学习了理论但欠缺实践的深度学习starter;有志于、感兴趣深度学习的爱好者们;想快速做实验完成研究任务毕设任务的同学们。
本课程需要的基础:
python基础语法;
熟悉Linux环境;
了解机器学习与深度学习基础知识(有则更好,没有需要看完课程后系统学习)。
1-2tensorflow是什么
深度学习领域使用最为广泛的一个Google的开源软件库(最初由Google brain team进行开发的内部库,由于它的应用性Google决定把它开源出来):
采取数据流图,用于数值计算;
支持多种平台,GPU、CPU、移动设备;
最初用于深度学习,变得越来越通用(只要是能够表达成数据流图的问题,都可以使用tensorflow来进行解决,现在对于tensorflow的使用大多数还是深度学习)。
数据流图:
节点——处理数据;
线——节点间的输入输出关系;
线上运输张量(张量tensor就是所有的n维数据,所有的n维数据就构成了tensorflow中的数据的一个集合,对于0维数据来说它就是一个数字,对于1维数据来说他就是一个向量,对于二维来说就是一个矩阵,对于大于等于三维的数据统称为高维矩阵,正因为如此才命名为tensorflow,因为它是让tensor在数据流图中去进行流动);
节点被分配到各种计算设备上运行(它能够支持多种设备,只要把节点在某种设备上的执行算子写好就可以了)。
tensorflow的特性:
高度的灵活性(体现在数据流图上,只要能把数据的计算表示成数据流图就可以使用tensorflow,现在tensorflow主要用于神经网络,tensorflow对于神经网络的很多操作都进行了封装,比如像卷积、归一化、pooling等等,除了这些封装之外,还可以写自己的封装,像写一个python函数一样简单,写完以后就可以去做自己的事情了);
真正的可移植性(比如CPU、GPU、移动设备等等,比如说你在笔记本上训练了一个model,然后你想把它push到服务器上去进行运行,ok,tensorflow是可以支持的,但是你好像又改变注意了,你想把你训练的model保存出来跑到手机上,ok,tensorflow也可以支持,或者你有改变主意像把tensorflow部署到docker上在docker上运行,ok,这也是可以的,这样就体现了tensorflow它是移植性非常强大的一个库);
产品和科研结合(tensorflow研究最初是用于科研的,其实科研和工程还有一定的距离,科研的代码需要进一步各种各样的优化才能真正的做到产品上去,但是对于tensorflow则没有这个问题,Google团队把tensorflow优化的已经比较好了,做研究的代码可以无缝的用到产品上);
自动求微分;
多语言支持(tensorflow除了python以外,还支持各种各样的语言,比如说c++、java、javascript、R语言等);
性能最优化(在tensorflow刚刚出来的时候由于它运行的比较慢,很多深度学习库呢都会拿tensorflow来进行比较,然后来证明自己比tensorflow好多少倍,但是随着tensorflow一步一步的进行开发,这种情况一去不复返了,tensorflow现在应该是运行最快的一个库,对于分布式的tensorflow来说,它的加速比几乎是线性的)。
1-3tensorflow版本变迁与tf1.0架构
tesorflow版本变迁:
2015.11tensorflow宣布开源并首次发布;
2015.12支持GPUs,python3.3(v0.6);
2016.04分布式tensorflow(v0.8);
2016.11支持windows(v0.11);
2017.02性能改进,提升API稳定性(v1.0,它是tensorflow的一个分水岭,1.0和1.0以后版本使用是很不相同的,那个时期也是tensorflow怨声哀道的时候,不过这种情况在后边不会发生);
2017.04添加了对keras的支持(keras的后端可以设为tensorflow;在tensorflow中它也有了针对keras的集成版本也就是tf.keras下边的那些代码库,keras是tensorflow后期版本中所主推的一个feature,后边的课程中会主要以keras为基础来讲解如何使用tensorflow);
2017.08添加了更多高级的API,预算估算器,更多模型,初始TPU支持(v1.3);
2017.11添加了Eager execution(也是tensorflow2.0的一个主要特性)和tensorflow Lite(是一个对移动端的支持)(v1.5);
2018.03虽然没有发布新的版本,但是推出了很多封装库,TF-Hub(一个预训练的库),TensorFlow.js(tensorflow对于js的支持),TensorFlow Extended(TFX)(tensorflow的一些扩展库);
2018.05新入门内容;开始支持Cloud TPU模块与管道(管道是一种比较高效的数据输入方式,因为tensorflow发现其运行速度慢的瓶颈在于数据处理,因此1.6版本在数据处理方便做了一些优化)(v1.6);
2018.06添加了新的分布式策略API;同时支持了概率模型,因为它有了概率编程工具TensorFlow Probality(v1.8);
2018.08对Cloud Big Table集成(v1.10);
2018.10侧重于可用的API改进,使得API的可用性进一步加强(v1.12);
2019年TensorFlow v2.0发布,现在的状态是发布了预览版和alpha版,应该在不久的将来就会发布2.0的正式版。
下边讲两个重要版本的主要特性。
tensorflow1.0主要特性:
添加了对XLA(Accelerate Linear Algebra专门针对线性运算的编译器,这个编译器可以优化tensorflow,使它计算更快,它影响的只是tensorflow的底层,上层使用不到的)的支持(有了这个特性之后,tensorflow的训练速度提升了58倍;而且XLA还具有强大的可移植性,使得tensorflow1.0可以在移动设备上运行);
引入了更高级别的API,tf.layers/tf.metrics/tf.losses/tf.keras;
添加了Tensorflow的调试器;
还支持docker镜像,引入tensorflow serving服务,使得用tensorflow部署服务变得非常的简洁。
tensorflow1.0的架构:
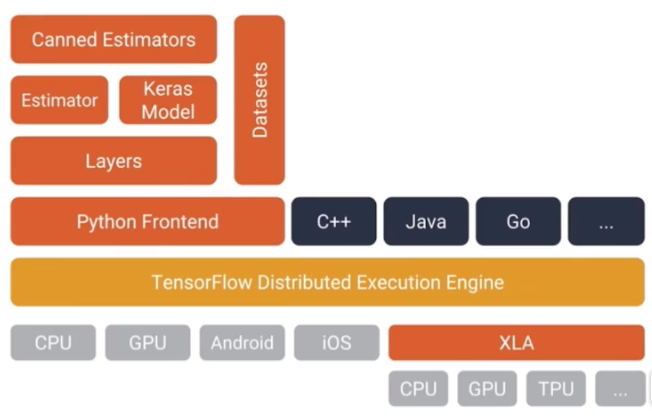
从下往上看,首先是底下的平台CPU、GPU、Android、ios、使用XLA编译的CPU、GPU、TPU等,在底层tensorflow在不同的设备上实现各样的算子(算子就是tensorflow的数据流图中的节点所支持的运算,各种各样的运算,每种运算都被称为一个算子,这些算子在不同平台上的实现就构成了tensorflow的可移植性,对于用户来说他使用的是这个算子的高层抽象,至于这个算子在哪个平台上运行是由tensorflow去进行决定的,因而tensorflow就具有了可移植性);
然后在底层之上有tensorflow Distributed Execution Engine,它是用来分配算子的,为什么要分配算子呢?对于用户来说呢用户所知道的就是用户构建了一个数据流图,至于这个数据流图是怎么去运行的,是由这一层来决定,这一层决定了数据流图中的每一个节点都分布在什么设备上或者哪个设备上,比如说你有1个GPU或者CPU,Engine就会把所有的计算分配到这个CPU或GPU上,这就是单机版的tensorflow,当你有多台设备的时候,比如你有8个GPU或者16个CPU,Engine这时候就要决定需要把哪一个算子给分配在哪一台机器上,这就是该层要做的事情;
在往上一层就是高层封装,包括python封装、c++封装、java封装等,在这些封装中用户利用这些封装可以很轻松的构建一个计算图,但是这个计算图的算子是怎么分配的对用户是不可见的因为它是由Engine做处理;
对于python来说,他还有各种各样的高层封装,包括Layers、Estimator、Keras Model、Datasets等等,本节课程中主要讲的是tensorflow的python是如何去使用的,包括Keras、Estimator、Datasets、Layers、Distribution Engine(这里边也有一些高层抽象,这些高层抽象会让你去选择如何定义分布式策略等等)。
1-4Tensorflow2.0架构
tensorflow2.0主要特性:
对tf.keras、eager mode进行了强化,也主推这两个feature,有了这连个feature之后,用户可以进行更加简单的模型构建;
增加了一些跨平台的部分,使得跨平台模型部署非常的鲁棒;
对API进行了改造,使得它更加的灵活,使得研究者或用户使用tensorflow对深度学习研究实验变得更加的方便快捷;
清楚了不推荐使用的API和减少重复的API,对API进行了简化,使得tensorflow的可用性大大提高。
tensorflow2.0架构:
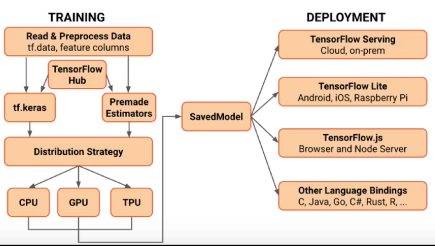
是1.0架构更加抽象的表达,和1.0架构相比,有些东西是互补的,有些东西是进阶的,还是从最下边看起。
左下角是一个tensorflow支持的平台列表,有CPU、GPU、TPU等,在1.0还有Android、iOS等,但在这里一般是不会在这些设备上进行训练的,而是用这些平台来做推导,把这些设备做了一个抽取形成了一个单独的部分deployment即部署,在训练完model之后把model保存下来,然后可以保存成各种各样的格式进行部署,包括在服务器上进行部署、在手机端进行部署、在javascript上进行部署、在其他语言上进行部署等等,这是一个比较底层的实现;
同理在底层实验之上,还是有distribution strategy,可以类比成1.0的那个distribution Engine,用来做分配算子和支持分布式等这些事情;
然后在此之上,还有高层的封装,包括tf.keras和estimators,这两个就是tensorflow2.0主推的tensrflow的使用方式,然后在后边的课程中我们会对其进行主要讲解,还有tensorflow Hub它是一个预训练模型的一个库,在本课程最后一章会对其进行讲解;
最上层呢,就是使用tensorflow的一些API进行数据的读取和预处理。
相对于1.0,2.0的架构有一个什么样的大的改动呢?
在tf.keras、estimators和distribution strategy之间还有一些中间层的API包括tf.layers等,这些API在tensorflow2.0中是不推荐使用的,因为tensorflow2.0是希望大家用稍微高层一点的封装去更简单的去做模型的构建这些工作;
2.0的架构他有了一个专门的deployment的部分,这个在1.0中是没有体现出来的,这也是在2.0当中新加的一个内容,它的部署的跨平台性非常的鲁棒。
2.0的架构图说是架构图,其实更像是一个开发流程,比如说从trainning开始,准备data,然后再构建模型,然后再用分布式进行训练,然后训练完之后再把它保存下来进行部署,所以说2.0的架构图不仅仅是一个架构图,而且还是一个流程图。
tensorflow2.0简化的模型开发流程:
使用tf.data加载数据;
使用tf.keras或premade estimator来进行模型的构建,同时可以使用tensorflow hub一些预训练的模型进行迁移学习;
然后使用eager mode进行运行和调试,eager mode的加入使得调试变得非常的便捷;
然后使用分发策略来进行分布式训练;
训练完之后导出模型到SavedModel;
然后使用tensorflow server、tensorflow lite、tensorflow.js进行模型部署。
以上开发流程也是2.0的特性的第一个特性的展开的描述。
tensorflow2.0强大的跨平台能力:
支持在服务器上部署,部署之后就可以通过HTTP/REST或GRPC/协议缓冲区去进行调用;
然后是移动端部署,tensorflow lite,可以部署在Android、iOS和嵌入式设备上;
然后是JavaScript上的部署;
然后用其他语言C、Java、go、c#、rust、julia、r等进行部署。
以上就是tensorflow2.0的第二个主要特性。
tensorflow2.0强大的研究实验能力:
主要体现在更灵活的模型搭建,更灵活的模型搭建主要体现在keras上,2.0中对keras进行了加强,它增加了keras功能API和子类API,允许创建更复杂的拓扑结构;
还体现在自定义的训练逻辑,除了tensorflow自己定义的一些模型、反向传播的训练方法之外,tensorflow2.0还支持让用户自定义它的梯度下降的方法,自定义方法就是使用tf.GradientTape和tf.cutom_gradient来进行实现;
虽然2.0主推用keras去进行模型的构建,但是一些比较底层的一些算子的封装,比如说卷积、pooling、全连接层等等,这样的封装层次也是始终和keras这样的高层封装结合使用的,这样就使得keras模型的使用更加的灵活;
在2.0中添加了很多高级的扩展,包括ragged tensors、tensor2tensor库等等,虽然tensor2tensor库还没有被集成到2.0中,但是我们可以在1.13版本中可以通过安装一个tensor2tensor库来对tensor2tensor进行使用,最后一章会对tensor2tensor来进行讲解。
1-5tensorflow与pytorch比较
从四个方面对比:入门时间,图创建和调试,全面性,序列化与部署。
入门时间:
tensorflow1.*, 使用的是静态图,虽然1.5中也加了eager mode/eager ecutation,但是不是默认打开的需要用一个命令让它打开,这里就假设没有eager mode,没有eager mode的情况下它就是一个静态图;由于它是静态图,需要学习一些额外的概念,包括图、回话、变量、占位符等,如果是动态图的话就不需要这些概念了;同理如果是静态图的话,除了学习这些额外的概念还要写很多样板的代码。
tensorflow2.0,默认eager mode是打开的,有了eager mode呢,tensorflow2.0中使用的计算图就是一个动态图,动态图就是在运行过程中可以更改的图结构,静态图就是构建完成之后就不能够再更改了;有了动态图之后,代码就像是直接集成在python中,而不是像1.0那样像是在调用一个库。
pytorch,和tensorflow2.0是类似的,里边直接采用了动态图结构;然后它相当于是numpy的一个扩展,也是直接集成在python中的,因为它是动态图结构。
图结构:
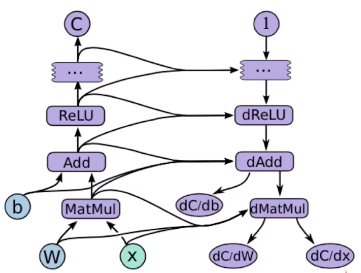
这张图做的是矩阵W和X做乘积再加上b,之后做一个ReLU激活函数,左侧是一个正向计算的一个图,右侧是与之对应的去做反向传播的图,反向传播的图是由tensorflow自动构建的,用户在使用的时候感觉不到它,然后有了这个反向传播的图之后,tensorflow就可以实现自动求导,自动求导是大部分深度学习框架所必须的一个功能,它可以大大减轻程序员的工作量。对于这样的一个图结构,tensorflow1.0里边的做法是,我把这个图结构构建出来之后,这个图结构就不会再变了,这就叫静态图, 这样的优势是由于图结构不再变化了我可以做一些优化,比如把一些算子给并起来或者做一些硬件上的优化。对于动态图来说,我不做这样一个限制,不做限制就说明这个图结构可以在中间去给它一些变动,得不到一个确定的图结构,有一些优化我就不能做了,效率就没有那么的高,但是因为可以随意的变动这个图,所以说调试起来就比较容易。
图创建和调试:
tensorflow1.*,静态图,难以调试,要学习tfdg的一个复杂的调试的工具;
对于tensorflow2.0与pytorch来说,由于使用的是动态图,可以像正常的调试python代码一样对其代码进行调试,自带调式工具。
全面性方面:
pytorch缺少,沿维度反转张量,检查无穷与非数值张量,快速傅里叶变换等,而tensorflow是有的,其他地方都差不多,而且这几个地方比较小,所以说几乎是一样的,而且随着时间的变化,pytorch和tensorflow变得越来越接近。
对于序列化与部署:
tensorflow2.0的序列化支持非常广泛,可以在js上、Android上、iOS上、服务器上都可以去执行,它的图保存的格式是protocol buffer的一个格式,也比较通用,用各种语言都可以对它进行读取,而且跨平台在各种平台上都可以运行;pytorch序列化和部署的支持就比较简单,可能就是简单的支持一个导出。
可以总结出,在应用性上,tensorflow1.0是比较难应用的,tensorflow2.0和pytorch是相互接近的;在调试上也比较类似,1.0比较难以调试,而pytorch和2.0是类似的;但是在全面性和序列化与部署上,2.0是可以超过pytorch的。
所以综合来看,2.0是优于pytorch,pytorch要比1.0要好。
1-6tensorflow环境配置