Keras是一个用于深度学习的Python库,它包含高效的数值库Theano和TensorFlow。
本文的目的是学习如何从csv中加载数据并使其可供Keras使用,如何用神经网络建立多类分类的数据进行建模,如何使用scikit-learn评估Keras神经网络模型。
前言,对两分类和多分类的概念描述
(前言是整理别人博客的笔记https://blog.csdn.net/qq_22238533/article/details/77774223)
1,在LR(逻辑回归)中,如何进行多分类?
一般情况下,我们所认识的lr模型是一个二分类的模型,但是能否用lr进行多分类任务呢?答案当然是可以的。
不过我们需要注意的是,我们有许多种思想利用lr来进行分类
2,训练多个二分类器的思想
既然天然的lr是用来做二分类,那么我们很自然地想到把多分类划分为多个二分类的任务。
具体有以下三种策略:
2.1 一对一
假如某个分类中有N个类别,我们将这N个类别进行两两配对(两两配对后转化为二分类问题)。那么我们可以得到个二分类器。(简单解释一下,相当于在N个类别里面抽2个)
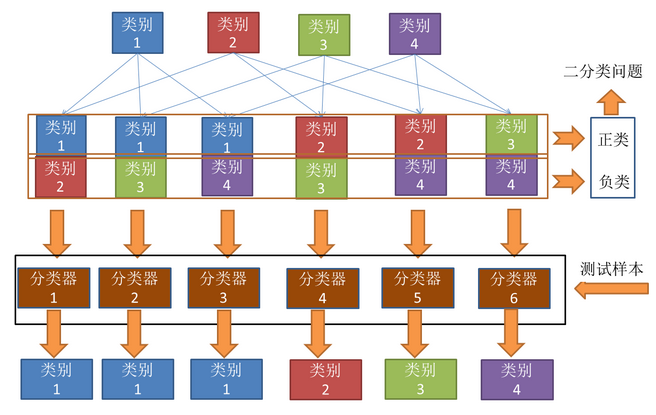
2.2 一对其余 (OvR)
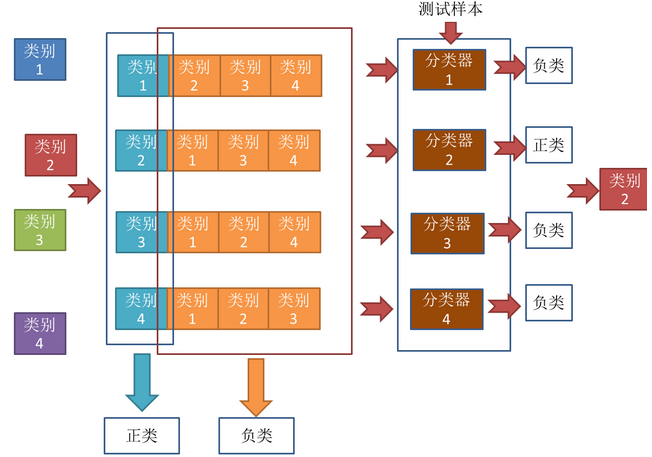
2.3 多对多(MvM)
3,对于上面的方法其实都是训练多个二分类器,那么有没有更加直接的方法对LR来进行多分类呢?
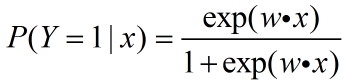
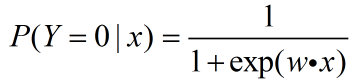
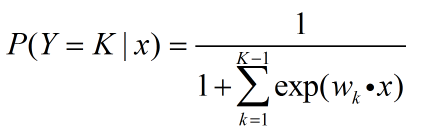
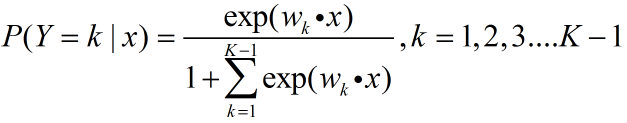
一,问题描述
这个数据集经过深入研究,是在神经网络上练习的一个很好的问题,因为所有4个输入变量都是数字的,并且具有相同的厘米级别。每个实例描述观察到的花测量的属性,输出变量是特定的鸢尾种类。
这是一个多类别的分类问题,意味着有两个以上的类需要预测,实际上有三种花种。这是用神经网络练习的一个重要问题类型,因为三个类值需要专门的处理。
鸢尾花数据集是一个充分研究的问题,我们可以期望实现模型精度为在95%至97%的范围内,这为开发我们的模型提供了一个很好的目标。
您可以从UCI机器学习库下载鸢尾花数据集,并将其放在当前工作目录中,文件名为 “ iris.csv”。
5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa 5.4,3.9,1.7,0.4,Iris-setosa 4.6,3.4,1.4,0.3,Iris-setosa 5.0,3.4,1.5,0.2,Iris-setosa 4.4,2.9,1.4,0.2,Iris-setosa 4.9,3.1,1.5,0.1,Iris-setosa 5.4,3.7,1.5,0.2,Iris-setosa 4.8,3.4,1.6,0.2,Iris-setosa 4.8,3.0,1.4,0.1,Iris-setosa 4.3,3.0,1.1,0.1,Iris-setosa 5.8,4.0,1.2,0.2,Iris-setosa 5.7,4.4,1.5,0.4,Iris-setosa 5.4,3.9,1.3,0.4,Iris-setosa 5.1,3.5,1.4,0.3,Iris-setosa 5.7,3.8,1.7,0.3,Iris-setosa 5.1,3.8,1.5,0.3,Iris-setosa 5.4,3.4,1.7,0.2,Iris-setosa 5.1,3.7,1.5,0.4,Iris-setosa 4.6,3.6,1.0,0.2,Iris-setosa 5.1,3.3,1.7,0.5,Iris-setosa 4.8,3.4,1.9,0.2,Iris-setosa 5.0,3.0,1.6,0.2,Iris-setosa 5.0,3.4,1.6,0.4,Iris-setosa 5.2,3.5,1.5,0.2,Iris-setosa 5.2,3.4,1.4,0.2,Iris-setosa 4.7,3.2,1.6,0.2,Iris-setosa 4.8,3.1,1.6,0.2,Iris-setosa 5.4,3.4,1.5,0.4,Iris-setosa 5.2,4.1,1.5,0.1,Iris-setosa 5.5,4.2,1.4,0.2,Iris-setosa 4.9,3.1,1.5,0.1,Iris-setosa 5.0,3.2,1.2,0.2,Iris-setosa 5.5,3.5,1.3,0.2,Iris-setosa 4.9,3.1,1.5,0.1,Iris-setosa 4.4,3.0,1.3,0.2,Iris-setosa 5.1,3.4,1.5,0.2,Iris-setosa 5.0,3.5,1.3,0.3,Iris-setosa 4.5,2.3,1.3,0.3,Iris-setosa 4.4,3.2,1.3,0.2,Iris-setosa 5.0,3.5,1.6,0.6,Iris-setosa 5.1,3.8,1.9,0.4,Iris-setosa 4.8,3.0,1.4,0.3,Iris-setosa 5.1,3.8,1.6,0.2,Iris-setosa 4.6,3.2,1.4,0.2,Iris-setosa 5.3,3.7,1.5,0.2,Iris-setosa 5.0,3.3,1.4,0.2,Iris-setosa 7.0,3.2,4.7,1.4,Iris-versicolor 6.4,3.2,4.5,1.5,Iris-versicolor 6.9,3.1,4.9,1.5,Iris-versicolor 5.5,2.3,4.0,1.3,Iris-versicolor 6.5,2.8,4.6,1.5,Iris-versicolor 5.7,2.8,4.5,1.3,Iris-versicolor 6.3,3.3,4.7,1.6,Iris-versicolor 4.9,2.4,3.3,1.0,Iris-versicolor 6.6,2.9,4.6,1.3,Iris-versicolor 5.2,2.7,3.9,1.4,Iris-versicolor 5.0,2.0,3.5,1.0,Iris-versicolor 5.9,3.0,4.2,1.5,Iris-versicolor 6.0,2.2,4.0,1.0,Iris-versicolor 6.1,2.9,4.7,1.4,Iris-versicolor 5.6,2.9,3.6,1.3,Iris-versicolor 6.7,3.1,4.4,1.4,Iris-versicolor 5.6,3.0,4.5,1.5,Iris-versicolor 5.8,2.7,4.1,1.0,Iris-versicolor 6.2,2.2,4.5,1.5,Iris-versicolor 5.6,2.5,3.9,1.1,Iris-versicolor 5.9,3.2,4.8,1.8,Iris-versicolor 6.1,2.8,4.0,1.3,Iris-versicolor 6.3,2.5,4.9,1.5,Iris-versicolor 6.1,2.8,4.7,1.2,Iris-versicolor 6.4,2.9,4.3,1.3,Iris-versicolor 6.6,3.0,4.4,1.4,Iris-versicolor 6.8,2.8,4.8,1.4,Iris-versicolor 6.7,3.0,5.0,1.7,Iris-versicolor 6.0,2.9,4.5,1.5,Iris-versicolor 5.7,2.6,3.5,1.0,Iris-versicolor 5.5,2.4,3.8,1.1,Iris-versicolor 5.5,2.4,3.7,1.0,Iris-versicolor 5.8,2.7,3.9,1.2,Iris-versicolor 6.0,2.7,5.1,1.6,Iris-versicolor 5.4,3.0,4.5,1.5,Iris-versicolor 6.0,3.4,4.5,1.6,Iris-versicolor 6.7,3.1,4.7,1.5,Iris-versicolor 6.3,2.3,4.4,1.3,Iris-versicolor 5.6,3.0,4.1,1.3,Iris-versicolor 5.5,2.5,4.0,1.3,Iris-versicolor 5.5,2.6,4.4,1.2,Iris-versicolor 6.1,3.0,4.6,1.4,Iris-versicolor 5.8,2.6,4.0,1.2,Iris-versicolor 5.0,2.3,3.3,1.0,Iris-versicolor 5.6,2.7,4.2,1.3,Iris-versicolor 5.7,3.0,4.2,1.2,Iris-versicolor 5.7,2.9,4.2,1.3,Iris-versicolor 6.2,2.9,4.3,1.3,Iris-versicolor 5.1,2.5,3.0,1.1,Iris-versicolor 5.7,2.8,4.1,1.3,Iris-versicolor 6.3,3.3,6.0,2.5,Iris-virginica 5.8,2.7,5.1,1.9,Iris-virginica 7.1,3.0,5.9,2.1,Iris-virginica 6.3,2.9,5.6,1.8,Iris-virginica 6.5,3.0,5.8,2.2,Iris-virginica 7.6,3.0,6.6,2.1,Iris-virginica 4.9,2.5,4.5,1.7,Iris-virginica 7.3,2.9,6.3,1.8,Iris-virginica 6.7,2.5,5.8,1.8,Iris-virginica 7.2,3.6,6.1,2.5,Iris-virginica 6.5,3.2,5.1,2.0,Iris-virginica 6.4,2.7,5.3,1.9,Iris-virginica 6.8,3.0,5.5,2.1,Iris-virginica 5.7,2.5,5.0,2.0,Iris-virginica 5.8,2.8,5.1,2.4,Iris-virginica 6.4,3.2,5.3,2.3,Iris-virginica 6.5,3.0,5.5,1.8,Iris-virginica 7.7,3.8,6.7,2.2,Iris-virginica 7.7,2.6,6.9,2.3,Iris-virginica 6.0,2.2,5.0,1.5,Iris-virginica 6.9,3.2,5.7,2.3,Iris-virginica 5.6,2.8,4.9,2.0,Iris-virginica 7.7,2.8,6.7,2.0,Iris-virginica 6.3,2.7,4.9,1.8,Iris-virginica 6.7,3.3,5.7,2.1,Iris-virginica 7.2,3.2,6.0,1.8,Iris-virginica 6.2,2.8,4.8,1.8,Iris-virginica 6.1,3.0,4.9,1.8,Iris-virginica 6.4,2.8,5.6,2.1,Iris-virginica 7.2,3.0,5.8,1.6,Iris-virginica 7.4,2.8,6.1,1.9,Iris-virginica 7.9,3.8,6.4,2.0,Iris-virginica 6.4,2.8,5.6,2.2,Iris-virginica 6.3,2.8,5.1,1.5,Iris-virginica 6.1,2.6,5.6,1.4,Iris-virginica 7.7,3.0,6.1,2.3,Iris-virginica 6.3,3.4,5.6,2.4,Iris-virginica 6.4,3.1,5.5,1.8,Iris-virginica 6.0,3.0,4.8,1.8,Iris-virginica 6.9,3.1,5.4,2.1,Iris-virginica 6.7,3.1,5.6,2.4,Iris-virginica 6.9,3.1,5.1,2.3,Iris-virginica 5.8,2.7,5.1,1.9,Iris-virginica 6.8,3.2,5.9,2.3,Iris-virginica 6.7,3.3,5.7,2.5,Iris-virginica 6.7,3.0,5.2,2.3,Iris-virginica 6.3,2.5,5.0,1.9,Iris-virginica 6.5,3.0,5.2,2.0,Iris-virginica 6.2,3.4,5.4,2.3,Iris-virginica 5.9,3.0,5.1,1.8,Iris-virginica
二,导入类和函数
我们从导入本文需要的所有类和函数开始。其中包括需要Keras的功能,还包括来自pandas的数据加载以及来自scikit-learn的数据准备和模型评估。
import numpy import pandas from keras.models import Sequential from keras.layers import Dense from keras.wrappers.scikit_learn import KerasClassifier from keras.utils import np_utils from sklearn.model_selection import cross_val_score from sklearn.model_selection import KFold from sklearn.preprocessing import LabelEncoder from sklearn.pipeline import Pipeline
三,初始化随机数生成器
下面,我们将随机数生成器初始化为常量值(7)
这对于确保我们可以再次精确地实现从该模型获得的结果非常重要,它确保可以再现训练神经网络模型的随机过程。
# fix random seed for reproducibility seed = 7 numpy.random.seed(seed)
四,记载数据集
可以直接加载数据集。因为输出变量包含字符串,所以最容易使用pandas加载数据。然后我们可以将属性(列)拆分为输入变量(X)和输出变量(Y)。
# load dataset
dataframe = pandas.read_csv("iris.csv", header=None)
dataset = dataframe.values
X = dataset[:,0:4].astype(float)
Y = dataset[:,4]
五,编码输出变量
输出变量包含三个不同的字符串值。
当使用神经网络对多类分类问题进行建模时,优良作法是将包含每个类值的值的向量的输出属性重新整形为一个矩阵,每个类值都有一个布尔值,以及给定实例是否具有该值是否有类值。
这称为one hot encoding 或者从分类变量创建虚拟变量。
例如:在这个问题中,三个类值是Iris-setosa,Iris-versicolor和Iris-virginica。如果我们有观察结果:
多类分类问题本质上可以分解为多个二分类问题,而解决二分类问题的方法有很多。这里我们利用Keras机器学习框架中的ANN(artificial neural network)来解决多分类问题。这里我们采用的例子是著名的UCI Machine Learning Repository中的鸢尾花数据集(iris flower dataset)。
多类分类问题与二类分类问题类似,需要将类别变量(categorical function)的输出标签转化为数值变量。这个问题在二分类的时候直接转换为(0,1)(输出层采用sigmoid函数)或(-1,1)(输出层采用tanh函数)。类似的,在多分类问题中我们将转化为虚拟变量(dummy variable):即用one hot encoding方法将输出标签的向量(vector)转化为只在出现对应标签的那一列为1,其余为0的布尔矩阵。以我们所用的鸢尾花数据为例:
sample, label 1, Iris-setosa 2, Iris-versicolor 3, Iris-virginica
用one hot encoding转化后如下:
sample, Iris-setosa, Iris-versicolor, Iris-virginica 1, 1, 0, 0 2, 0, 1, 0 3, 0, 0, 1
注意这里不要将label直接转化成数值变量,如1,2,3,这样的话与其说是预测问题更像是回归预测的问题,后者的难度比前者大。(当类别比较多的时候输出值的跨度就会比较大,此时输出层的激活函数就只能用linear)
我们可以通过首先使用scikit-learn类LabelEncoder将字符串一致地编码为整数来完成此操作。然后使用Keras函数to_categorical()将整数向量转换为一个热编码
# encode class values as integers encoder = LabelEncoder() encoder.fit(Y) encoded_Y = encoder.transform(Y) # convert integers to dummy variables (i.e. one hot encoded) dummy_y = np_utils.to_categorical(encoded_Y)
六,定义神经网络模型
Keras库提供了包装类,允许您在scikit-learn中使用Keras开发的神经网络模型。
Keras中有一个KerasClassifier类,可用作scikit-learn中的Estimator,它是库中基本类型的模型。KerasClassifier将函数的名称作为参数。该函数必须返回构建的神经网络模型,为训练做好准备。
下面是一个函数,它将为鸢尾花分类问题创建一个基线神经网络。它创建了一个简单的完全连接的网络,其中一个隐藏层包含8个神经元。
隐藏层使用整流器激活功能,这是一种很好的做法。因为我们对鸢尾花数据集使用了单热编码,所以输出层必须创建3个输出值,每个类一个。具有最大值的输出值将被视为模型预测的类。
这个简单的单层神经网络的网络拓扑可以概括为:
4 inputs -> [8 hidden nodes] -> 3 outputs
请注意,我们在输出层使用“ softmax ”激活功能。这是为了确保输出值在0和1的范围内,并且可以用作预测概率。
最后,网络使用具有对数损失函数的高效Adam梯度下降优化算法,在Keras中称为“ categorical_crossentropy ”。
# define baseline model def baseline_model(): # create model model = Sequential() model.add(Dense(8, input_dim=4, activation='relu')) model.add(Dense(3, activation='softmax')) # Compile model model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) return model
我们现在可以创建我们的KerasClassifier用于scikit-learn。
我们还可以在构造KerasClassifier类中传递参数,该类将传递给内部用于训练神经网络的fit()函数。在这里,我们将时期数量传递为200,批量大小为5,以便在训练模型时使用。通过将verbose设置为0,在训练时也会关闭调试。
estimator = KerasClassifier(build_fn=baseline_model, epochs=200, batch_size=5, verbose=0)
七,使用k-fold交叉验证评估模型
Keras是基于Theano或Tensorflow底层开发的简单模块化的神经网络框架,因此用Keras搭建网络结构会比Tensorflow更加简单。这里我们将使用Keras提供的KerasClassifier类,这个类可以在scikit-learn包中作为Estimator使用,故利用这个类我们就可以方便的调用sklearn包中的一些函数进行数据预处理和结果评估(此为sklearn包中模型(model)的基本类型)。
对于网络结构,我们采用3层全向连接的,输入层有4个节点,隐含层有10个节点,输出层有3个节点的网络。其中,隐含层的激活函数为relu(rectifier),输出层的激活函数为softmax。损失函数则相应的选择categorical_crossentropy(此函数来着theano或tensorflow,具体可以参见这里)(二分类的话一般选择activation=‘sigmoid’, loss=‘binary_crossentropy’)。
PS:对于多类分类网络结构而言,增加中间隐含层能够提升训练精度,但是所需的计算时间和空间会增大,因此需要测试选择一个合适的数目,这里我们设为10;此外,每一层的舍弃率(dropout)也需要相应调整(太高容易欠拟合,太低容易过拟合),这里我们设为0.2。
我们现在可以在训练数据上评估神经网络模型。
scikit-learn具有使用一套技术评估模型的出色能力。评估机器学习模型的黄金标准是k倍交叉验证。
首先,我们可以定义模型评估程序。在这里,我们将折叠数设置为10(一个很好的默认值)并在分区之前对数据进行洗牌。
kfold = KFold(n_splits=10, shuffle=True, random_state=seed)
现在我们可以使用10倍交叉验证程序(kfold)在我们的数据集(X和dummy_y)上评估我们的模型(估计器)。
评估模型仅需要大约10秒钟,并返回一个对象,该对象描述了对数据集的每个分割的10个构建模型的评估。
results = cross_val_score(estimator, X, dummy_y, cv=kfold)
print("Baseline: %.2f%% (%.2f%%)" % (results.mean()*100, results.std()*100))
结果总结为数据集上模型精度的均值和标准差。这是对看不见的数据的模型性能的合理估计。对于这个问题,它也属于已知的最佳结果范围。
Accuracy: 97.33% (4.42%)
八, 代码实现
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.wrappers.scikit_learn import KerasClassifier
from keras.utils import np_utils
from sklearn.model_selection import train_test_split, KFold, cross_val_score
from sklearn.preprocessing import LabelEncoder
# load dataset
dataframe = pd.read_csv("iris.csv", header=None)
dataset = dataframe.values
X = dataset[:, 0:4].astype(float)
Y = dataset[:, 4]
# encode class values as integers
encoder = LabelEncoder()
encoded_Y = encoder.fit_transform(Y)
# convert integers to dummy variables (one hot encoding)
dummy_y = np_utils.to_categorical(encoded_Y)
# define model structure
def baseline_model():
model = Sequential()
model.add(Dense(output_dim=10, input_dim=4, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(output_dim=3, input_dim=10, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
estimator = KerasClassifier(build_fn=baseline_model, nb_epoch=40, batch_size=256)
# splitting data into training set and test set. If random_state is set to an integer, the split datasets are fixed.
X_train, X_test, Y_train, Y_test = train_test_split(X, dummy_y, test_size=0.3, random_state=0)
estimator.fit(X_train, Y_train)
# make predictions
pred = estimator.predict(X_test)
# inverse numeric variables to initial categorical labels
init_lables = encoder.inverse_transform(pred)
# k-fold cross-validate
seed = 42
np.random.seed(seed)
kfold = KFold(n_splits=10, shuffle=True, random_state=seed)
results = cross_val_score(estimator, X, dummy_y, cv=kfold)
九,总结
在这篇文章中,我们学习了如何使用Keras Python库开发和评估神经网络以进行深度学习。学习了以下知识:
- 如何加载数据并使其可用于Keras。
- 如何使用一个热编码准备多类分类数据进行建模。
- 如何使用keras神经网络模型与scikit-learn。
- 如何使用Keras定义神经网络进行多类分类。
- 如何使用带有k-fold交叉验证的scikit-learn来评估Keras神经网络模型
十,参考
- http://machinelearningmastery.com/multi-class-classification-tutorial-keras-deep-learning-library/
- http://datascience.stackexchange.com/questions/10048/what-is-the-best-keras-model-for-multi-label-classification
- http://stackoverflow.com/questions/28064634/random-state-pseudo-random-numberin-scikit-learn
- http://scikit-learn.org/stable/modules/classes.html