https://mp.weixin.qq.com/s/yato1PrnHe517J8twgZFOg
介绍ECC(Error Correcting Code/Error Checking and Correcting)的实现框架。不涉及编码的具体实现细节。

1. 码:Code

所有编码(如奇偶校验码、海明码)的抽象父类。
包含如下几个方面:
a. 能否检错:canDetect;
b. 能否纠错:canCorrect;
c. width():输入为数据的宽度,输出为编码后码文的宽度,一般情况下为数据和监督码的宽度之和;
d. encode(x):把数据x进行编码,并输出编码后的码文;
e. decode(y):对码文y进行解码,输出解码结果Decoding;
f. swizzle(x):参考注释;
2. 解码结果:Decoding

Decoding为解码结果,包含如下几个方面:
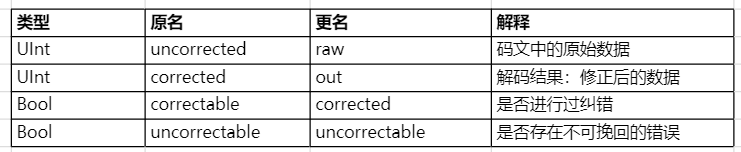
a. uncorrected:码文中未纠错的数据,即码文中的原始数据;
b. corrected: 使用监督码纠错之后的数据,即解码的输出结果;
c. correctable:根据各种码的实现,correctable意义为:有没有进行纠错;
d. uncorrectable:根据各种码的实现,uncorrectable的意义为:解码输出的结果是否正确;
e. error:是否包含错误,无论是否可以纠正的错误,都视为错误;
correctable/uncorrectable的命名是有问题的,词不达意,且造成误解。
从字面意思上看,correctable和uncorrectable应该相反,即correctable = !uncorrectable,为什么会定义两个呢?所以不能从字面意思上理解,他们代表了两个不同的意义。
correctable和uncorrectable分别代表能修正的错误位和不能修正的错误位?也不是,两者的类型皆为Bool,而非UInt。
单从命名上无法推知他们的意义。
参考IdentityCode/ParityCode/SECCode的实现之后,推知两者的意义分别为:
a. correctable:有没有进行纠错;
b. uncorrectable:解码输出的结果是否正确,即corrected的值是否正确(是否存在不可挽回的错误);
即两者标识从原始数据(uncorrected)到最终数据(corrected)过程中的两个情况:
a. 是否发生了纠错;
b. 是否纠正了错误;
为了提高可读性,个人尝试对Decoding改名如下:

PS. 因为对码研究有限,这个修改未必正确,提请注意。
再回过头来看uncorrectable的注释:

因为uncorrectable是对纠错结果的标识,如果uncorrectable为真,则存在不可挽回的错误,即不可纠正的错误,那么有没有发生过纠错(由correctable标识)就无关紧要了。
3. IdentityCode
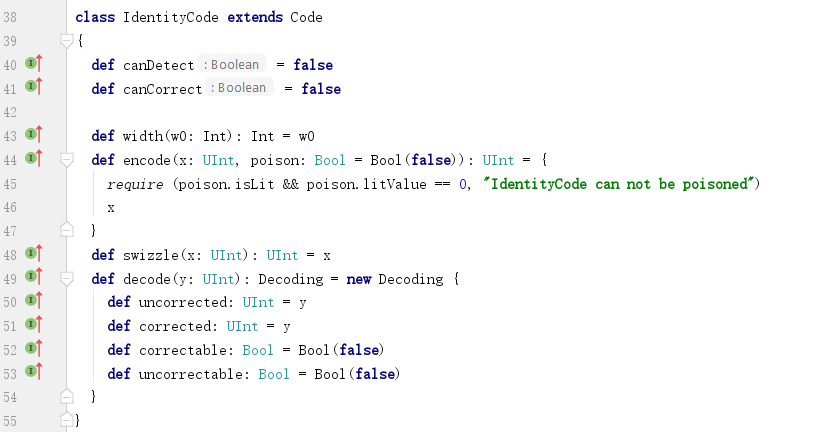
相同编码。
a. 没有检错能力:def canDetect = false
b. 没有纠错能力:def canCorrect = false
c. 码文宽度与数据宽度相同:def width(w0: Int): Int = w0
d. 码文与数据相同,没有监督码:

e. swizzle:没有研究;
f. decode:

重构之后为:

a. 码文中的原始数据(raw)为y,即全部都是原始数据,不存在监督码;
b. 最终输出的数据(out)为y;
c. 是否发生过纠错(corrected):没有;
这里存在两个层次:首先IdentityCode没有纠错能力,进而也没有发生纠错;
d. 是否存在不可纠正的错误(uncorrectable):没有;
这个没有是因为IdentityCode没有检错能力,不知道是否存在错误;
4. ParityCode

奇偶检验码。
a. 能够检错:def canDetect: Boolean = true
b. 不能纠错:def canCorrect: Boolean = false
c. 含有1位监督码:def width(w0: Int): Int = w0+1
d. 使用逐位异或计算奇偶校验码:def encode(x: UInt, poison: Bool = Bool(false)): UInt = Cat(x.xorR ^ poison, x)
e. decode:

其中:
a. 码文中的数据(raw)为去掉最高的奇偶校验码:val raw: UInt = y(y.getWidth-2,0)
b. 最终输出的数据(out)为raw:不具备纠错能力;
c. 是否发生过纠错(corrected):没有,同IdentityCode;
d. 是否存在不可挽回的错误:因为没有纠错能力,所以只要发生错误,即是不可挽回的错误。检错通过对码文逐位异或实现。如果结果为0,则没检测到错误(检错能力有限,不代表没有错误);如果结果为1,则检测到错误。
5. SECCode
既能检错,又能纠错的单个错误校正码(single-error-correcting)。这里不具体研究其实现,只研究decode输出的Decoding。
监督码的值代表发生错误的位:

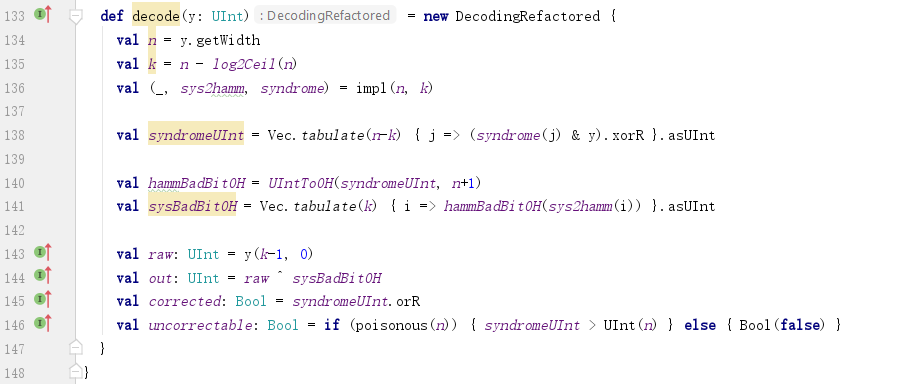
其中:
a. 码文中的原始数据(raw):y(k-1, 0),除去监督码;
b. 最终输出的数据(out)为纠错后的数据,把检测到错误的位反转:val out: UInt = raw ^ sysBadBitOH
c. 是否发生过纠错(corrected):如果监督码不为0,则发生了纠错:val corrected: Bool = syndromeUInt.orR;
d. 是否存在不可挽回的错误(uncorrectable)

如果长度合适,则所有的码文都可以纠正,即uncorrectable恒为Bool(false);
如果长度不合适,则是否能够纠正取决于监督码是否异常:syndromeUInt > UInt(n)
6. SECDEDCode
Single Error Correction, Double Error Detection。
能力有限,这里不做研究了。
7. ErrGen

错误发生器。
8. CanHaveErrors
是否包含错误的特征。
9. ECCParams

ECC的参数:
a. 字节数;
b. 码的类型;
c. 是否通知错误;
10. 伴生对象Code

方便从名称生成相应的码的对象。
11. 附录
ECCRefactored.scala:
略