一、 卷积层
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
一维卷积层,输入的尺度是(N, C_in,L),输出尺度( N,C_out,L_out)的计算方式:
$$
out(N_i, C_{out_j})=bias(C {out_j})+\sum^{C{in}-1}{k=0}weight(C{out_j},k)\bigotimes input(N_i,k)
$$
说明
bigotimes: 表示相关系数计算
stride: 控制相关系数的计算步长
dilation: 用于控制内核点之间的距离,详细描述在这里
groups: 控制输入和输出之间的连接, group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
Parameters:
in_channels(int) – 输入信号的通道
out_channels(int) – 卷积产生的通道
kerner_size(int or tuple) - 卷积核的尺寸
stride(int or tuple, optional) - 卷积步长
padding (int or tuple, optional)- 输入的每一条边补充0的层数
dilation(int or tuple, `optional``) – 卷积核元素之间的间距
groups(int, optional) – 从输入通道到输出通道的阻塞连接数
bias(bool, optional) - 如果bias=True,添加偏置
shape:
输入: (N,C_in,L_in)
输出: (N,C_out,L_out)
输入输出的计算方式:
$$L_{out}=floor((L_{in}+2padding-dilation(kernerl_size-1)-1)/stride+1)$$
变量:
weight(tensor) - 卷积的权重,大小是(out_channels, in_channels, kernel_size)
bias(tensor) - 卷积的偏置系数,大小是(out_channel)
例子:

class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
说明
bigotimes: 表示二维的相关系数计算
stride: 控制相关系数的计算步长
dilation: 用于控制内核点之间的距离,详细描述在这里
groups: 控制输入和输出之间的连接: group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
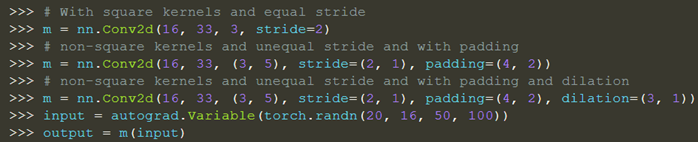
参数kernel_size,stride,padding,dilation也可以是一个int的数据,此时卷积height和width值相同;也可以是一个tuple数组,tuple的第一维度表示height的数值,tuple的第二维度表示width的数值
Parameters:
in_channels(int) – 输入信号的通道
out_channels(int) – 卷积产生的通道
kerner_size(int or tuple) - 卷积核的尺寸
stride(int or tuple, optional) - 卷积步长
padding(int or tuple, optional) - 输入的每一条边补充0的层数
dilation(int or tuple, optional) – 卷积核元素之间的间距
groups(int, optional) – 从输入通道到输出通道的阻塞连接数
bias(bool, optional) - 如果bias=True,添加偏置
shape:
input: (N,C_in,H_in,W_in)
output: (N,C_out,H_out,W_out)
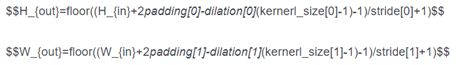
变量:
weight(tensor) - 卷积的权重,大小是(out_channels, in_channels,kernel_size)
bias(tensor) - 卷积的偏置系数,大小是(out_channel)
例子:
二、Padding方法
torch.nn.ReflectionPad2d
使用输入边界的反射填充输入张量.
padding (int, tuple) – 填充的大小. 如果是int, 则在所有边界填充使用相同的.
import torch from torch.autograd import Variable x = Variable(torch.randn(1, 3, 2, 2), requires_grad=True) # torch.randn生成服从正态分布的(0,1)之间的数字 l = torch.nn.ReflectionPad2d(1)(x).sum() l.backward()

torch.nn.ReplicationPad2d
使用输入边界的复制填充输入张量.padding (int, tuple) – 填充的大小. 如果是int, 则在所有边界使用相同的填充. 如果是4个元组, 则使用(paddingLeft, paddingRight, paddingTop, paddingBottom)

torch.nn.ZeroPad2d(padding)
用零填充输入张量边界.

torch.nn.ConstantPad2d(padding, value)
用一个常数值填充输入张量边界

三、归一化层(Norm)
BatchNorm
batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) torch.nn.BatchNorm3d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
参数:
num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
公式
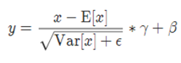
LayerNorm
channel方向做归一化,算CHW的均值,主要对RNN作用明显
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
参数:
normalized_shape: 输入尺寸
[∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]]
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
elementwise_affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
公式:

InstanceNorm
一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
torch.nn.InstanceNorm1d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False) torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False) torch.nn.InstanceNorm3d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
参数:
num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
公式:
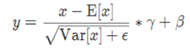
GroupNorm
将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束。
torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)
参数:
num_groups:需要划分为的groups
num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 布尔值,当设为true,给该层添加可学习的仿射变换参数。
公式:

SwitchableNorm
是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法
LocalResponseNorm
torch.nn.LocalResponseNorm(size, alpha=0.0001, beta=0.75, k=1.0)
参数:
size:用于归一化的邻居通道数
alpha:乘积因子,Default: 0.0001
beta :指数,Default: 0.75
k:附加因子,Default: 1
公式:
