前言
logstash本身就可以具有文件数据采集的功能了,为什么还需要在前面加一层filebeat?理由如下:
logstash是使用Java编写,插件是使用JRuby编写,对机器的资源要求会比较高,在logstash中做数据的逻辑过滤已经很吃服务器性能了(即logstash 具有filter功能,能过滤分析日志)。为了分摊当前服务器cpu资源,所以将使用GO编写的轻量级的filebeat作为单独组件,放在待收集日志的服务器上使用。
简单概述
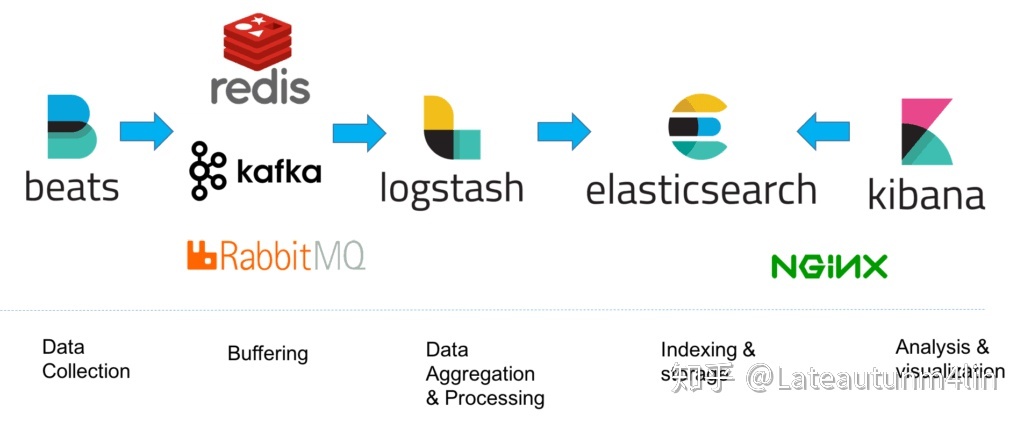
最近在了解ELK做日志采集相关的内容,这篇文章主要讲解通过filebeat来实现日志的收集。日志采集的工具有很多种,如fluentd, flume, logstash,betas等等。首先要知道为什么要使用filebeat呢?因为logstash是jvm跑的,资源消耗比较大,启动一个logstash就需要消耗500M左右的内存,而filebeat只需要10来M内存资源。常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat送到kafka消息队列,然后使用logstash集群读取消息队列内容,根据配置文件进行过滤。然后将过滤之后的文件输送到elasticsearch中,通过kibana去展示。
官网下载地址:https://www.elastic.co/cn/downloads/beats/filebeat
官网配置说明:https://www.elastic.co/guide/en/beats/filebeat/current/configuring-howto-filebeat.html

工作原理:
Filebeat由两个主要组件组成:prospector 和harvester。这些组件一起工作来读取文件(tail file)并将事件数据发送到您指定的输出
启动Filebeat时,它会启动一个或多个查找器,查看您为日志文件指定的本地路径。 对于prospector 所在的每个日志文件,prospector 启动harvester。 每个harvester都会为新内容读取单个日志文件,并将新日志数据发送到libbeat,后者将聚合事件并将聚合数据发送到您为Filebeat配置的输出。
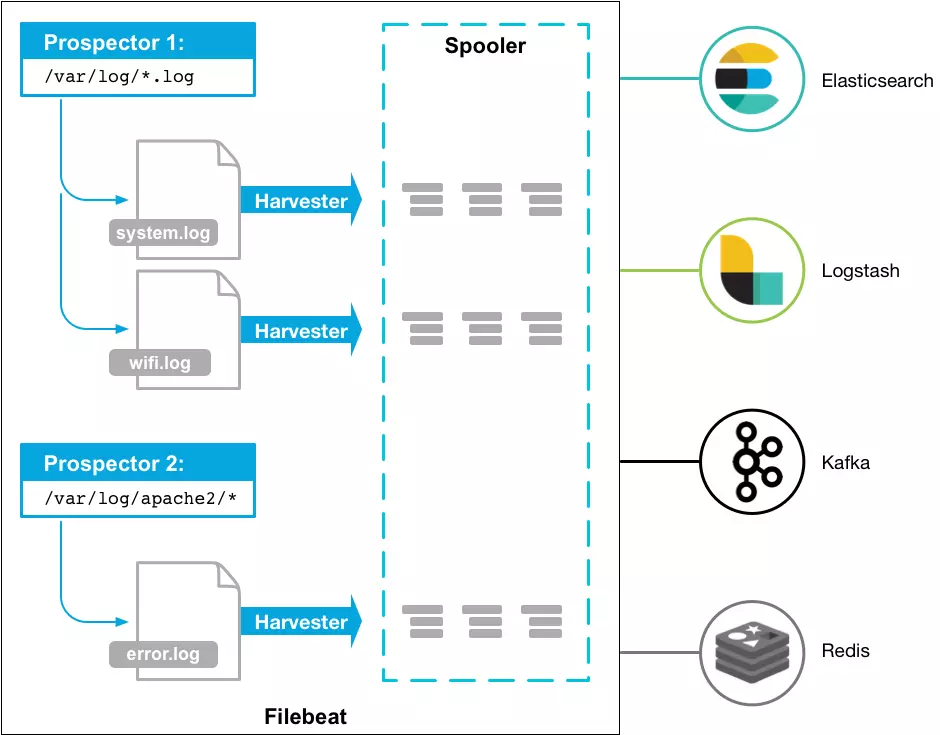
harvester(收割机)
harvester :负责读取单个文件的内容。读取每个文件,并将内容发送到 the output
每个文件启动一个harvester, harvester 负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态
如果文件在读取时被删除或重命名,Filebeat将继续读取文件。
这有副作用,即在harvester关闭之前,磁盘上的空间被保留。默认情况下,Filebeat将文件保持打开状态,直到达到close_inactive状态
关闭harvester会产生以下结果:
1)如果在harvester仍在读取文件时文件被删除,则关闭文件句柄,释放底层资源。
2)文件的采集只会在scan_frequency过后重新开始。
3)如果在harvester关闭的情况下移动或移除文件,则不会继续处理文件。
要控制收割机何时关闭,请使用close_ *配置选项
prospector(采矿者)
prospector 负责管理harvester并找到所有要读取的文件来源。
如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。
每个prospector都在自己的Go协程中运行。
以下示例将Filebeat配置为从与指定的匹配的所有日志文件中收集行:
filebeat.prospectors:
- type: log
paths:
- /var/log/*.log
- /var/path2/*.log
Filebeat目前支持两种prospector类型:log和stdin。
每个prospector类型可以定义多次。
日志prospector检查每个文件以查看harvester是否需要启动,是否已经运行,
或者该文件是否可以被忽略(请参阅ignore_older)。
只有在harvester关闭后文件的大小发生了变化,才会读取到新行。
注:Filebeat prospector只能读取本地文件, 没有功能可以连接到远程主机来读取存储的文件或日志。
Filebeat如何保持文件的状态?
Filebeat 保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中。
该状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。
如果输出(例如Elasticsearch或Logstash)无法访问,Filebeat会跟踪最后发送的行,并在输出再次可用时继续读取文件。
在Filebeat运行时,每个prospector内存中也会保存的文件状态信息,
当重新启动Filebeat时,将使用注册文件的数据来重建文件状态,Filebeat将每个harvester在从保存的最后偏移量继续读取。
每个prospector为它找到的每个文件保留一个状态。
由于文件可以被重命名或移动,因此文件名和路径不足以识别文件。
对于每个文件,Filebeat存储唯一标识符以检测文件是否先前已采集过。
如果您的使用案例涉及每天创建大量新文件,您可能会发现注册文件增长过大。请参阅注册表文件太大?编辑有关您可以设置以解决此问题的配置选项的详细信息。
Filebeat如何确保至少一次交付
Filebeat保证事件至少会被传送到配置的输出一次,并且不会丢失数据。 Filebeat能够实现此行为,因为它将每个事件的传递状态存储在注册文件中。
在输出阻塞或未确认所有事件的情况下,Filebeat将继续尝试发送事件,直到接收端确认已收到。
如果Filebeat在发送事件的过程中关闭,它不会等待输出确认所有收到事件。
发送到输出但在Filebeat关闭前未确认的任何事件在重新启动Filebeat时会再次发送。
这可以确保每个事件至少发送一次,但最终会将重复事件发送到输出。
也可以通过设置shutdown_timeout选项来配置Filebeat以在关闭之前等待特定时间。
注意:
Filebeat的至少一次交付保证包括日志轮换和删除旧文件的限制。如果将日志文件写入磁盘并且写入速度超过Filebeat可以处理的速度,或者在输出不可用时删除了文件,则可能会丢失数据。
在Linux上,Filebeat也可能因inode重用而跳过行。有关inode重用问题的更多详细信息,请参阅filebeat常见问题解答。
示例:Filebeat --> Kafka (单个topic)
filebeat.prospectors: - type: log paths: - /home/hottopic/logs/b612/8086/b612.json - /home/hottopic/logs/b612/8088/b612.json json.keys_under_root: true json.overwrite_keys: true processors: - drop_fields: fields: ["offset","prospector", "tags","beat.name", "beat.version"] output: kafka: enabled: true hosts: ["172.17.65.210:9092", "172.17.65.211:9092"] topic: adsdk compression: gzip required_acks: 1 max_message_bytes: 1000000 max_procs: 1
Filebeat --> Kafka (多个topic)
filebeat.prospectors: - type: log paths: - /home/hottopic/logs/b612/8086/b612.json - /home/hottopic/logs/b612/8088/b612.json fields: log_topics: adsdk json.keys_under_root: true json.overwrite_keys: true - type: log paths: - /home/hottopic/logs/foodie/8086/foodie.json - /home/hottopic/logs/foodie/8088/foodie.json fields: log_topics: foodie-adsdk json.keys_under_root: true json.overwrite_keys: true processors: - drop_fields: fields: ["offset","prospector", "tags","beat.name", "beat.version"] output: kafka: enabled: true hosts: ["172.17.65.210:9092", "172.17.65.211:9092", "172.17.65.212:9092"] topic: '%{[fields][log_topics]}' compression: gzip required_acks: 1 max_message_bytes: 1000000 max_procs: 1
Filebeat ---> ES (单个index)
filebeat.inputs: - type: log enabled: true paths: - /home/www-data/logs/prod-zepeto-access.log json.keys_under_root: true json.overwrite_keys: true processors: - drop_fields: fields: ["agent.ephemeral_id","agent.hostname","agent.id","agent.type","agent.version","ecs.version","input.type","log.offset","log.file.path"] setup.template.enabled: false #禁用自动加载模板 setup.template.overwrite: true #覆盖已存在的模板 #setup.template.settings: # index.number_of_shards: 3 # index.number_of_replicas: 1 #自定义index名称时,需要指定以下三项模板配置: setup.ilm.enabled: false setup.template.name: "zepeto-nginx" setup.template.pattern: "zepeto-nginx-*" output.elasticsearch: hosts: ["172.17.213.59:9200", "172.17.213.60:9200", "172.17.213.61:9200"] index: "zepeto-nginx-access.%{+YYYY-MM}" max_procs: 1 #logging.level: warning logging.level: info logging.to_files: true logging.files: path: /var/log/filebeat name: filebeat keepfiles: 7 permissions: 0644
Filebeat ---> ES (多个index)
filebeat.inputs: - type: log enabled: true paths: - /home/www-data/logs/prod-zepeto-access.log json.keys_under_root: true json.overwrite_keys: true fields: type: prod-zepeto - type: log enabled: true paths: - /home/www-data/logs/test-zepeto-access.log json.keys_under_root: true json.overwrite_keys: true fields: type: test-zepeto processors: - drop_fields: fields: ["agent.ephemeral_id","agent.hostname","agent.id","agent.type","agent.version","ecs.version","input.type","log.offset","log.file.path"] setup.template.enabled: false #禁用自动加载模板 setup.template.overwrite: true #覆盖已存在的模板 setup.ilm.enabled: false #禁用索引生命周期管理ilm功能(开启时索引名称只能为filebeat-*,所以禁用后即可使用自定义的索引名称) output.elasticsearch: hosts: ["172.17.213.59:9200", "172.17.213.60:9200", "172.17.213.61:9200"] indices: - index: "prod-zepeto-nginx-access.%{+YYYY-MM}" when.equals: fields.type: "prod-zepeto" - index: "test-zepeto-nginx-access.%{+YYYY-MM}" when.equals: fields.type: "test-zepeto" max_procs: 1 logging.level: info logging.to_files: true logging.files: path: /var/log/filebeat name: filebeat keepfiles: 7 permissions: 0644
RPM安装方式使用时遇到的问题
在使用RPM包进行安装时出现日志无法输出到/var/log/filebeat文件下,经调试后发现,标红部按如下修改/lib/systemd/system/filbeat.service后,可正常打印日志
[Unit] Description=Filebeat sends log files to Logstash or directly to Elasticsearch. Documentation=https://www.elastic.co/products/beats/filebeat Wants=network-online.target After=network-online.target [Service] Type=simple Environment="BEAT_LOG_OPTS=-e" Environment="BEAT_CONFIG_OPTS=-c /etc/filebeat/filebeat.yml" Environment="BEAT_PATH_OPTS=-path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -path.logs /var/log/filebeat" ExecStart=/usr/bin/filebeat Restart=always [Install] WantedBy=multi-user.target
# cat /usr/bin/filebeat
#!/usr/bin/env bash # Script to run Filebeat in foreground with the same path settings that # the init script / systemd unit file would do. exec /usr/share/filebeat/bin/filebeat -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -path.logs /var/log/filebeat "$@"
可见,/usr/bin/filebeat文件启动时亦可加载环境配置