1,使用主键索引进行查询,修改不是运用主键查询的语句,(B+tree平衡二叉树 主键索引存储了数据行)二分查找法
2,建立适当的联合索引(将经常查询的数据建立联合索引,考虑顺序,如果要查询的数据在联合索引中找到,不会触发二次查询,利用覆盖索引的机制)
3,聚簇索引 和 非聚簇索引,聚簇索引出现在非主键索引建立的地方,如果利用非主键进行查询,会触发二次查询,非聚簇索引不会触发二次查询,数据就在节点上
4,用时间换空间,在数据库建立时增加冗余字段(一般在没有反向查找的地方)
基础分析如下:
索引设计优化:
-
-
优点
-
增加查询速度
-
索引不仅可以提高精确查询的速度, 还可以提高排序和分组的效率
-
-
缺点
-
增加数据库的存储空间
-
减慢增删改速度(索引需要随之改变)
-
-
创建索引
create table t_user( id int not null, mobile char(10) not null, key (mobile) # 设置索引 ) alter table t_user add nickname varchar(20); alter table t_user add key (nickname);
查看索引: show keys from t_user;
查看查询是否使用是索引:explain select * from t_user where nickname = 'zs';
二,索引分类:
-
-
创建主键后自动生成
-
-
唯一索引
-
设置唯一约束后自动生成
-
-
外键索引
-
设置外键约束后自动生成
-
-
普通索引 index
-
不要用可空列作为索引, 易出错
-
适合的字段
-
经常出现在
Where子句中的字段,特别是大表的字段,应该建立索引; -
经常与其他表进行连接的表,在
连接字段上应该建立索引; -
索引应该建在选择性高(取值范围广)的字段上;
-
频繁进行数据操作的表,不要建立太多的索引;
-
-
场景
-
自定义的外键字段(逻辑外键) -
-
-
mysql的索引存储结构为B+tree结构,平衡二叉树
-
叶子节点上存放的是
数据行 -
InnoDB引擎的主键索引使用这种存储方式
-
二级/辅助索引(所有非主键索引)的叶子节点上存放的是主键值, 所以二级索引需要进行
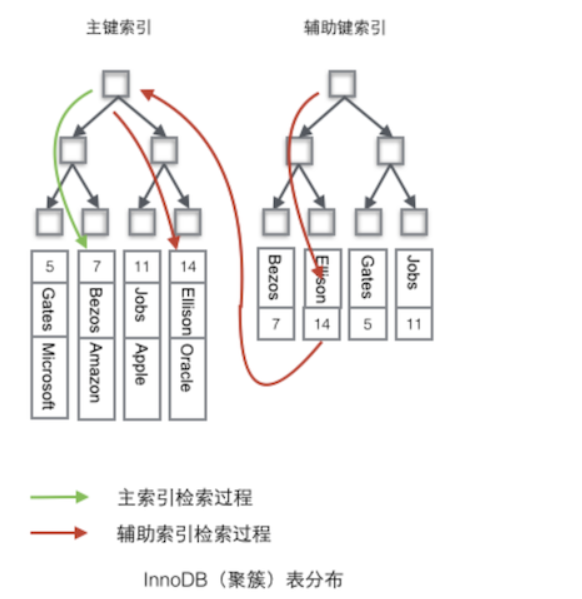
非聚簇索引: 在叶子节点上存储的是数据行的物理地址, 数据行和索引存储在不同的结构中

-
联合索引必须符合
最左原则, 否则无效-
where mobile /where mobile and type会使用索引
-
where type 不会使用索引
-
create table t_user( id int not null, # 非空约束 mobile char(10) not null, type tinyint default 0, key k_mobile_type (mobile, type) # 设置联合索引 ) key testindex (type, 姓, 名) select 姓, 名 from t_user where type = 1;

-
如果一个索引包含(或者说覆盖)所有需要查询的字段的值, 称为"覆盖索引"
-
如果查询触发了覆盖索引, 将
直接从索引中提取出数据, 而不会再去查询数据行 -
合理利用覆盖索引机制, 极大的提高性能
-
应用场景
-
优化二次查询
-
提高or运算的查询速度
create table t_user( id int auto_increment primary key, name varchar(20) not null, age int default 0, key test_index (name, age) # 设置联合索引 ) select age from t_user where name = 'zs'; # 使用覆盖索引
-
InnoDB的主键为什么选择自增
-
数据和主键索引是绑定在一起的, 主键自增则会让数据顺序添加到B+Tree中, 不会因移动数据而影响插入速度
-
-
复合/联合主键
-
将多个业务键联合定义为主键
-
优点
-
节省空间
-
-
缺点
-
不是自增, 性能差
-
无法作为其他表的外键
-
-
尽量不要用
-
6. 三范式和反范式设计 (重点)
-
规则
-
第一范式: 字段具有原子性, 不可拆分
-
第二范式: 依赖于全部主键, 而非部分主键
-
主要针对复合主键,一般都会遵守
-
比如某人的成绩 由班级+姓名决定, 成绩完全依赖于班级+姓名, 但是班主任姓名只依赖于班级, 不依赖学生姓名, 则不能在该表中
-
-
第三范式: 只依赖于主键, 非主键字段互不依赖
-
-
目的
-
减少冗余字段/重复的数据
-
-
回复数/评论数/点赞数 都可以通过聚合查询来获取
select count(*) from t_comment group by news_id -
如果单独定义字段来记录, 该字段就称为冗余字段
-
这种设计称为 反范式设计
-
通过加入冗余字段/重复数据 来提高数据库的查询速度
-
减少关联查询
-
用空间换取时间
-
-
范式是武功招式, 如何运用全看自己
7. 数据库引擎
-
实现数据存储的不同解决方案
-
InnoDB mysql5.5开始 默认
-
支持事务(回滚/提交/ACID特性/多版本并发控制等)-
数据恢复可使用事务日志(undo/redo log), 恢复速度快
-
-
支持行级锁&表级锁-
并发访问时效率高
-
-
支持外键约束
-
插入/更新/主键查询快
-
需要内存和硬盘多
-
常规推荐使用
-
-
MyISAM
-
不支持事务
-
只支持表级锁
-
不支持外键约束
-
批量插入/查询/count( )速度快 -
简单,
适合小型项目/以批量插入和查询为主的系统(内部管理系统)
-
-
系统公告表选择了MyISAM
-
因为基本不会修改, 不存在大量并发写操作, 也就不需要行级锁提供并发能力
-
和其他表没有关联, 不需要事务提供原子性等支持
-
-
查询多, MyISAM会更快
8. 字符集
-
字符集问题
-
utf-8如果保存数据中包含表情符号会崩溃
-
utf-8编码最大字符长度为3字节, 而unicode中大编码实现的表情符号(emoji)为4字节
-
编码方式需要设置为utf8mb4
-
-
sql注释
COMMENT xxx -
show create table xx;/show full columns from test;可以显示出注释