对于以下dataframe执行dataframe.groupby(['name', 'course']).apply(lambda x: test(x)) 操作
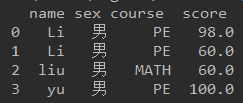
其中test(x)函数为:
def test(x): print(x)
那么打印结果为:
可以发现,groupby()后的第一个结果被打印了两次。
对于这种情况,Pandas官方文档的解释是:

什么意思呢?就是说,apply在第一列/行上调用func两次,以决定是否可以进行某些优化。
而在pandas==0.18.1以及最新的pandas==0.23.4中进行尝试后发现,这个情况都存在。
在某些情境,例如对groupby()后的dataframe进行apply()批处理,为了避免重复,我们并不想让第一个结果打印出两次。
方法一:
如果能对apply()后第一次出现的dataframe跳过不处理就好了。
这里采用的方法是设置标识符,通过判断标识符状态决定是否跳过。代码如下:
global flag flag = False def test(x): global flag if flag == False: flag = True return print(x)
测试结果为:

可以发现重复的dataframe已经跳过不再打印,问题顺利地解决~
方法二:
在上面的分析中,已经找了问题的原因是因为apply()方法的引入。那么,有没有可以代替apply()方法呢?这里可以采用filter()方法,即用groupby().filter() 代替groupby().apply()。具体代码如下:
def test(x): print(x) df.groupby(['name', 'course']).filter(lambda x: test(x))
打印出测试结果,也ok~
