1. 预备知识
1.1 KS-检验
KS-检验与t-检验等方法不同的是KS检验不需要知道数据的分布情况,可以算是一种非参数检验方法。当然这样方便的代价就是当检验的数据分布符合特定的分布时,KS-检验的灵敏度没有相应的检验来的高。在样本量比较小的时候,KS-检验作为非参数检验,在分析两组数据之间是否存在异常时相当常用。
PS:t-检验的假设是检验的数据满足正态分布,否则对于小样本不满足正态分布的数据用t-检验就会造成较大的偏差,虽然对于大样本不满足正态分布的数据而言t-检验还是相当精确有效的手段。
KS检验使用的是两条累积分布曲线之间的最大垂直差作为D值(statistic D)作为描述两组数据之间的差异。在此图中这个D值出现在x=1附近,而D值为0.45(0.65-0.25)。
1.2 CDF 累积分布函数
累积分布函数(Cumulative Distribution Function),又叫分布函数,是概率密度函数的积分,能完整描述一个实随机变量X的概率分布。一般以大写CDF标记,,与概率密度函数probability density function(小写pdf)相对。
1.3 KS-检验D值计算
对以下两组数据做KS-检验:
a = [1.26, 0.34, 0.70, 1.75, 50.57, 1.55, 0.08, 0.42, 0.50, 3.20, 0.15, 0.49, 0.95, 0.24, 1.37, 0.17, 6.98, 0.10, 0.94, 0.38]
b = [2.37, 2.16, 14.82, 1.73, 41.04, 0.23, 1.32, 2.91, 39.41, 0.11, 27.44, 4.51, 0.51, 4.50, 0.18, 14.68, 4.66, 1.30, 2.06, 1.19]
1.3.1 对a组数据做统计描述
Mean = 3.61
Median = 0.60
High = 50.6 Low = 0.08
Standard Deviation = 11.2
可以发现这组数据并不符合正态分布, 否则会有大约有15%的数据值小于-7.59(均值-标准差(3.61-11.2))。而数据中显然没有小于0的数值,所以该组数据不符合正态分布。
1.3.2 观察数据的累积分段函数(Cumulative Fraction Function)
注:google为Cumulative Distribution Function
对a组数据从小到大进行排序:
sorted a=[0.08, 0.10, 0.15, 0.17, 0.24, 0.34, 0.38, 0.42, 0.49, 0.50, 0.70, 0.94, 0.95, 1.26, 1.37, 1.55, 1.75, 3.20, 6.98, 50.57]。
观察发现前10%的数据(2/20)小于0.15,前85%(17/20)的数据小于3。所以,对任何数x来说,其累积分段就是所有比x小的数在数据集中所占的比例。
对于数0.15,其累积分段为10%,对于数3,其累积分段为85%......求出a组数据中所有数的累积分段值后绘制累积分段图如下所示:
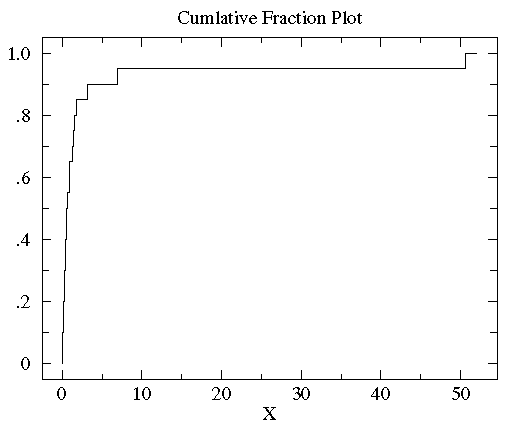
可以看到大多数数据都分布在左侧(数据值比较小),这就是非正态分布的标志(注:正态分布两边小中间大)。为了更好的观测数据在x轴上的分布,可以对x轴的坐标进行非等分的划分。在数据都为正的时候有一个很好的方法就是对x轴进行log转换。
下图就是对x轴的坐标做log转换以后的图:

把b组数据按上述方法做同样处理,结果如下,其中实线表示a组数据的累积分段,虚线表示b组数据的累积分段:
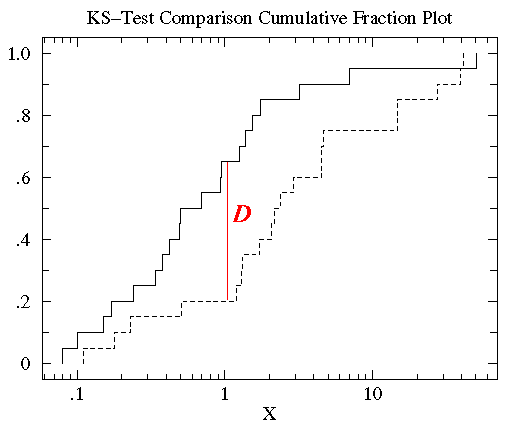
可以发现a和b的数据分布范围大致相同(0.1 - 50)。但是对于大部分x值,在a组数据集中比x小的数据所占的比例比b组中的要高,也就是说达到相同累积比例的值在b组中比a组中要高。
1.3.3 计算D值
KS-检验使用的是两条累积分布曲线之间的最大垂直差作为D值(statistic D)来描述两组数据之间的差异。在此图中,D值出现在x=1附近,且D值为0.45(0.65-0.25)。
2. 为什么要做特征监控
举一个例子:
眼看着双十一快要到了,公司要做大促,实现留存拉新的目标,但面临一个棘手的问题:总是有专业羊毛党来薅羊毛。BOSS想到了公司新招了个算法调包侠小王,于是找到了他,让他做一个识别羊毛党的模型。
小王开始了工作,构造训练集、选模型、调参、测试...
训练集的数据如下所示:
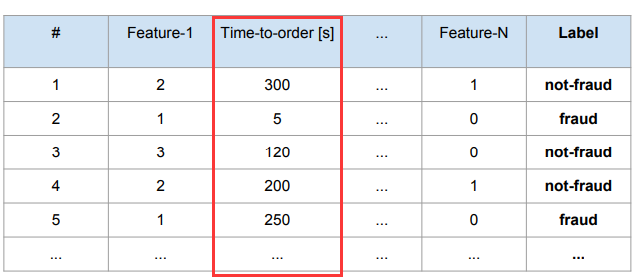
可以观察到,Time-to-order [s] 字段的分布是这个样子的:

模型训练完成后,BOSS在测试集上一看:”效果挺不错的嘛,赶紧上线!对了小王,你呀还得再加一个新功能,监控一下CPU、内存、延迟的情况。“.......”好的!“
过了两周....
BOSS找到了小王:”你这咋回事,我们这么多客户,怎么一个羊毛党都发现不了???“

小王也纳闷:线下效果很好啊,这是为什么?

赶紧去查看历史日志信息,迅速发现了问题:
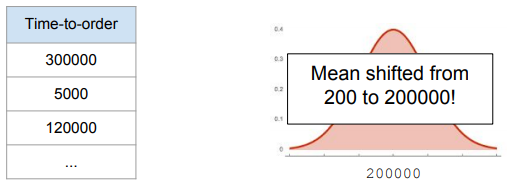
原来这个Time-to-order [s] 特征是以毫秒为单位feed进模型的(不是以秒为单位)!所以导致所有的预测都是错误的!
虽然很快找到了原因,但两周的时间仍然产生了诸多问题:
- 公司损失了很多钱。
- 开发人员没有及时发现此问题。
- 开发人员本可以及时发现它并提供一个修复。
由于我们不能忽视预测质量的下降,所以我们需要持续监控已经部署的机器学习模型。当我们在某些领域开展业务时,往往面临的一个挑战是,我们模型的预测结果具有迟滞性。也就是说当我们注意到这个问题时,问题已经发生了。因此,需要监控实时流量中特征分布与模型评估测试集中特征分布之间的相似性,从而能够立即发现并评估模型的输入特征是否发生了重大变化。
3. 监控方案的设计
3.1 确保输入特征的分布(总是)与训练时特征的分布相同
这里是通过KS-检验实现。
3.2 数据聚合的窗口大小的设计

数据聚合的窗口设置较小,优点是可以快速检测出是否有异常数据(特征),缺点是受短期季节性或短期活动等波动因素的影响较大。
数据聚合的窗口设置较大,优点是受短期的季节性等波动因素的影响较小,缺点是对异常数据的检测缓慢。
3.3 已监控特征的分析频次设计
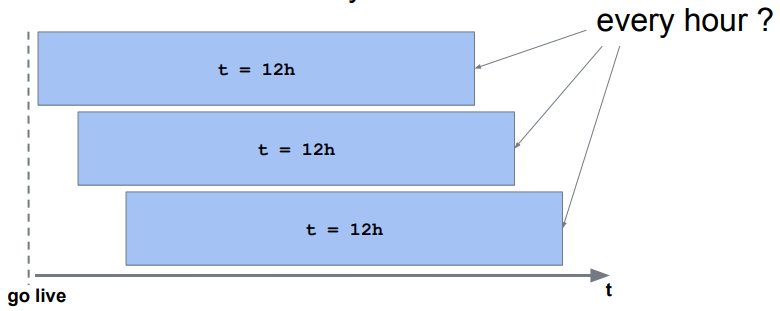

高频次分析的优点是可以更快地发现异常,缺点是计算复杂性高,成本高
低频次分析的优点是不复杂,成本低,缺点是异常检测缓慢。
3.4 监控界面设计
实际上,监控界面的设计和普通BI系统的区别不大。
在展示内容上,除了常见的模型CPU/GPU使用率、内存占用率、模型响应时长等,往往还会按模型分组、创建特征KS-检验直方图、时间段选择、异常特征展示、不同模型实时效果对比等信息。

4. 参考资料
[3] What’s your ML Test Score? A rubric for ML production systems
[4] Continuous Live Monitoring of Machine Learning Models with Delayed Label Feedback