上面介绍完dplyr中,几个主要的操作函数后,我们再进一步了解dplyr中那些函数可能我们会经常要用到。
这里主要根据dplyr包作者的书籍目录来把它列出来。
1、add_rownames 添加行名称,把数据转换成列。
add_rownames(df, var = "rowname")
下面来看个具体的例子
head(mtcars)

add_rownames(mtcars,var="bl")

已经把原来的行数据转成列数据了。
2、between()函数可以用于选取数据范围
between(x, left, right)
参数left,right表示数据左边和右边范围。
a<-10:30 between(a,5,15)

可以看到between函数返回结果是逻辑值,即那些数据满足条件,标记为TRUE
a[between(a,5,15)]

通过加中括号的形式,把正确结果显示出来。
3、bind()函数用于合并数据
bind_rows(..., .id = NULL)
bind_cols(...)
combine(...)
存在三种形式的合并数据。
head(mtcars,15)
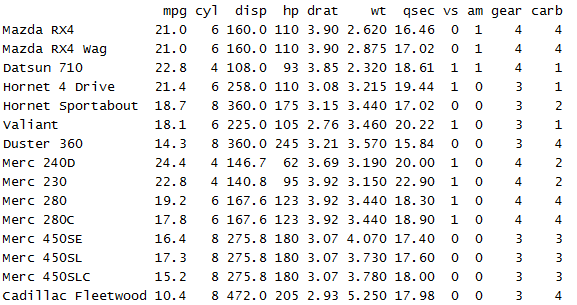
a <- mtcars[1:3, ] b <- mtcars[11:13, ]
bind_rows(a,b)

可以看到上面1-3行和11-13行数据被合并成一个新的数据集。
bind_rows(list(a, b), .id = "id")

为了区别数据是分别来至于两个其他数据库,可以用id进行区别。
bind_rows(list(aa = a, bb = b), .id = "id")

可以对id用其他名称进行标识。
aa<-data.frame(x=1:5,y=c("a","b","c","d","e"))
bb<-data.frame(x=11:15)
bind_rows(aa,bb)

可以看到数据框如果存在相同变量,则bb的数据是接着aa的数据继续向下填充,否则用NA值进行填充。
bind_cols(a,b)

可以看到,进行列合并时,是直接在第一组数据后面列出第二组数据。
combine(aa,bb)

combine函数是直接把每个数据的每个变量直接抽离,然后以数组的形式呈现。
相对而言,以上三个合并函数中,bind_rows()会用的比较多。