接下来我们继续了解一些dplyr中的常用函数。
1、ranking
以下各个函数可以实现对数据进行不同的排序
row_number(x)
ntile(x, n)
min_rank(x)
dense_rank(x)
percent_rank(x)
cume_dist(x)
具体的看些例子。
x <- c(5, 1, 3, 2, 2, NA) x
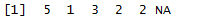
row_number(x)

row_number是对数据大小进行编号排序,遇到重复值,排序继续加1,缺失值不计入
min_rank(x)

min_rank是对数据大小进行编号排序,遇到重复值,排序相同,但每个值都占一个位置,缺失值不计入
dense_rank(x)

dense_rank是对数据大小进行编号排序,遇到重复值,排序相同,所有重复值只占一个位置,缺失值不计入
percent_rank(x)

percent_rank是对数据进行百分比排序,每个值表示数据所在总体排名中的百分比位置
cume_dist(x)
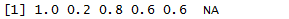
cume_dist是把所有点集中反应在0-1之间的一个数值,每个数值表示数据所在位置,跟percent_rank有点类似
ntile(x, 2)

ntile则可以指定数据排序的个数,然后循环这些排序数据对数据进行排序。
2、recode()
recode(.x, ..., .default = NULL, .missing = NULL)
数据替换函数,在数据替换中使用非常灵活。
x <- sample(c("a", "b", "c"), 10, replace = TRUE)
x
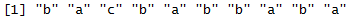
recode(x, a = "wo")

recode(x, a = "wo", .default = NA_character_)

x<-sample(1:5,10,rep=T) x

recode(x, `2` = 20L, `4` = 40L)
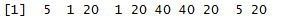
recode(x, `2` = "b", `4` = "d")

recode(x, "a", "b")

recode(x, "a", "b", .default = "wo")

x <- c(1:4, NA) x

recode_factor(x, `1` = "z", `2` = "y", `3` = "x")

recode_factor(x, `1` = "z", `2` = "y", .default = "D", .missing = "M")

recode_factor(factor(letters[1:3]), b = "z", c = "y")
